مواقع DTC مقابل الأسواق في agentic commerce
دليل عملي لاستخدام الأسواق الإلكترونية مع بناء قناة DTC تحفظ بيانات المنتج وعلاقة العميل والمحتوى والقياس.
اقرأ المزيد
شركات التقنية الكبرى دمجت بالفعل البرمجة بالذكاء الاصطناعي في سير عملها. لكن لمعظم الفرق، الخطوة الأولى ليست كتابة أكواد أكثر وبسرعة، بل الحصول على صورة واضحة للمشروع.
لقد تجاوزت البرمجة بالذكاء الاصطناعي مسألة ما إذا كان الذكاء الاصطناعي يمكنه كتابة الكود.
منذ وقت ليس ببعيد، كانت معظم النقاشات حول البرمجة بالذكاء الاصطناعي لا تزال تدور حول العروض التوضيحية: هل يمكنه إنشاء صفحة؟ هل يمكنه كتابة دالة؟ هل يمكنه إصلاح خطأ؟ هذا السؤال لم يعد الأكثر إثارة للاهتمام.
في عام 2026، قال سوندار بيتشاي، الرئيس التنفيذي لشركة Google، إن 75% من الكود الجديد في Google يتم الآن إنشاؤه بواسطة الذكاء الاصطناعي ومراجعته بواسطة المهندسين. كما قال ساتيا ناديلا، الرئيس التنفيذي لشركة Microsoft، إن حوالي 20%–30% من الكود في مستودعات Microsoft يتم إنشاؤه بواسطة الذكاء الاصطناعي. يُظهر تقرير GitHub Octoverse 2025 مدى سرعة انخراط المطورين الجدد في سير العمل المدعوم بالذكاء الاصطناعي: 80% من مطوري GitHub الجدد يستخدمون Copilot خلال أسبوعهم الأول.
الاتجاه واضح بالفعل: البرمجة بالذكاء الاصطناعي تدخل في تطوير البرمجيات الحقيقي.
لكن حقيقة أخرى واضحة بنفس القدر: المطورون لا يثقون بها تمامًا بعد.
وجد استطلاع Stack Overflow Developer Survey 2025 أن 46% من المطورين لا يثقون في دقة أدوات الذكاء الاصطناعي، مقارنة بـ 33% يثقون بها. وجدت تجربة METR العشوائية المضبوطة لعام 2025 مع مطوري مفتوح المصدر ذوي خبرة أنه، في قواعد الأكواد الناضجة، أدى استخدام أدوات الذكاء الاصطناعي الحالية في ذلك الوقت إلى زيادة وقت إنجاز المهمة بنسبة 19%. كما يصف تقرير DORA لعام 2025 حول تطوير البرمجيات بمساعدة الذكاء الاصطناعي الذكاء الاصطناعي كمضخم: فهو يضخم نقاط القوة التي تمتلكها المؤسسة بالفعل، ويمكنه أيضًا تضخيم المشكلات القائمة.
هذا يخلق توترًا حقيقيًا جدًا.
شركات التكنولوجيا الكبرى تستخدم البرمجة بالذكاء الاصطناعي. المطورون يستخدمونها أيضًا. لكن الأشخاص المسؤولين عن الأنظمة الحقيقية ما زالوا لا يثقون ببساطة في رسالة "يقول الذكاء الاصطناعي إنها انتهت".
السبب سهل الفهم.
يمكن للذكاء الاصطناعي إنتاج ميزة بسرعة تبدو صحيحة بشكل منعزل. الصفحة تُفتح. الزر يعمل. API يستجيب. واجهة المستخدم تبدو جيدة. ولكن بمجرد دمج التغيير مرة أخرى في منتج حقيقي، تتعطل وحدة أخرى، أو يتم تجاوز مسار قديم، أو تصبح اصطلاحات المكونات غير متسقة، أو يختفي التراجع اللغوي، أو يتم استبدال بيانات SEO الوصفية، أو تتوقف حالة حافة لم يذكرها أحد عن العمل.
هذا الشعور مألوف: التغيير يبدو جيدًا بحد ذاته، لكن هناك شيئًا ما يبدو خطأ بمجرد وضعه داخل النظام الكامل.
لذا فإن السؤال الحقيقي ليس ما إذا كان الذكاء الاصطناعي يمكنه كتابة الكود.
السؤال الأكثر أهمية هو:
هل الذكاء الاصطناعي يُكمل مهمة، أم أنه يفهم النظام؟
إذا كان يفهم المهمة فقط، يمكن أن يكون صحيحًا محليًا وخاطئًا نظاميًا. إذا كان يفهم النظام أولاً، فإن البرمجة بالذكاء الاصطناعي لديها فرصة أفضل بكثير لتصبح إنتاجية حقيقية.
---
عندما يبدأ فريق في استخدام البرمجة بالذكاء الاصطناعي لأول مرة، فإن الحركة الطبيعية هي رمي المهام عليه.
"أضف فلتر هنا." "حدّث هذه الصفحة." "أعد هيكلة هذا المكون." "اربط نقطة دخول للدفع." "أضف حقل متعدد اللغات."
عادةً ما يستجيب الذكاء الاصطناعي بسرعة. المشكلة هي أنه قد يُكمل المهمة الحرفية فقط.
تطلب منه إضافة فلتر، فيضيف فلتر. تطلب منه تحديث صفحة، فيحدّث الصفحة. تطلب منه إعادة هيكلة مكون، فيعيد هيكلة المكون.
لكنه قد لا يعرف لماذا توجد تلك الصفحة، أو أين يُعاد استخدام المكون، أو ما إذا كان الحقل يُستهلك بواسطة واجهة المتجر، أو ما إذا كانت نقطة دخول الدفع مرتبطة بحالات الطلب، أو الاسترجاعات، أو المبالغ المستردة، أو معالجة الأخطاء.
لهذا السبب تهم صورة المشروع.
صورة المشروع ليست سطرًا مثل "هذا منتج SaaS" أو "هذا موقع تجارة إلكترونية".
هذه خلفية، وليس فهمًا للنظام.
يجب أن تجيب صورة المشروع المفيدة على خمسة أسئلة على الأقل.
أولاً، الهدف.
ما الذي يحاول هذا المنتج تحقيقه؟ حركة البحث، التحويل، إدارة المنتجات، التقاط العملاء المحتملين، معالجة المعاملات، أو الكفاءة التشغيلية؟ نفس مهمة "بناء صفحة" تعني أشياء مختلفة جدًا اعتمادًا على الهدف. إذا كان الهدف هو SEO، فإن الصفحة تحتاج إلى بيانات وصفية، ومحتوى منظم، وروابط داخلية، وقابلية للزحف. إذا كان الهدف هو كفاءة الواجهة الخلفية، فإنها تحتاج إلى نماذج، ومرشحات، وإجراءات جماعية، ومعالجة أخطاء. إذا كان الهدف هو التحويل، فلا يمكن للصفحة أن تبدو جيدة فقط؛ بل يجب أن تدعم الثقة، والدفع، والطلبات، وتوقعات ما بعد البيع.
ثانيًا، الكائنات.
ما هي الكائنات الأساسية في النظام، وكيف ترتبط ببعضها البعض؟ كلمات مثل مستخدم، منتج، طلب، صفحة، محتوى، وموقع يمكن أن تعني أشياء مختلفة جدًا عبر أنظمة مختلفة. إذا كانت الكائنات غير واضحة، يمكن للذكاء الاصطناعي بسهولة أن يخلط بين أشياء تبدو متشابهة تقنيًا لكنها مختلفة في العمل.
ثالثًا، القيود.
ما الذي لا ينبغي تغييره بشكل عشوائي؟ مكتبات المكونات الحالية، أنماط التوجيه، هيكل i18n، نماذج الأذونات، تدفقات النشر، تدفقات الدفع، قيود الترحيل، صوت العلامة التجارية، واستراتيجية SEO كلها قيود. القيود ليست موجودة لتحديد الذكاء الاصطناعي. إنها تساعد الذكاء الاصطناعي على تجنب المسار الخطأ.
رابعًا، سطح التأثير.
عندما يتغير شيء ما، أين يمكن أن ينتقل التأثير؟ هل يؤثر فقط على صفحة واحدة، أم يمس نماذج البيانات، APIs، عرض واجهة المتجر، i18n، التخزين المؤقت، البحث، الأذونات، أو التحليلات؟ كلما كان سطح التأثير أوضح، قل احتمال أن "هذه الميزة تعمل، لكن شيئًا آخر تعطل".
خامسًا، الاتجاه المستقبلي.
هل هذا إصلاح لمرة واحدة، أم سيصبح قدرة منتجية؟ إذا كان سيُعاد استخدامه، فإن الترميز الثابت محفوف بالمخاطر. إذا كان إصلاحًا قصير الأجل، فقد يكون الإفراط في التجريد غير ضروري.
هذه الأسئلة الخمسة معًا تشكل الصورة التي يحتاجها الذكاء الاصطناعي.
بدون صورة، يعالج الذكاء الاصطناعي المهمة كشيء منعزل. بالصورة، يمكن للذكاء الاصطناعي أن يحكم على المهمة داخل النظام.
قاعدة عملية: صورة المشروع ليست مقدمة للمشروع. إنها الهدف، الكائنات، القيود، سطح التأثير، والاتجاه المستقبلي. بدونها، لا تتعجل في مطالبة الذكاء الاصطناعي بإجراء تغييرات رئيسية في الكود.
---
غالبًا ما تتحول مناقشات المجموعة التقنية إلى جدالات حول ما هو أكثر حداثة.
React أم Vue؟ Next.js أم Remix؟ Node.js أم Go؟ PostgreSQL أم MySQL؟ هل يجب استخدام أحدث إطار يتحدث عنه الجميع؟
هذه الأسئلة مهمة، لكن لا يمكن الإجابة عليها خارج صورة المشروع.
موقع محتوى، ونظام معاملات، وأداة إدارة داخلية، ومنصة لتوليد العملاء المحتملين B2B، ومنصة سير عمل بالذكاء الاصطناعي — لا تحتاج جميعها إلى نفس الإمكانيات. ما يحتاج المنتج إلى دعمه يجب أن يقرر نموذج البيانات، وهيكل التوجيه، ونموذج الأذونات، واستراتيجية العرض، وقدرة SEO، ونظام الدفع، ونظام المكونات، ومسار النشر.
في عصر البرمجة بالذكاء الاصطناعي، أصبح للمجموعة التقنية أيضًا بُعد جديد:
هل يمكن للذكاء الاصطناعي فهمها بسهولة، وهل يمكن للبشر التحقق منها بسهولة؟
النماذج لا تفهم قاعدة الكود من العدم. فهمها لمجموعة تقنية يعتمد على مقدار الكود الحقيقي، والعمل مفتوح المصدر، والتوثيق، ونقاشات الأخطاء، والممارسات الهندسية الموجودة في هذا النظام البيئي. كلما زادت الأمثلة الموثوقة التي رآها الذكاء الاصطناعي، قل احتمال تخمينه من فراغ.
لهذا السبب تفضل العديد من منتجات الويب، وأنظمة الإدارة، وأنظمة المحتوى، والمنتجات الموجهة للمعاملات في كثير من الأحيان مجموعات ناضجة مثل TypeScript، React / Next.js، Node.js، PostgreSQL، أنظمة دفع ناضجة، وأنظمة مكونات واجهة مستخدم مستقرة.
هذا لا يعني أن هذه التقنيات هي دائمًا الخيار الأفضل.
هذا يعني أنها أسهل للذكاء الاصطناعي لفهمها، وأسهل للبشر للتحقق منها.
يُظهر GitHub Octoverse 2025 أن TypeScript أصبحت اللغة الأكثر استخدامًا على GitHub. وجدت State of JavaScript 2024 أيضًا أن 67% من المشاركين يكتبون TypeScript أكثر من JavaScript. هذا مهم للبرمجة بالذكاء الاصطناعي لأنه مع كتابة الذكاء الاصطناعي لمزيد من الكود، تحتاج الفرق إلى أنظمة أنواع أقوى، وردود فعل IDE، وفحوصات ثابتة، وأنماط هندسية متسقة لتقييد المخرجات.
TypeScript ليست فقط حول أمان الأنواع.
في البرمجة بالذكاء الاصطناعي، إنها تعطي النموذج إشارات هيكلية:
ما المعلمات التي تتوقعها الدالة. ما الخصائص التي يستقبلها المكون. ما إذا كان الكائن يفتقد حقلاً. ما إذا كانت استجابة API تطابق الشكل المتوقع. ما إذا كان التغيير لا يزال يجتاز فحص الأنواع.
الأطر الناضجة، وأنظمة الدفع، وقواعد البيانات، وأنظمة واجهة المستخدم تلعب دورًا مشابهًا. إنها تقلل المساحة المتاحة للذكاء الاصطناعي للارتجال وتساعد كلًا من البشر والنماذج على اتباع أنماط مستقرة.
بالطبع، المجموعة الناضجة ليست دائمًا الإجابة.
إذا كانت صورة المشروع تتضمن بنية تحتية عالية التزامن، أو فيديو مباشر، أو شبكات حافة، أو معالجة عميقة للبيانات، فيجب الحكم على المجموعة التقنية بشكل مختلف. ملاءمة الذكاء الاصطناعي ليست المعيار الوحيد. ملاءمة العمل لا تزال تأتي أولاً.
قاعدة عملية: استخدم صورة المشروع لتقرير ما يحتاجه العمل، ثم استخدم ملاءمة الذكاء الاصطناعي للحكم على ما إذا كانت المجموعة سهلة الفهم والتحقق والصيانة. مجموعة البرمجة بالذكاء الاصطناعي الجيدة هي ملائمة للعمل، ومشاهدة على نطاق واسع من قبل النماذج، وقابلة للتحقق البشري، ومقيدة بالأنواع، ومدعومة بأنماط مجتمعية قوية.
إذا كنت تقييم مجموعة تجارة إلكترونية أو منشئ مواقع، قد ترغب أيضًا في قراءة دراسة الحالة هذه: "الضرائب الخفية" للمنصة والتكلفة الحقيقية للمجموعة التقنية المتضخمة.
---
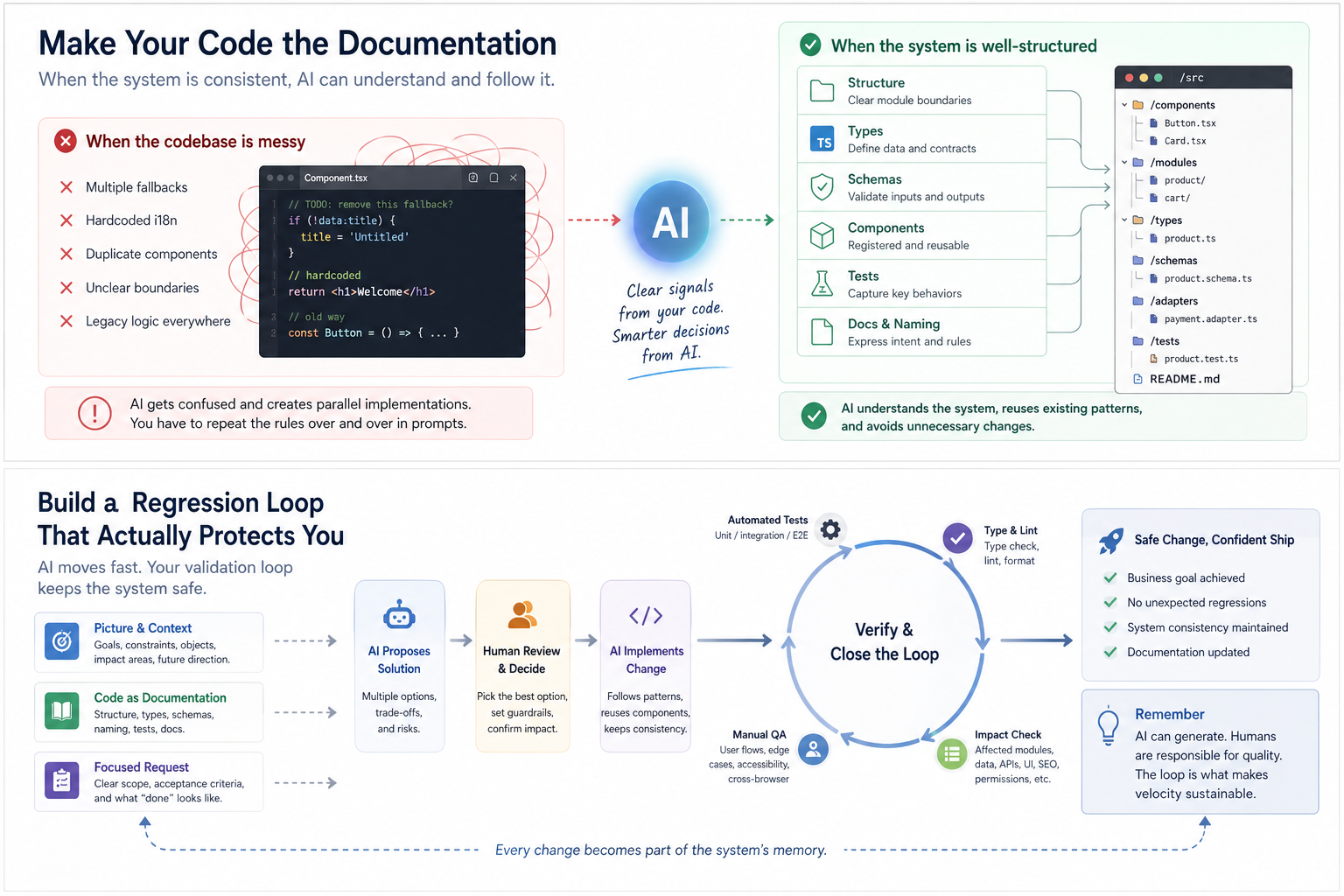
مع نمو المشروع، فإن الجزء الأصعب في البرمجة بالذكاء الاصطناعي ليس دائمًا وجود كود كثير جدًا. غالبًا ما يكون أن الكود مليء بالضوضاء.
مشهد شائع يبدو هكذا: تطلب من الذكاء الاصطناعي تغيير ميزة. يقرأ العديد من الملفات ويحاول بوضوح بجد، لكنه لا يزال ينشئ تطبيقًا موازيًا.
يتجاهل المكون الموجود ويكتب مكونًا جديدًا. يتجاوز API الموجود وينشئ مسارًا آخر. لا يعيد استخدام النوع الموجود ويُعرف نوعًا مشابهًا. يتجاوز هيكل i18n ويقوم بترميز ثابت للنص. لا يزيل المنطق القديم؛ بل يضيف ببساطة طبقة توافق أخرى.
عند تلك النقطة، لا تتسرع في إلقاء اللوم على النموذج.
انظر إلى المشروع نفسه. قد تكون المشكلة موجودة بالفعل: ثلاثة مسارات تراجع مختلفة، i18n ممتزج بنص مشفر ثابتًا، مكونات "مشتركة" تحتوي على منطق أعمال، تطبيقات قديمة لم تعد مستخدمة لكن لم تُحذف أبدًا. يدخل الذكاء الاصطناعي إلى تلك البيئة ويختار واحدًا من الإشارات المتضاربة التي تبدو معقولة له.
هذا يفسر لماذا يجب تكرار نفس التعليمات مرارًا وتكرارًا.
"لا تنشئ مكونًا جديدًا." "لا تقم بالترميز الثابت." "يجب أن تستخدم هذه الصفحة i18n." "يجب أن يستخدم هذا الزر المكون الموجود." "يجب أن تستخدم API نمط معالجة الأخطاء المشترك."
إذا كانت هذه القواعد يجب تكرارها في المطالبات في كل مرة، فإن المشكلة ليست ببساطة أن الذكاء الاصطناعي نسي. المشكلة هي أن هيكل المشروع لا يعبر عن القواعد بوضوح كافٍ.
تذكيرات المطالبات جيدة على المدى القصير.
لكن بمرور الوقت، الخطوة الأفضل هي طرح السؤال المعاكس: هل يحتوي الكود بالفعل على مسارات تراجع متضاربة؟ هل i18n غير متناسق؟ هل حدود مكتبة المكونات غير واضحة؟ هل نفس كائن العمل له أسماء متعددة؟ هل لا تزال التطبيقات القديمة موجودة، مما يجعل من المستحيل على الذكاء الاصطناعي معرفة ما هو المعيار الحالي؟
الحل الحقيقي ليس مطالبة أطول. بل هو جعل القواعد جزءًا من قاعدة الكود.
هيكل المجلدات يخبر الذكاء الاصطناعي بحدود الوحدات. الأنواع تخبر الذكاء الاصطناعي بعلاقات البيانات. المتكيفات تخبر الذكاء الاصطناعي بقواعد التحويل. المخططات تخبر الذكاء الاصطناعي بقيود الإدخال والإخراج. الاختبارات تخبر الذكاء الاصطناعي بالسلوكيات الرئيسية. التسمية تخبر الذكاء الاصطناعي بلغة العمل. التوثيق يخبر الذكاء الاصطناعي بقصد التصميم.
عند تلك النقطة، يصبح الكود نفسه توثيقًا.
عندما يبني الذكاء الاصطناعي الميزات، أو يعيد الهيكلة، أو يحقق في المشكلات، فإنه لا يحتاج إلى إعادة شرح كل شيء من الصفر بواسطة إنسان. يمكنه اتباع الهيكل، والعثور على الوحدات ذات الصلة، وفهم سطح التأثير، وتحديد التطبيقات المكررة، وتقليل خطر أن تكسر مهمة واحدة جزءًا آخر من المنتج.
قاعدة عملية: كلما احتجت إلى تكرار نفس القاعدة للذكاء الاصطناعي، تحقق أولاً مما إذا كانت قاعدة الكود تحتوي بالفعل على إشارات متضاربة. ثم انقل القاعدة إلى الهيكل، والأنواع، والتسمية، والمخططات، والمتكيفات، والاختبارات، أو التوثيق. وإلا، فأنت تستخدم المطالبات للحفاظ على اتساق النظام.
أخطر جزء في عمل الذكاء الاصطناعي أحادي المهمة ليس أن الذكاء الاصطناعي لا يمكنه كتابة الكود. بل هو أن الذكاء الاصطناعي يرى فقط ما هو أمامه.
الصفحة تُعرض، لكن SEO يتعطل. النموذج يُرسل، لكن الأذونات يتم تجاوزها. مدخل الدفع يُفتح، لكن حالة الطلب غير مكتملة. الحقل متعدد اللغات يُحفظ، لكن وقت تشغيل واجهة المتجر لا يستهلكه بشكل صحيح. المكون يبدو أفضل، لكنه لم يعد يتناسب مع نظام التصميم الحالي.
هذه ليست أخطاء نحوية.
إنها أخطاء سطح التأثير.
الجزء المؤلم هو أنها غالبًا لا تظهر على الفور. الصفحة تبدو جيدة اليوم. البناء ينجح. ملخص الذكاء الاصطناعي يبدو واثقًا. بعد بضعة أيام، نسخة لغة أخرى لها عنوان خاطئ، رابط قديم يعيد 404، إرسال نموذج لا يصل أبدًا إلى لوحة الإدارة، أو تدفق نشر غير مرتبط ظاهريًا يبدأ بالفشل.
لا يمكنك حل هذا بمجرد كتابة المهمة بمزيد من التفصيل.
المشكلة ليست أن الذكاء الاصطناعي لا يعرف ما تريده هذه المرة. المشكلة هي أنه لا يعرف ما قد يلمسه هذا التغيير.
عندما يكون للمشروع صورة، وتصبح قاعدة الكود تدريجيًا توثيقًا، يمكن للذكاء الاصطناعي أن يفعل أكثر من مجرد تعديل ملف. يمكنه البدء في اتباع هيكل النظام لفهم التبعيات في المنبع والمصب.
إذا طلبت منه تغيير وحدة محتوى، يمكنه تتبع الأنواع، والمتكيفات، ومستهلكي الصفحة، وبيانات SEO الوصفية، ومفاتيح i18n، ومسارات عرض واجهة المتجر.
إذا طلبت منه تغيير نموذج، يمكنه تتبع المخططات، APIs، التحقق، منطق الإرسال، الإشعارات، سجلات العملاء المحتملين، وتفاعلات الواجهة الأمامية.
إذا طلبت منه تعديل مكون، يمكنه تتبع تسجيل المكون، الصفحات المعاد استخدامها، رموز السمة، السلوك المتجاوب، وفحوصات إمكانية الوصول.
هذه هي قيمة الكود كتوثيق.
بدون صورة، يمكن للذكاء الاصطناعي فقط الإجابة على "كيف أنفذ هذا؟" بالصورة، يمكن للذكاء الاصطناعي أيضًا الإجابة على "ما الذي قد يتأثر بهذا؟"
قاعدة عملية: قبل أن تطلب من الذكاء الاصطناعي تنفيذ مهمة، لا تسأل فقط كيف سيفعلها. اطلب منه تتبع الوحدات، والمسارات، ونقاط التراجع التي قد تتأثر.
---
يجب أن تكون المهام واضحة.
لكن الوضوح لا يعني وصف كل زر وحقل ولون وتفاعل بتفصيل شديد.
تبدو بعض مهام البرمجة بالذكاء الاصطناعي سلسة في البداية: تكتب المتطلب بعناية، ويتبعه الذكاء الاصطناعي. لكن عندما ينتهي، تبدو حالة النظام أغرب. يبقى المنطق القديم، ويُضاف منطق جديد فوقه، الصفحة تعمل لكن إعادة الاستخدام تتعطل، يُضاف حقل لكن مصدر البيانات ووجهتها غير مكتملين.
هذه التجربة يمكن أن تكون مضللة. تجعلك تتساءل عما إذا كان المتطلب لم يكن مفصلاً بما يكفي.
غالبًا، الجزء المفقود ليس التفاصيل. إنه حالة النظام المستهدفة.
تخبر الذكاء الاصطناعي "أضف زرًا"، فيضيف زرًا. تخبر الذكاء الاصطناعي "أضف حقلاً"، فيضيف حقلاً. تخبر الذكاء الاصطناعي "اجعل هذا تأكيدًا من خطوتين"، فيغير التدفق.
لكنك لم تخبره ما الذي يجب أن يقل في النظام، وما الذي يجب أن يبقى، وما الذي يجب أن يتوحد بعد التغيير.
بعد إضافة منطق جديد، هل يجب حذف المنطق القديم؟ بعد إضافة حقل جديد، كيف يجب التعامل مع البيانات التاريخية؟ بعد إطلاق صفحة جديدة، هل يجب أن يظل المدخل القديم موجودًا؟ بعد إضافة مكون جديد، هل يجب دمج المكونات المكررة؟ بعد إدخال نهج i18n جديد، هل يجب إزالة النص المشفر القديم أيضًا؟
هذا هو الجزء الأسهل في تفويته في مهمة واحدة.
المتطلب الجيد لا يجب أن يخبر الذكاء الاصطناعي فقط بما يجب بناؤه. يجب أن يتضمن أيضًا ثلاثة أشياء.
أولاً، لماذا توجد المهمة.
هل هي لتجربة المستخدم، التحويل، الكفاءة التشغيلية، SEO، الاستقرار، أو الديون التقنية؟ إذا كان الهدف غير واضح، سيختار الذكاء الاصطناعي عادةً المسار الأكثر مباشرة، وليس بالضرورة المسار الأفضل.
ثانيًا، كيف يجب أن يبدو النظام بعد التغيير.
ما الذي يجب أن يتغير؟ ما الذي لا يجب أن يتغير؟ أي منطق قديم يجب إزالته؟ أي منطق توافق يجب أن يبقى؟
ثالثًا، كيفية معرفة أنه لم يكسر شيئًا.
أي الصفحات يجب فحصها؟ أي المسارات يجب تشغيلها؟ أي البيانات يجب فحصها؟ أي سلوك تراجع يجب تأكيده؟ بدون معايير القبول، يمكن للذكاء الاصطناعي بسهولة إنتاج شيء يبدو منتهيًا فقط.
لذا نعم، المهمة يمكن أن تكون مفصلة.
لكنها لا يمكن أن تحتوي على تفاصيل فقط. إنها تحتاج أيضًا إلى إخبار الذكاء الاصطناعي بالحالة التي يجب أن يكون عليها النظام بعد التغيير.
قاعدة عملية: تفاصيل المهمة المحلية مفيدة، لكن يجب أن تُقرن بلماذا توجد المهمة، وما هي حالة النظام المستهدفة، وكيفية التحقق من عدم كسر أي شيء.
---
مع ازدياد شعبية أدوات البرمجة بالذكاء الاصطناعي، يمتلئ الإنترنت بشكل طبيعي بالقواعد والمهارات والمطالبات وأفضل الممارسات.
هذا مفهوم. الجميع يريد جعل الذكاء الاصطناعي أكثر موثوقية.
لكن مشكلة شائعة هي أن الفرق تضيف كومة من القواعد الخارجية قبل أن تكون صورة المشروع واضحة أو أن هيكل الكود نظيف.
مهارات تطوير الواجهة الأمامية. مهارات تصميم واجهة المستخدم. أفضل ممارسات React. قواعد بنية SaaS. مطالبات كتابة SEO. قوائم الأمان. قواعد مراجعة الكود. تكوينات "الوضع الخارق" لـ Cursor أو Claude Code أو Codex.
هذه ليست عديمة الفائدة.
المشكلة هي أنها ليست من نفس نوع القاعدة.
النوع الأول هو قواعد أساسية خارجية.
فحوصات الأمان، مخاطر حقن SQL، مخاطر XSS، فحوصات الأذونات، تكرارية الدفع، معالجة أخطاء API، أساسيات إمكانية الوصول، أساسيات SEO، فحوصات الأداء، وتذكيرات تغطية الاختبارات تقع ضمن هذه الفئة.
هذه القواعد عالمية نسبيًا. عادةً ما تتعارض بشكل أقل مع نمط المشروع، والعديد منها يعتبر ضمانات أساسية. المهارات الخارجية وقوائم الفحص وأفضل الممارسات يمكن أن تكون قيمة هنا.
النوع الثاني هو قواعد أصلية للمشروع.
نمط الصفحة، استخدام المكونات، رموز السمة، عادات التباعد، مكونات النموذج، سلوك النوافذ المنبثقة، هيكل التوجيه، تنظيم i18n، طبقات العمل، تسمية البيانات، اصطلاحات المجلدات، وحدود إعادة استخدام المكونات — كلها تنتمي هنا.
لا ينبغي نسخ هذه القواعد من الإنترنت أولاً.
أهم مصدر لها ليس كيف يفعلها شخص آخر. بل هو كيف يعمل مشروعك بالفعل.
إنشاء صفحة الواجهة الأمامية هو مثال جيد.
تريد أن تبدو الصفحة أفضل، لذا تضيف مهارات خارجية للواجهة الأمامية: نمط SaaS حديث، إحساس متميز، زجاجية، تخطيط بطاقة، حركة، تسلسل هرمي بصري قوي، أفضل ممارسات الصفحات المقصودة.
كل من هذه قد يكون معقولاً بحد ذاته.
لكن إذا كان المشروع لديه بالفعل مكتبة المكونات الخاصة به، ورموز Tailwind، والأزرار، والبطاقات، والنماذج، والقواعد المتجاوبة، ونمط العلامة التجارية، وهيكل الصفحة، فإن تلك المهارات الخارجية قد تخلق تداخلًا بدلاً من التحسين.
يبدأ الذكاء الاصطناعي في التردد:
هل يجب اتباع المهارة الخارجية أم المكونات الموجودة؟ هل يجب إعادة استخدام البطاقة الموجودة أم إنشاء تصميم بطاقة جديد؟ هل يجب إضافة حركة لإحساس متميز أم الحفاظ على الأداء والاتساق؟ هل يجب استخدام تخطيط الصفحة المقصودة الخارجي أم اتباع بنية المعلومات الخاصة بالمنتج؟
النتيجة النهائية قد تبدو أكثر "معيارية" في مكان واحد، لكنها أقل اتساقًا ككل.
ليس الأمر أن الذكاء الاصطناعي فشل في اتباع القواعد. لقد اتبع الكثير من القواعد التي لا تنتمي إلى هذا المشروع.
عند تلك النقطة، بدلاً من إضافة المزيد من القواعد، اطلب من الذكاء الاصطناعي تلخيص القواعد الحقيقية للمشروع.
ما هي المكونات الشائعة الاستخدام؟ كيف تُنظم الصفحات عادةً؟ هل النماذج والنوافذ المنبثقة والأزرار والبطاقات مكتوبة بطريقة متسقة؟ أين توجد مفاتيح i18n عادةً؟ ما هي اصطلاحات استدعاءات API ومعالجة الأخطاء؟ أي المكونات يجب إعادة استخدامها، وأي منطق يجب عدم تكراره؟ كيف تم تنفيذ الميزات المماثلة مؤخرًا؟ ما هي العادات الهندسية الضمنية ولكن المستقرة التي يمتلكها المشروع بالفعل؟
لخص هذه أولاً. ثم قرر أي المهارات الخارجية تستحق التبني وأيها لا تتناسب مع المشروع الحالي.
قاعدة عملية: المهارات الخارجية مفيدة للقواعد الأساسية مثل الأمان، والامتثال، والأداء، وإمكانية الوصول، وSEO. بالنسبة لنمط المكونات، وطبقات العمل، وهيكل الصفحة، واصطلاحات التسمية، دع النموذج يلخص قاعدة الكود الخاصة بك أولاً.

من أضعف الطرق لاستخدام البرمجة بالذكاء الاصطناعي هي معاملته كمنفذ مطيع.
تقرر الحل، ثم تطلب من الذكاء الاصطناعي تنفيذه. ينفذه بالفعل. لكن بعد ذلك، تدرك أن المسار كان خاطئًا من البداية.
هذا يحدث غالبًا: تطلب من الذكاء الاصطناعي إصلاح مشكلة، فيصلحها بحل ثقيل. تطلب منه إضافة ميزة، فيضيفها، حتى لو كانت إعادة استخدام وحدة موجودة أفضل. تطلب منه إعادة هيكلة كتلة منطقية، فيفعل، لكنه يغفل أن المشكلة الحقيقية هي هيكل البيانات.
ما يجعل نموذج اللغة الكبير مختلفًا عن أداة الأتمتة التقليدية هو أنه لا ينفذ التعليمات فقط. يمكنه كتابة الكود لأنه استوعب كمية كبيرة من أنماط البرمجيات في العالم الحقيقي، والمشاريع مفتوحة المصدر، والنقاشات الهندسية، وحالات الفشل، وأفضل الممارسات.
إنه يعرف كيف تنظم أنظمة CMS المحتوى عادةً. إنه يعرف لماذا تهتم أنظمة التجارة الإلكترونية بحالات الطلب. إنه يعرف لماذا لا ينبغي ترميز i18n بشكل ثابت في كل مكان. إنه يعرف لماذا تحتاج استرجاعات الدفع إلى تكرارية. إنه يعرف لماذا يحتاج وقت تشغيل واجهة المتجر ومحرر الإدارة إلى عقد مستقر. إنه يعرف أيضًا لماذا يؤثر SEO والبيانات المنظمة والنماذج والأذونات والسجلات والاختبارات على بعضها البعض في الأنظمة الحقيقية.
إذا كنت تستخدمه فقط لتحويل فكرتك إلى كود، فأنت تترك الكثير من القيمة غير مستخدمة.
النهج الأفضل هو السماح للذكاء الاصطناعي باستكشاف الخيارات بناءً على صورة المشروع وسياق الكود أولاً:
هل هناك نمط تنفيذ أكثر نضجًا؟ أي طبقة يجب أن تنتمي إليها هذه الميزة؟ هل هناك نمط موجود يجب إعادة استخدامه؟ ما الوحدات التي قد يؤثر عليها هذا التغيير؟ هل هناك منطق مكرر في الكود الحالي؟ هل يجب إزالة أي منطق قديم؟ هل هذا المتطلب هو حتى الحل الصحيح للمشكلة؟
هذا ليس طلبًا من الذكاء الاصطناعي لاتخاذ القرار النهائي.
إنه طلب من الذكاء الاصطناعي لتوسيع مساحة القرار.
يمكن للذكاء الاصطناعي اقتراح إصلاحات تحفظية، وإعادة هيكلة محلية، وتجريدات للبروتوكول، وإعادة استخدام المكونات الموجودة، وحذف المنطق القديم، وتقسيم إلى وحدة منفصلة، أو حتى الإشارة إلى أن المتطلب الحالي قد لا يكون الصحيح.
الاختيار النهائي لا يزال ملكًا للإنسان.
لأن العديد من قرارات المنتج الحقيقية ليست تقنية بحتة. المنتجات في مرحلة مبكرة قد تهتم أكثر بالسرعة. تدفقات المعاملات قد تهتم أكثر بالاستقرار. صفحات SEO قد تهتم أكثر بالهيكل وقابلية الزحف. الأدوات الداخلية قد تهتم أكثر بقابلية الصيانة. الصفحات الموجهة للعملاء قد تهتم أكثر بالثقة والاتساق.
يمكن للذكاء الاصطناعي أن يظهر لك الخيارات. لا يمكنه تحمل مسؤولية المقايضة.
قاعدة عملية: عندما يكون مسار التنفيذ غير واضح، اطلب من الذكاء الاصطناعي 2-3 خيارات، والافتراضات، وأسطح التأثير، والمخاطر أولاً. عندما تكون الحدود واضحة، حينها قسم المهمة ودعه ينفذ.
---
الذكاء الاصطناعي جيد جدًا في خلق شعور بالإنجاز.
الكود مكتوب. الشرح مكتوب. الملخص مكتوب. اقتراحات الاختبار مكتوبة. حتى مذكرة التسليم تبدو احترافية.
لكن المشاريع الحقيقية لا يمكنها الاعتماد على "تم".
تجربة أكثر واقعية تبدو هكذا: الملخص يبدو مطمئنًا، لكن الفرق يظهر أن الذكاء الاصطناعي لمس بعض الملفات التي لم يكن يجب أن يلمسها. الصفحة الحالية تعمل، لكن مدخلاً آخر يتعطل. ظننت أنه غير النص فقط، لكن البيانات الوصفية، ومنطق التراجع، ومراجع المكونات تغيرت على طول الطريق.
لهذا السبب لا يمكن أن يكون التحقق فكرة لاحقة.
كلما كان الذكاء الاصطناعي أسرع في التوليد، أصبحت حلقة الانحدار أكثر أهمية. بمجرد أن يصبح التوليد رخيصًا، الجزء النادر لم يعد إنتاج الكود. بل هو إثبات أن الكود لم يكسر النظام.
حلقة الانحدار الجيدة تبدأ قبل التغيير.
أولاً، اطلب من الذكاء الاصطناعي تحديد سطح التأثير.
أي الوحدات، الصفحات، APIs، الأنواع، البيانات، SEO، i18n، الأذونات، المدفوعات، النماذج، التخزين المؤقت، أو تدفقات النشر قد تتأثر؟
ثانيًا، أثناء التنفيذ، اطلب من الذكاء الاصطناعي اتباع الهيكل الموجود.
أعد استخدام ما يجب إعادة استخدامه. اتبع الأنماط الموجودة حيثما أمكن. لا تنشئ تطبيقًا موازيًا بشكل عشوائي. لا تكسر اصطلاحات النظام فقط لإكمال مهمة محلية.
ثالثًا، بعد التنفيذ، اطلب من الذكاء الاصطناعي إجراء فحص عكسي لنقاط الانحدار.
أي الصفحات يجب فحصها؟ أي المسارات يجب تشغيلها؟ أي الاختبارات قد تفشل؟ أي الأنواع تحتاج إلى تحقق؟ أي منطق قديم يجب إزالته؟ أي سلوك تراجع يحتاج إلى تأكيد؟
رابعًا، يجب على البشر و CI التحقق من النتيجة.
لا تقرأ ملخص الذكاء الاصطناعي فقط. اقرأ الفرق. لا تفحص الصفحة فقط. شغل التدفق. لا تختبر المسار السعيد فقط. اختبر مسار الاستثناء. لا تتحقق من اللغة الافتراضية فقط. تحقق من سلوك التراجع. لا تتحقق فقط من إنشاء دفعة أو اشتراك. تحقق من الاسترجاعات، والإلغاء، والترقية، والتخفيض، والمحفزات المكررة. لا تتحقق فقط مما إذا كان المحتوى المُنشأ يُقرأ بسلاسة. تحقق مما إذا كان يتناسب مع العلامة التجارية، وهدف الصفحة، وهيكل SEO.
لهذا السبب أيضًا يمكن لشركات التكنولوجيا الكبرى إدخال البرمجة بالذكاء الاصطناعي في سير عمل التطوير. ليس لأن الذكاء الاصطناعي لا يرتكب أخطاء أبدًا، ولكن لأن لديهم مراجعة الكود، والاختبار، و CI/CD، والمراقبة، والأذونات، والسجلات، والاسترجاع، والحوكمة الهندسية التي يمكنها استيعاب التحول في الكفاءة.
قاعدة عملية: الذكاء الاصطناعي يُنتج النتيجة. البشر و CI يُثبتون أن النتيجة لم تكسر النظام. ما يجب إثباته، وكيفية إثباته، يجب أن يأتي من صورة المشروع، وهيكل الكود، وتحليل التأثير.
---
إذا بدأنا بـ "الذكاء الاصطناعي هو مضاعف للتنفيذ، وليس عجلة القيادة"، يبدو صحيحًا لكنه فارغ بعض الشيء.
في المشاريع الحقيقية، تقسيم العمل أكثر تحديدًا.
الذكاء الاصطناعي جيد في:
اقتراح الخيارات بناءً على المعرفة العالمية. تتبع التأثير من خلال هيكل الكود. العثور على التطبيقات المكررة والصراعات المحتملة. إنشاء المسودات الأولى للكود والاختبارات والتوثيق. شرح الوحدات المعقدة. المساعدة في عمليات إعادة الهيكلة والترحيل. سرد فحوصات الانحدار قبل الإصدار.
البشر أفضل في:
الحكم على أهداف العمل. تأكيد صورة المشروع. اتخاذ المقايضات التقنية. تحديد ما إذا كانت إعادة الهيكلة تستحق العناء في المرحلة الحالية. قبول أو رفض المخاطرة. تحديد أي القدرات يجب أن تصبح منتجية. تحمل المسؤولية النهائية عن الجودة وتجربة المستخدم.
هذا ليس حول من يحل محل من.
الذكاء الاصطناعي يوسع الحكم؛ البشر يتخذون المقايضات. الذكاء الاصطناعي يزيد سرعة التنفيذ؛ البشر يمتلكون اتجاه النظام. الذكاء الاصطناعي يكشف المزيد من الاحتمالات؛ البشر يختارون أي مسار يسلكونه.
قاعدة عملية: لا تستخدم الذكاء الاصطناعي فقط كمنفذ، ولا تدع الذكاء الاصطناعي يمتلك الاتجاه. دع الذكاء الاصطناعي يوسع الخيارات وتحليل التأثير؛ دع البشر يمتلكون حكم المرحلة، والمقايضات التجارية، والجودة النهائية.
---
المنطق وراء البرمجة بالذكاء الاصطناعي يمتد بشكل طبيعي إلى سير عمل الذكاء الاصطناعي للتاجر.
كلاهما يواجه نفس المشكلة الأساسية:
يحتاج الذكاء الاصطناعي إلى فهم السياق قبل أن يتمكن من تنفيذ المهام المفيدة.
يحتاج الذكاء الاصطناعي إلى صورة المشروع لكتابة كود جيد. يحتاج الذكاء الاصطناعي إلى صورة التاجر لتوليد محتوى مفيد. يحتاج الذكاء الاصطناعي إلى بنية العلامة التجارية والمنتج والصفحة والتحويل لدعم SEO و GEO.
لهذا السبب يستخدم العديد من التجار الذكاء الاصطناعي لكتابة النصوص، وبناء الصفحات، وتوليد الأسئلة الشائعة، أو صياغة المقالات، وتبدو النتيجة مكتملة لكنها لا تحول.
المشكلة عادة ليست أن الذكاء الاصطناعي لا يستطيع الكتابة.
المشكلة هي أن الذكاء الاصطناعي لا يعرف:
من هو التاجر. ماذا يبيع. لمن يبيع. لماذا يجب أن يثق به العملاء. ما هي الوظيفة التي من المفترض أن تؤديها الصفحة. ما إذا كان المحتوى يجب أن يقود إلى استفسار، أو شراء، أو حركة بحث طويلة الأجل. ما هي الاهتمامات الحقيقية التي يجب أن تجيب عليها الأسئلة الشائعة. كيف تتصل المنتجات والصفحات والنماذج و SEO.
بدون ذلك السياق، يمكن للذكاء الاصطناعي بسهولة توليد محتوى يبدو كنص.
قد يكون سلسًا، مكتملاً، وحتى مصقولاً. لكنه يفتقر إلى الحكم التجاري.
لذا فإن مفتاح سير عمل الذكاء الاصطناعي للتاجر ليس مطالبة المستخدمين بكتابة المزيد من المطالبات.
السؤال الأكثر أهمية هو ما إذا كان النظام يمكنه تنظيم بيانات العلامة التجارية والمنتج وهدف الصفحة والأسئلة الشائعة والنماذج و SEO ومسار التحويل تلقائيًا في سياق عالي الجودة — بحيث يفهم الذكاء الاصطناعي التاجر والعمل قبل تنفيذ المهمة.
هذا هو الاتجاه الذي تركز عليه Foundax عند تصميم سير عمل الذكاء الاصطناعي.
نحن لا نرى الذكاء الاصطناعي كزر "توليد" منعزل. النهج الأكثر قيمة هو جلب الذكاء الاصطناعي إلى تدفق تشغيل التاجر: مساعدة التجار على تنظيم المحتوى والصفحات والأصول متعددة اللغات و SEO ومواد التسويق بشكل أسرع، بينما يحمل النظام المنتجات والنماذج والمدفوعات والطلبات والنشر ومسارات التحويل.
في هذا التصميم، الذكاء الاصطناعي ليس ببساطة "يكتب فقرة لك".
يجب أن يفهم أولاً:
ما تمثله العلامة التجارية. ما المشكلة التي يحلها المنتج أو الخدمة. ما الوظيفة التي تحتاج الصفحة إلى أدائها. ما الاهتمام الذي يجب أن تجيب عليه الأسئلة الشائعة. أي نوع من العملاء المحتملين يجب أن يجمعه النموذج. أي نية بحث يجب أن يخدمها المحتوى. ما إذا كانت الصفحة يجب أن تقود إلى استفسار، أو شراء، أو ثقة طويلة الأجل.
ثم يمكنه توليد شيء مفيد.
هذا هو نفس منطق البرمجة بالذكاء الاصطناعي.
لا تعطِ الذكاء الاصطناعي مهمة محلية فقط. دعه يفهم الصورة أولاً. ثم استخدم البيانات المنظمة والعقود التجارية وحقن السياق لوضعه في بيئة المعلومات الصحيحة.
قاعدة عملية: مفتاح سير عمل الذكاء الاصطناعي للتاجر ليس مطالبة أفضل. إنها البيانات المنظمة والعقود التجارية والسياق عالي الجودة التي تساعد النموذج على فهم العلامة التجارية والعمل قبل توليد النصوص أو الصفحات أو المحتوى متعدد اللغات أو أصول SEO أو المواد التشغيلية.
---
غالبًا ما ركز SEO التقليدي على الكلمات المفتاحية والعناوين والوصف والروابط الخلفية.
تلك لا تزال مهمة.
لكن مع ازدياد شيوع البحث بالذكاء الاصطناعي والإجابات التوليدية، يصبح سؤال أعمق أكثر أهمية:
هل يمكن للآلات فهم من أنت؟
هل أنت موقع علامة تجارية أم صفحة هبوط مؤقتة؟ ماذا تبيع؟ من تخدم؟ أين منتجاتك وخدماتك وحالاتك وأسئلتك الشائعة ونقاط الاتصال؟ هل هناك هيكل بين المحتوى الخاص بك؟ هل يمكن زحف صفحاتك وفهمها والاستشهاد بها؟
هذه هي نفس المشكلة الأساسية كما في البرمجة بالذكاء الاصطناعي.
البرمجة بالذكاء الاصطناعي تتطلب من النموذج فهم هيكل المشروع. توليد المحتوى بالذكاء الاصطناعي يتطلب من النموذج فهم هيكل التاجر. SEO يتطلب من محركات البحث فهم هيكل الصفحة. GEO يتطلب من أنظمة البحث التوليدية فهم العلاقة بين العلامة التجارية والمنتجات والخدمات والمحتوى.
لذا فإن المستقبل لن يكون فقط حول من يمكنه توليد المزيد من المحتوى.
كلما أصبح توليد المحتوى أسهل، أصبح الهيكل أكثر أهمية.
إذا كانت العلامة التجارية تولد فقط عددًا كبيرًا من الصفحات المنعزلة، فإن محركات البحث والبحث بالذكاء الاصطناعي لا تزال ترى شظايا. إذا نظمت العلامة التجارية موقعها الإلكتروني ومنتجاتها وخدماتها وحالاتها وأسئلتها الشائعة ومحتواها ونماذجها ومسارات التحويل وصفحاتها متعددة اللغات في هيكل واضح، يصبح من الأسهل للمستخدمين ومحركات البحث وأنظمة الذكاء الاصطناعي فهمها.
قاعدة عملية: SEO و GEO ليسا فقط مشكلتي إنتاج محتوى. إنهما مشكلتا هيكل. كلما نظمت العلامة التجارية والمنتج والمحتوى والأسئلة الشائعة ومسارات التحويل بشكل أوضح، أصبح من الأسهل لكل من الآلات والمستخدمين فهمك.
إذا كنت تبني SEO و GEO لواجهة متجر، قد ترغب أيضًا في قراءة: القواعد الجديدة لـ SEO: الفوز بلعبة البحث بالذكاء الاصطناعي (GEO) في 2026، كيفية عرض المنتجات في ChatGPT ووضع Google AI: دليل التاجر 2026.
إذا كنت تهتم بكيفية عمل أصول العلامة التجارية والمحتوى و SEO معًا، اقرأ أيضًا: لماذا 2026 هو الوقت المناسب لبناء أصول علامتك التجارية الشخصية.
إذا كنت تقيم أدوات البرمجة بالذكاء الاصطناعي أو خيارات المجموعة التقنية، اقرأ المقال المرافق: كيف يجب أن تختار العلامات التجارية DTC متعددة الأسواق مجموعة التجارة الإلكترونية في 2026؟.
إذا كنت تريد زاوية استراتيجية المنتج حول لماذا أصبح التسليم عبر الويب أكثر أهمية في عصر الذكاء الاصطناعي، اقرأ: هل سيدفع الذكاء الاصطناعي المزيد من المنتجات إلى العودة إلى الويب في 2026؟.
إذا كنت تبني SEO و GEO لواجهة متجر، تابع القراءة: القواعد الجديدة لـ SEO: الفوز بلعبة البحث بالذكاء الاصطناعي (GEO) في 2026، كيفية عرض المنتجات في ChatGPT ووضع Google AI.
إذا كنت تريد رؤية كيف تدمج Foundax سير عمل الذكاء الاصطناعي في عمليات التاجر، راجع الميزات.
ليس الكود. ولا المهارات. بل صورة المشروع.
على الأقل، يجب أن يفهم الذكاء الاصطناعي خمسة أشياء: الهدف، الكائنات، القيود، سطح التأثير، والاتجاه المستقبلي. وإلا، سيعالج المتطلبات كمهام منعزلة وقد ينتج نتائج صحيحة محليًا ولكن خاطئة نظاميًا.
قاعدة القرار: إذا كان الذكاء الاصطناعي لا يستطيع شرح لماذا يوجد المشروع، وما هي الكائنات الأساسية، وما هي القيود التي لا يجب كسرها، فلا تطلب منه إجراء تغييرات رئيسية في الكود بعد.
---
ابدأ بصورة العمل، ثم قيّم ملاءمة الذكاء الاصطناعي.
إذا كان المنتج يتضمن محتوى، وصفحات، و SEO، وعمليات إدارة، ومعاملات، ونماذج، ومدفوعات، ودعم متعدد اللغات، فإنه عادةً يحتاج إلى أطر ناضجة، وأنواع واضحة، وقواعد بيانات مستقرة، وأنظمة دفع ناضجة، وسير عمل هندسية قابلة للتحقق.
المجموعة الملائمة للذكاء الاصطناعي ليست الأحدث. إنها المجموعة التي رأتها النماذج كثيرًا، ويمكن للبشر التحقق منها، ويمكن للأنواع تقييدها، ولدى المجتمع أنماط قوية لها.
قاعدة القرار: لا تسأل فقط ما إذا كانت التقنية جديدة. اسأل ما إذا كانت تناسب العمل، وما إذا كان الذكاء الاصطناعي يمكنه فهمها، وما إذا كان الفريق يمكنه التحقق منها، وما إذا كانت الصيانة طويلة الأجل قابلة للإدارة.
---
نعم، إذا أصبح المشروع أكثر ضوضاءً.
لكن إذا أصبح المشروع أكثر هيكلية، قد يصبح الذكاء الاصطناعي في الواقع أسهل في الاستخدام. المجلدات والأنواع والمخططات والمتكيفات والاختبارات والتسمية والتوثيق يمكن أن تصبح تدريجيًا دليل تشغيل النموذج.
المشكلة الحقيقية ليست حجم المشروع. إنها ضوضاء السياق.
قاعدة القرار: مع نمو المشروع، قلل ضوضاء السياق قبل زيادة أتمتة الذكاء الاصطناعي.
---
ليس بالضرورة.
المتطلبات التفصيلية يمكن أن تحسن دقة المهمة الواحدة، لكنها لا تضمن صحة النظام. المتطلب الأفضل لا يجب أن يقول فقط ماذا يفعل. يجب أن يشرح أيضًا لماذا توجد المهمة، وما هي حالة النظام المستهدفة، وكيفية التحقق من أن لا شيء قد كُسر.
قاعدة القرار: تفاصيل المهمة المحلية مفيدة، لكن يجب أن تُقرن بالهدف وحالة النظام ومعايير القبول.
---
ليس في البداية.
القواعد والمهارات وأفضل الممارسات مفيدة، لكنها تحتاج إلى أن تُفصل حسب النوع. المهارات الخارجية مفيدة للقواعد الأساسية مثل الأمان والامتثال والأداء وإمكانية الوصول و SEO. لكن القواعد الأصلية للمشروع مثل نمط المكونات وطبقات العمل وهيكل الصفحة واصطلاحات التسمية يجب أولاً تلخيصها من قاعدة الكود.
قاعدة القرار: استخدم المهارات الخارجية للمخاطر الأساسية العالمية. استخدم قاعدة الكود نفسها لاستخلاص نمط المشروع وهيكل العمل.
---
اطلب من الذكاء الاصطناعي تحديد سطح التأثير قبل التنفيذ، والتنفيذ وفقًا للهيكل الموجود، والفحص العكسي لنقاط الانحدار بعد التنفيذ، ثم دع البشر و CI يتحققون من النتيجة.
الانحدار ليس مجرد مشكلة اختبار نهائي. إنها مشكلة سير عمل مبنية على صورة المشروع وتوثيق الكود وتحليل التأثير.
قاعدة القرار: قبل كل تغيير، اسأل ما الذي قد يؤثر عليه. بعد كل تغيير، اسأل ما الذي قد يكون كسره.
---
لأن "شركات التكنولوجيا الكبرى تستخدم البرمجة بالذكاء الاصطناعي" و"يمكن شحن الكود المُنشأ بالذكاء الاصطناعي دون مراجعة" شيئان مختلفان.
قالت Google إن 75% من الكود الجديد مُنشأ بالذكاء الاصطناعي، لكنه لا يزال يُراجع من قبل المهندسين. رقم Microsoft البالغ 20%–30% لا يعني أيضًا أن مراجعة الكود والاختبار وحوكمة الجودة تختفي.
يُظهر Stack Overflow Developer Survey 2025 أن ثقة المطورين في دقة مخرجات الذكاء الاصطناعي لا تزال محدودة. تُظهر دراسة METR أيضًا أنه في قواعد الأكواد الناضجة، قد تبطئ أدوات الذكاء الاصطناعي المطورين بسبب تكاليف الفهم والانتظار والفحص والتصحيح.
قاعدة القرار: البرمجة بالذكاء الاصطناعي تستحق الإدخال في سير العمل الحقيقي، لكن يجب أن تأتي مع آليات المراجعة والاختبار والتحقق والاسترجاع.
---
كلاهما مشكلتا سياق.
يحتاج الذكاء الاصطناعي إلى صورة المشروع لكتابة الكود. يحتاج الذكاء الاصطناعي إلى صورة التاجر لكتابة النصوص وبناء الصفحات وتوليد الأسئلة الشائعة ودعم SEO.
إذا كان النظام لا يستطيع تنظيم العلامة التجارية والمنتج وأهداف الصفحة والأسئلة الشائعة والنماذج و SEO ومسارات التحويل، يمكن للذكاء الاصطناعي فقط توليد محتوى يبدو مكتملاً لكنه يفتقر إلى الحكم التجاري.
قاعدة القرار: مفتاح سير عمل الذكاء الاصطناعي للتاجر ليس المزيد من المطالبات. إنه سياق منظم عالي الجودة.
---
البرمجة بالذكاء الاصطناعي موجودة بالفعل داخل سير العمل التطويري الحقيقي.
لكن هذا لا يعني أنه يمكن توليد البرمجيات بشكل عشوائي، أو أن الحكم على المنتج يمكن تسليمه لنموذج.
في المشاريع الحقيقية، قيمة الذكاء الاصطناعي ليست استبدال الحكم. بل هي توسيع الحكم.
لكن هذا يعمل فقط إذا فهم الذكاء الاصطناعي النظام أولاً.
لذا فإن التسلسل الصحيح ليس مطالبة الذكاء الاصطناعي بكتابة المزيد من الكود.
بل هو:
ابني صورة المشروع. اختر مجموعة تقنية تناسب العمل وتدعم التعاون مع الذكاء الاصطناعي. حوّل هيكل الكود إلى توثيق. دع الذكاء الاصطناعي يفهم المنبع والمصب والتأثير من خلال ذلك الهيكل. ثم تعامل مع المهام المحددة، واختر المهارات بعناية، وابني حلقة الانحدار. أخيرًا، يمتلك البشر المقايضات والجودة النهائية.
هذا المنطق ينطبق على تطوير البرمجيات. كما ينطبق على التجار الذين يستخدمون الذكاء الاصطناعي لكتابة النصوص وبناء الصفحات ودعم المحتوى متعدد اللغات وتحسين SEO. كما ينطبق أيضًا على GEO وبناء أصول العلامة التجارية طويلة الأجل.
المرحلة التالية من البرمجة بالذكاء الاصطناعي ليست جعل الذكاء الاصطناعي يكتب أكثر.
بل هي جعل الذكاء الاصطناعي يعمل داخل النظام الصحيح.
---