Sites DTC vs marketplaces dans le commerce agentique
Un guide pratique pour utiliser les marketplaces tout en construisant un canal DTC avec données produit, relation client, contenu et mesure.
Lire la suite
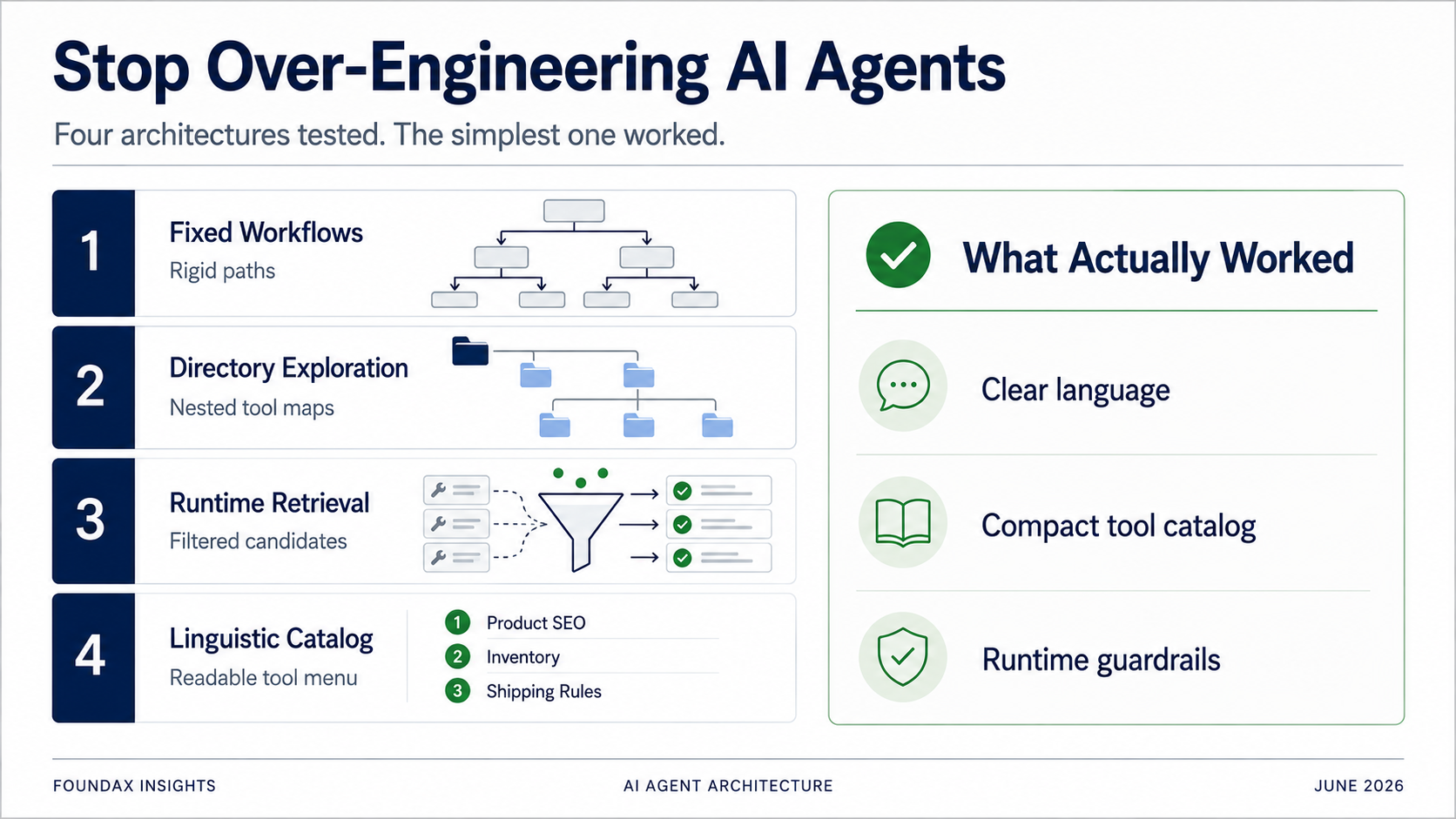
Quatre architectures Agent, du workflow fixe au catalogue linguistique léger. Chaque « optimisation » n'était en réalité que nous, faisant à la place du modèle ce qu'il pouvait faire lui-même. L'architecture gagnante est celle qui a renoncé à vouloir être plus maligne que le modèle.
Il y a un moment absurde dans la construction du Foundax Agent auquel je ne cesse de revenir.
Nous avons essayé beaucoup d'architectures. Des workflows fixes. Une exploration des outils par répertoire. Des recommandations d'outils basées sur les skills. Du runtime retrieval. Du matching par regex. Des plans structurés. Des boucles ReAct multi-tours. À un moment, nous avons même sérieusement envisagé un retrieval par embedding.
Chaque version tenait debout sur le papier.
Trop d'outils, donc il faut filtrer. Le modèle oublie des choses, donc il faut contraindre. Le contexte est trop long, donc il faut retrieven. L'exécution doit être sûre, donc il faut procéduraliser. La précision métier exige des outils atomiques de bas niveau.
Pris isolément, aucun de ces jugements n'était faux.
Et puis nous avons fait le test le plus simple – presque brutal : compresser tous les outils dans un catalogue linguistique léger, le jeter au modèle, et le laisser lire et choisir par lui-même.
Le résultat fut étonnamment bon.
Je suis resté sans voix.
Parce que cela signifiait que la plupart de nos conceptions complexes ne libéraient pas les capacités du modèle. Elles supposaient que le modèle allait échouer, puis l'enveloppaient de couches d'architecture pour compenser.
Cet article ne dit pas « exposer tous les outils est la meilleure pratique ».
Ce que je veux vraiment dire, c'est ceci : le plus grand danger dans la construction d'un Agent métier n'est pas que le modèle ne soit pas assez intelligent — c'est que vous commenciez à lui construire une cage avant même d'avoir testé ce qu'il peut faire dans votre domaine.
Foundax est une plateforme SaaS e-commerce.
Le Foundax Agent n'a donc pas affaire à du bavardage ou à des questions de culture générale. Il fait face aux vrais problèmes opérationnels que les marchands rencontrent dans leur back-office.
Les marchands ne disent pas :
« Veuillez appeler l'API de lecture des variantes produit. »
Ils disent :
« Pourquoi ce produit ne se vend-il pas ? »
« Ma page en espagnol est-elle déjà en place ? »
« Ce produit peut-il passer sur Google Shopping ? »
« Pourquoi les gens ajoutent au panier sans payer ? »
« Complète mon SEO manquant. »
Ces questions semblent être du langage naturel, mais derrière chacune se cache un système métier complet. Produits, SKU, stocks, prix, SEO, traductions, promotions, livraison, paiement, checkout, commandes, remboursements, flux GMC, état d'affichage en vitrine — n'importe lequel de ces éléments peut affecter le résultat.
L'objectif du Foundax Agent n'est donc pas de « sonner humain ».
Ce qu'il doit réellement faire : comprendre l'intention réelle du marchand, trouver les faits correspondants dans le système, sélectionner les bons outils, préparer des écritures si nécessaire, et exécuter sous contraintes de runtime — avec permissions, confirmation et readback en place.
L'entrée utilisateur peut être floue. L'exécution système doit être précise.
Cette tension est le point de départ de chaque dilemme architectural qui suit.
J'ai un penchant pour le perfectionnisme d'ingénierie.
Alors quand j'ai commencé à concevoir le Foundax Agent, j'ai instinctivement rejeté les outils à gros grain.
Un outil nommé analyzeProductReadiness semble pratique. Mais quels champs lit-il en interne ? Quels critères applique-t-il ? Où sont les frontières de permission ? Peut-on faire un readback après une écriture ? Tout cela devient opaque.
Foundax n'est pas une démo. Quand un marchand vous demande de corriger son SEO, vous ne pouvez pas laisser un outil boîte noire modifier des choses silencieusement en arrière-plan.
J'ai donc insisté sur des outils atomiques de bas niveau :
Lire les champs de base d'un produit. Lire les variantes produit. Lire les stocks et les prix. Lire le SEO produit. Lire les traductions produit. Lire la configuration de livraison. Lire la configuration de paiement. Écrire un champ spécifique. Écrire du contenu pour une locale spécifique. Générer un brouillon de modification. Readback après écriture.
Chaque outil à fonction unique, propre, sans chevauchement. Exécution précise, permissions claires, facile à tester.
Je pense toujours que ce jugement était juste.
Le vrai problème était ailleurs : plus vos outils de bas niveau sont atomiques, plus vous avez d'outils. Plus vous avez d'outils, plus il est difficile pour le modèle de les comprendre et de les sélectionner en contexte.
Ce fut le premier paradoxe.
Plus un outil de bas niveau convient à l'exécution système, moins il convient à l'interface cognitive du modèle.
L'atomicité n'était pas l'erreur. L'erreur était de déverser un tas d'outils atomiques directement devant le modèle en espérant qu'il choisisse systématiquement les bons.
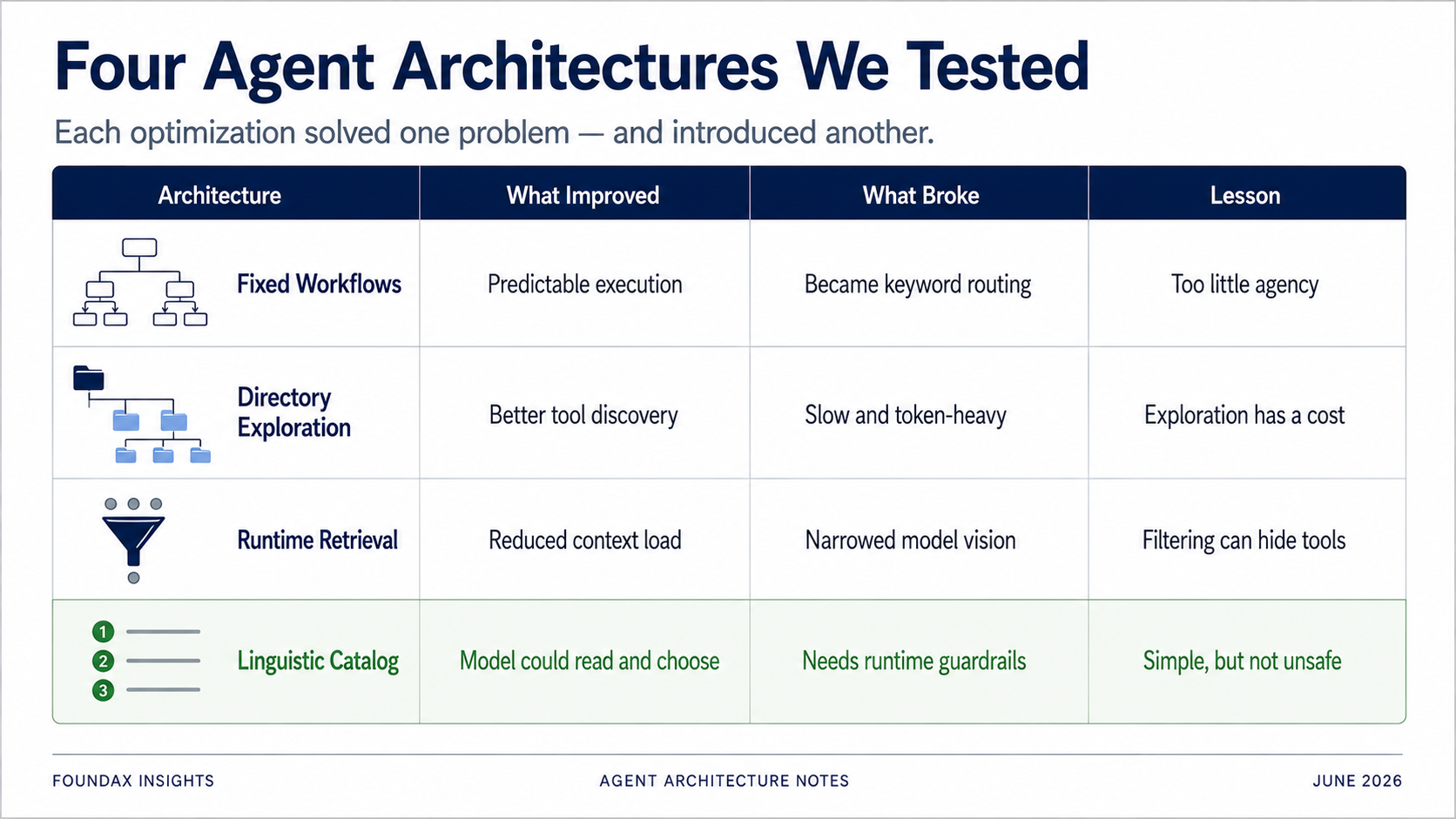
Pour résoudre le problème de sélection d'outils, notre première tentative fut les workflows fixes.
Un instinct naturel. Si les tâches à haute fréquence des marchands sont finies, pré-scripter-les.
Vérification SEO produit. Vérification de couverture des traductions. Vérification avant lancement produit. Diagnostic de faible conversion. Vérification de GMC preflight.
Le travail du modèle : identifier l'intention utilisateur, la mapper à un workflow, puis passer la main au runtime pour une exécution fixe.
Cela semblait sûr. Cela semblait bien architecturé.
Mais en test, cela a rapidement dégénéré en un système stupide de mots-clés.
L'expression des utilisateurs est trop variée. L'un dit « mon SEO est-il complet ? » Un autre dit « Google peut-il indexer cette page ? » Un autre dit « ai-je raté le titre du produit ? » Un autre dit « pourquoi mon flux n'arrête-t-il pas d'échouer quand je lance des publicités ? »
Pour que chaque variante atteigne une tâche, vous ajoutez sans cesse des mots-clés, des alias, des règles. Finalement, le système n'est ni précis ni maintenable.
Plus important encore, le modèle n'avait presque plus d'espace pour opérer. Il n'était qu'un classifieur d'intention. Le véritable chemin d'analyse, la sélection d'outils, la séquence de collecte de preuves — tout était prédéterminé par nous.
C'est là que la révélation m'a frappé :
Si chaque tâche est pré-scripter en workflow, la chose n'est plus un Agent — c'est un outil de workflow déguisé en IA.
Les workflows fixes, au fond, remplacent le raisonnement du modèle par une énumération métier humaine. Ils rendent le système plus contrôlable, mais ils dépouillent l'Agent de son Agency.
Nous avons pivoté.
Au lieu de déverser tous les outils d'un coup, les organiser en répertoire. Le modèle choisit d'abord un domaine métier, puis déplie les sous-répertoires, puis sélectionne des outils spécifiques.
Produits. Commandes. Paiements. Livraison. Promotions. Analytics. GMC.
Sous « Produits » : informations de base, SKU, stocks, prix, SEO, traductions.
C'était bien plus précis que les workflows fixes. Le modèle ne faisait pas correspondre des mots-clés à des chemins prédéfinis — il explorait une carte d'outils structurée. Il trouvait réellement plus souvent les bons outils.
Mais le problème était évident : la vitesse.
Chaque tâche nécessitait une traversée de répertoire. Les questions simples passaient quand même par toute la chaîne d'exploration. Consommation de tokens élevée. Latence élevée.
Un marchand demande « le SEO de ce produit est-il complet ? » et l'Agent se comporte comme s'il feuilletait un épais manuel technique.
L'exploration par répertoire n'était pas fondamentalement une mauvaise direction. Le problème est qu'elle transformait « comprendre le système d'outils » en un coût par invocation. Le modèle devait ré-explorer le système depuis zéro à chaque appel, ce qui est difficile à accepter comme expérience produit.
Ensuite, nous avons construit quelque chose de plus sophistiqué.
Le modèle produit d'abord une compréhension structurée du prompt utilisateur : décomposition d'intention, mots-clés, domaines métier impliqués, et si la tâche est read, write, mixed ou unknown.
Puis ce plan passe au runtime. Le runtime utilise les skills, le matching par regex et les métadonnées d'outils pour retrieven les outils candidats. Le modèle sélectionne parmi les candidats. Après avoir lu les faits, le modèle peut décider de continuer à explorer dans un autre tour.
Cette version ressemblait à un Agent Runtime mature. Et elle a apporté de réels progrès.
Par exemple, nous avons découvert que les champs structurés peuvent améliorer le comportement du modèle. Pour empêcher le modèle de saisir le premier outil qui semblait pertinent sans lire la liste complète des candidats, nous avons conçu un champ comme hasreadalltools — demandant au modèle de déclarer explicitement s'il avait fini de lire tous les candidats avant de faire un appel d'outil. Cela a vraiment aidé.
Mais ce qui était plus intéressant : nous avons constaté plus tard qu'une seule instruction en langage naturel bien écrite pouvait être plus efficace qu'un champ structuré complexe.
Avant que le modèle ne sélectionne les outils, nous avons ajouté :
« En fonction de l'objectif métier de l'utilisateur, sélectionne tous les outils d'analyse et d'écriture nécessaires. Ne te contente pas de prendre le premier outil qui semble pertinent. »
Avant que le modèle ne prépare sa réponse, nous avons ajouté :
« Ne te précipite pas pour répondre. Détermine d'abord si les faits nécessaires sont complets. Sinon, continue à sélectionner des outils. »
Ces simples prompts ont significativement amélioré la profondeur de raisonnement du modèle.
Ce fut un signal d'alarme majeur :
Un LLM n'est pas un programme traditionnel. Les protocoles structurés sont utiles, mais le modèle lit toujours du langage et imite le raisonnement. Le plus souvent, une instruction en langage naturel précise, directe et peu ambiguë fonctionne mieux qu'un champ structuré complexe.
Mais cette architecture a aussi révélé un problème plus profond.
Le runtime tool retrieval était conçu pour résoudre la surcharge de contexte et la sélection imprécise d'outils. Mais un runtime est, fondamentalement, un système de règles.
Qu'il s'agisse de regex, de skills, de mots-clés ou de filtrage par domaine — il peut filtrer des outils dont le modèle a réellement besoin, dès le premier passage.
Imaginez un marchand qui demande : « Pourquoi ce produit ne se vend-il pas ? »
Cette question pourrait concerner l'analytics. Elle pourrait aussi concerner le contenu produit, les prix, les stocks, les promotions, la livraison, le paiement, le checkout, les sources de trafic, la géographie, l'appareil, le SEO, l'authenticité de la copie de page.
Si le runtime la range trop hâtivement dans un seul domaine, le champ de vision du modèle est restreint.
C'est le troisième paradoxe :
Le runtime tool retrieval économise du contexte — mais il peut aussi devenir le plafond du champ de vision du modèle.
Nous voulions réduire la charge du modèle, et nous avons fini par potentiellement restreindre son jugement.
À mesure que le nombre d'outils augmentait, j'ai sérieusement envisagé le retrieval par embedding.
L'idée est naturelle. Prompt utilisateur → vecteur. Descriptions d'outils → vecteurs. Score de similarité. Top-k au modèle.
Cela semble standard. Cela semble « IA-native. »
Mais plus j'y réfléchissais, plus cela me semblait erroné.
Pour le retrieval publicitaire, la recommandation de contenu ou la recherche documentaire massive, les embeddings ont du sens. L'ensemble des candidats est énorme, et les systèmes traditionnels ne comprennent vraiment pas le langage. Il faut compresser la sémantique en vecteurs pour une correspondance approximative.
Mais les outils de Foundax ne sont pas des millions de documents inconnus dans un monde ouvert. Ce sont des capacités métier finies, énumérables, descriptibles, compressibles au sein de notre propre système.
Et la plus grande force du LLM est précisément de lire le langage, de comprendre le langage, de comparer la sémantique et de juger l'intention.
Alors pourquoi convertir les descriptions d'outils en vecteurs, puis utiliser un score de similarité pour décider — à la place du modèle — ce qu'il peut voir ?
C'est comme avoir un livre avec une table des matières parfaitement lisible. Au lieu de la lire, vous encodez la table en chiffres et demandez au lecteur de juger quel chapitre lire en fonction de la distance numérique.
Cela a du sens dans les systèmes de recherche traditionnels. Dans un Agent natif LLM, je crois de plus en plus que c'est un détour.
Pour un Agent métier comme Foundax, la priorité n'est pas le retrieval vectoriel. C'est la compression linguistique — compresser les outils, documents, capacités et contraintes dans un contexte linguistique clair, précis et de haute densité que le modèle peut lire directement.
Nous avons aussi rencontré un autre problème classique : l'exposition des outils était trop lourde.
Au début, chaque outil exposait des informations très complètes au modèle : nom de fonction, description longue, périmètre des faits, frontière de réponse, sources exclues, énumérations de champs, énumérations de niveau de détail, descriptions d'arguments, format de retour d'observation.
Cela semble rigoureux.
Mais j'ai fini par réaliser : le modèle n'a pas besoin de savoir la plupart de cela.
Si l'exécution réelle de la requête, la validation des champs, la vérification des permissions, les frontières owner-executor, les flux de confirmation et le readback sont tous gérés par le runtime, alors le modèle n'a aucune raison de lire le schéma API complet à chaque fois.
Ce que le modèle a réellement besoin de savoir :
Par exemple :
C'est suffisant.
Les préfixes « Read / Write / Search » dans la liste des candidats suffisent déjà au modèle pour distinguer les types d'action. Les véritables permissions read/write, les flux de confirmation, les frontières owner-executor — ceux-ci doivent rester dans le runtime, appliqués à l'exécution. Ne brûlez pas de tokens à les faire lire par le modèle. Et surtout, ne comptez pas sur le modèle pour s'y conformer volontairement.
La conclusion ici :
Le schéma est pour le runtime, pas pour le modèle. Le modèle doit voir un catalogue de capacités linguistiques, pas un dictionnaire d'API.
Finalement, nous avons fait le test le plus simple.
Exposer tous les outils au modèle sous forme de descriptions linguistiques extrêmement compressées. Laisser le modèle lire. Laisser le modèle choisir.
Le résultat fut étonnamment bon.
Honnêtement, ce résultat était une petite claque. Car chaque architecture complexe que nous avions construite auparavant était ancrée dans une hypothèse : le modèle ne peut pas gérer de voir trop d'outils, donc le runtime doit filtrer pour lui.
Mais le test a montré que cette hypothèse — du moins dans le contexte actuel de Foundax — ne tient pas complètement.
La question n'est pas « peut-on exposer tous les outils ? » La question est « qu'exposez-vous exactement au modèle ? »
Si vous exposez un mur de schémas API complets — longues descriptions, énumérations de champs, spécifications de paramètres — vous allez certainement noyer le modèle. Mais si vous exposez un catalogue de capacités linguistiques léger et clair, le modèle peut lire et choisir par lui-même — et il pourrait même faire un meilleur travail que le pré-filtrage du runtime.
Ce n'est pas un retour à l'exposition brute du début.
Le début était : déverser le dictionnaire API complet sur le modèle.
La fin était : remettre au modèle un manuel opérationnel compressé — un menu de capacités linguistiques léger, numéroté.
Ce sont des choses fondamentalement différentes. L'un est un océan d'outils. L'autre est une carte lisible.
Soyons concrets. Notre système compte des dizaines d'outils de lecture et de commandes d'écriture — plus d'une centaine d'outils canoniques au total. Chaque tâche expose au plus une douzaine d'outils au modèle, contrôlé par un budget d'exposition. La phase de toolselection a un budget de contexte de plusieurs dizaines de milliers de caractères. La description de schéma de chaque outil fait environ un millier de caractères (quelques centaines de tokens). Exposer une douzaine d'outils signifie environ dix à vingt mille caractères — environ quatre à cinq mille tokens. Très gérable.
Mais si nous exposions tous les outils avec leurs schémas complets ? Cela ferait près de deux cent mille caractères — environ cinquante mille tokens. Cela ne passerait vraiment pas.
L'insight clé : le runtime fournit des signatures d'outils compactes et numérotées à partir du registre canonique. Le modèle lit une fiche, pas une entrée d'encyclopédie.
Il serait facile de mal interpréter cela.
« Laisser le modèle lire et choisir » signifie-t-il que le runtime est sans importance ?
Bien au contraire.
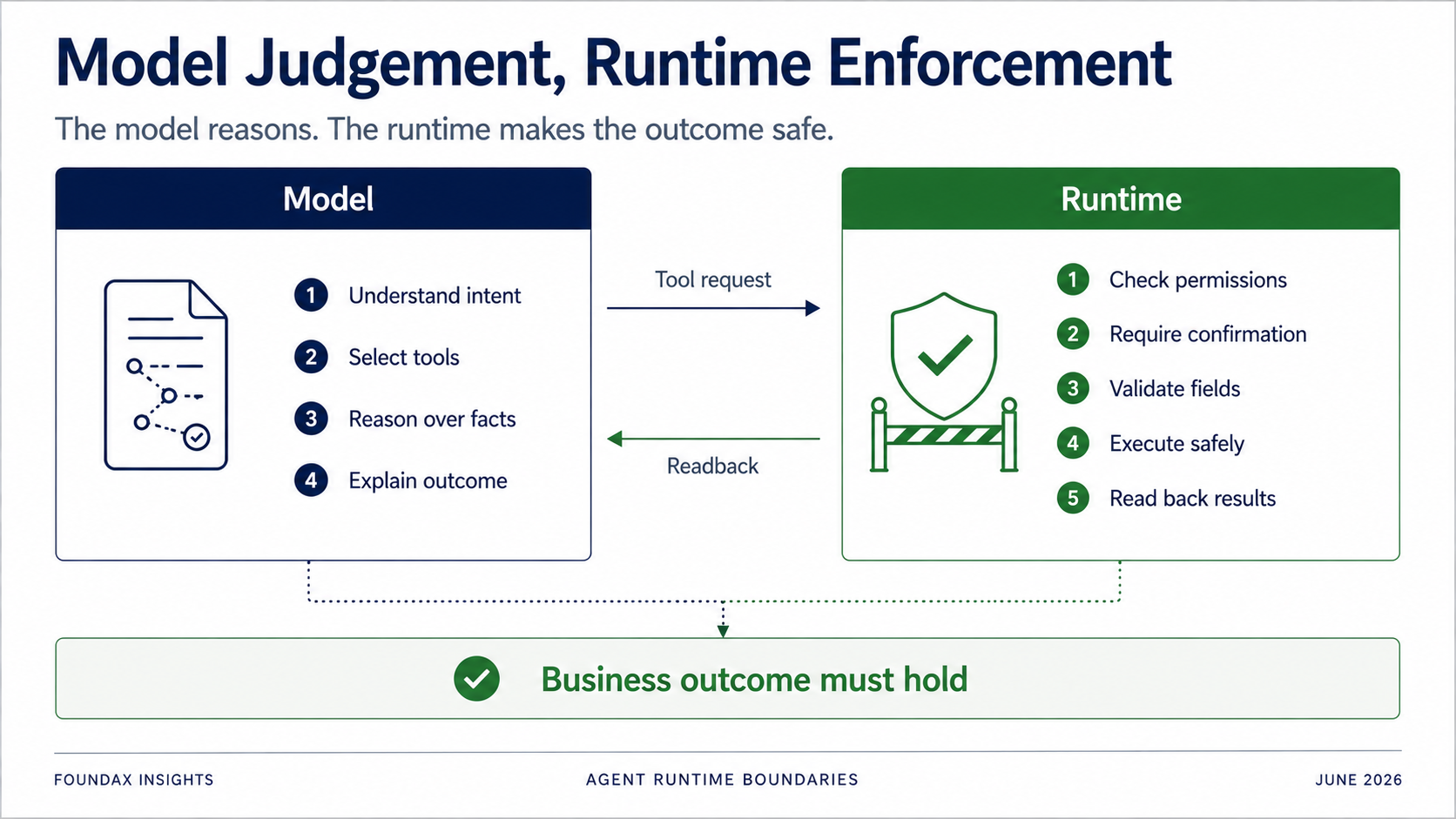
Le runtime reste critique — il ne doit simplement pas essayer de penser prématurément à la place du modèle.
Le modèle est responsable de comprendre, juger, sélectionner et expliquer.
Le runtime est responsable des permissions, de la confirmation, de la validation des champs, des frontières owner-executor, de l'exécution réelle et du readback.
Particulièrement pour les opérations d'écriture : vous ne pouvez absolument pas compter sur le modèle pour suivre volontairement les règles.
Le modèle peut dire « je veux mettre à jour le SEO de ce produit. »
Mais le runtime doit déterminer : l'utilisateur actuel a-t-il la permission ? Cette action nécessite-t-elle une confirmation ? Doit-elle d'abord générer seulement un brouillon ? Le champ est-il sur l'allowlist ? L'objet appartient-il au marchand actuel ? L'écriture a-t-elle réellement réussi ? Après readback, l'état métier correspond-il vraiment à la cible ?
L'objectif de l'Agent n'est pas de prouver qu'un appel d'outil a réussi. C'est de prouver que le résultat métier tient.
Cette frontière est essentielle. Tout ne va pas au modèle, et tout ne va pas au runtime. La vraie question est celle de la division du travail.
Le principal enseignement de ce parcours n'est pas que la version 4.0 est définitivement la meilleure architecture.
C'est que construire un Agent rend dangereusement facile de se laisser emporter par un enchaînement de préoccupations d'ingénierie réelles.
Inquiet que les tâches à haute fréquence ne soient pas stables quand le modèle improvise à chaque fois ? → Construisez des workflows fixes.
Inquiet que le contexte soit trop long et que le modèle souffre de dilution d'attention ? → Construisez une exploration par répertoire.
Inquiet que la croissance du nombre d'outils fasse exploser les tokens ? → Construisez du runtime retrieval.
Inquiet que le retrieval par mots-clés soit trop fragile pour des tâches multilingues et inter-domaines ? → Envisagez les embeddings, le scoring, le reranking.
Inquiet que le modèle choisisse des outils sans lire la liste complète, ou produise des réponses avant que les faits ne soient complets ? → Ajoutez des champs de contrainte structurés.
Aucune de ces inquiétudes n'est imaginaire. Elles correspondent toutes à des problèmes réels.
Nous avons simplement constaté — à la dure — que beaucoup de solutions résolvaient un problème tout en en introduisant un autre.
Les workflows fixes ajoutaient de la stabilité mais plafonnaient le raisonnement du modèle. L'exploration par répertoire était précise mais lente et coûteuse en tokens. Le runtime retrieval économisait le contexte mais pouvait bloquer des outils dont le modèle avait besoin. Les embeddings semblaient intelligents mais, pour la sélection d'outils native LLM, étaient probablement un détour. Les champs structurés pouvaient contraindre le modèle, mais parfois un simple prompt en langage naturel fonctionnait mieux.
Et la prise de conscience la plus critique :
Ces problèmes sont réels, mais ils ne sont pas nécessairement aussi graves dans votre projet.
Un contexte long cause-t-il réellement une dilution d'attention dans votre cas d'usage ? Testez-le. Votre nombre d'outils rend-il réellement les coûts de tokens inacceptables ? Testez-le. L'exposition complète des outils rend-elle réellement votre modèle paresseux, dépendant du chemin ou sujet aux erreurs ? Testez-le. Le runtime retrieval bloque-t-il réellement des outils dont votre modèle a besoin ? Testez-le aussi.
L'erreur la plus facile en architecture d'Agent est de traiter « les problèmes qui existent réellement dans le projet de quelqu'un d'autre » comme « les problèmes qui existent définitivement dans le vôtre. »
La première étape pour construire un Agent n'est donc pas de concevoir une architecture complexe pour prévenir chaque problème possible. La première étape est de tester :
Qu'est-ce que le modèle peut réellement comprendre dans votre domaine ? Peut-il lire vos descriptions d'outils ? Peut-il sélectionner des outils par lui-même ? Où manque-t-il des faits ? Quelles décisions pouvez-vous lui confier ? Lesquelles le runtime doit-il imposer ? Quelles actions nécessitent une confirmation utilisateur ? Quels résultats doivent être vérifiés par readback ?
Les réponses à ces questions — pas une architecture de référence trouvée dans un article de blog — doivent déterminer la conception de votre Agent.
Pour Foundax, nous avons maintenant de la clarté : les opérations e-commerce sont un domaine que le modèle connaît bien. Les entonnoirs de conversion, les pages produit, les prix, la livraison, les promotions, le paiement, la qualité du trafic, le SEO — ces cadres d'analyse apparaissent d'innombrables fois dans les données d'entraînement. Le modèle ne manque pas d'instinct d'analyse métier. Ce qui lui manque, c'est la connaissance du système spécifique de Foundax : quels faits il peut lire, quelles écritures il peut préparer, quelles actions le runtime doit posséder, quels résultats doivent être vérifiés par readback.
Le Foundax Agent ne consiste donc pas à apprendre au modèle comment faire de l'analyse e-commerce. Il consiste à remettre au modèle les capacités métier de Foundax dans un langage qu'il peut lire.
La première étape pour construire un Agent métier n'est pas de concevoir une architecture parfaite. C'est de tester jusqu'où vous pouvez réellement faire confiance au modèle.
Nous ne sommes pas les seuls à arriver à ces conclusions.
En décembre 2024, Anthropic a publié son guide « Building Effective Agents ». Son message central : la simplicité gagne. Commencez par la solution la plus simple possible. Un LLM augmenté avec accès aux outils peut être tout ce dont vous avez besoin. Quand je l'ai lu à l'époque, j'ai hoché la tête. Après avoir vécu ce que je viens de décrire, je le comprends viscéralement.
Puis en mai 2026, LangChain a tenu sa conférence Interrupt avec un pivot notable : le thème est passé de « les agents peuvent-ils aller en production ? » à « passage à l'échelle et opérations de production. » Le vrai goulot d'étranglement, comme l'ont souligné leurs supports, n'est pas d'écrire des agents — c'est de les gérer en production à grande échelle.
Un corpus croissant de recherches renforce cette direction. Les travaux de Google DeepMind en 2025 sur les limitations des embeddings ont montré mathématiquement que les embeddings vectoriels de taille fixe perdent des informations structurelles et relationnelles à l'échelle — directement pertinent pour quiconque envisage un retrieval d'outils par embedding. Le concept de Neo4j de « context engineering » soutient que l'IA fiable vient de l'architecture, pas d'astuces de formulation de prompts.
Notre expérience s'aligne sur une direction que nous observons dans toute l'industrie : les patterns simples/composables d'Anthropic, l'accent de LangChain sur les opérations de production plutôt que les abstractions de frameworks. Moins d'échafaudage préfabriqué, plus de capacité directe du modèle — mais toujours validé contre l'usage réel, pas adopté comme dogme. Moins de pré-filtrage, plus de jugement du modèle. La question n'est pas « comment construire une architecture parfaite autour du modèle ? » C'est « comment donner au modèle ce dont il a réellement besoin et s'écarter de son chemin ? »
Cela ne rend pas les conclusions de Foundax universelles. Des entreprises différentes, des modèles différents, des surfaces d'outils différentes arriveront à des réponses différentes. Ce qui est universel, c'est la méthode : tester d'abord, concevoir ensuite.
Q : Cela signifie-t-il que je devrais toujours exposer tous les outils au modèle ?
Non. Cela dépend du nombre d'outils, de votre modèle, de votre budget de contexte et de votre domaine. Le propos n'est pas « toujours tout exposer. » Le propos est : testez avant de filtrer. Ne supposez pas que le modèle ne peut pas gérer — vérifiez. Dans notre cas, environ une douzaine de signatures d'outils compressées par tâche était gérable et efficace. Vos chiffres peuvent différer.
Q : Quand devrais-je utiliser des workflows fixes à la place ?
Quand la tâche est véritablement déterministe, que le risque d'erreur est catastrophique et que la connaissance de fond du modèle dans ce domaine est faible. Les workflows ne sont pas mauvais — ils le sont quand ils remplacent un raisonnement que le modèle aurait pu faire. Utilisez-les pour les garde-fous de sécurité et le post-traitement déterministe, pas comme substitut au jugement du modèle.
Q : Quelle est la différence entre un catalogue linguistique et un schéma API ?
Un catalogue linguistique dit au modèle ce qu'un outil peut faire, en langage naturel compressé — par exemple « Read: [12] Product Variants — SKU / prix / stock / statut de disponibilité. » Un schéma API dit au modèle comment appeler l'outil, avec spécifications complètes de paramètres, énumérations et contraintes. Le modèle a besoin du menu des capacités. Le runtime a besoin du manuel technique. Mélanger les deux est l'une des erreurs les plus coûteuses que vous puissiez commettre.
Q : Comment décider ce qui va au modèle vs. au runtime ?
Une bonne heuristique : le modèle gère la compréhension, le jugement, la sélection et l'explication. Le runtime gère les permissions, l'exécution, la confirmation, la validation et le readback. Si vous demandez au modèle d'appliquer des règles, vous êtes du mauvais côté de la ligne. Le modèle suggère ; le runtime décide et exécute.
Q : Qu'en est-il du coût ? Exposer plus d'outils n'augmente-t-il pas la consommation de tokens ?
Dans notre cas, un catalogue linguistique compressé était en réalité moins cher que l'exploration par répertoire multi-tours ou les chaînes de retrieval. Chaque entrée d'outil fait environ un millier de caractères. Avec une douzaine d'outils exposés par tâche, le total est d'environ dix à vingt mille caractères — environ quatre à cinq mille tokens. Comparez cela à plusieurs tours de décomposition d'intention, retrieval, revue de candidats et re-sélection. L'approche la plus simple était souvent plus efficace en tokens, pas moins.
Q : Quel a été l'enseignement le plus important de ce processus ?
Qu'« aider le modèle » et « contraindre le modèle » peuvent sembler identiques du point de vue du concepteur, mais avoir des effets opposés sur le système. Chaque architecture que nous avons construite était censée aider. La plupart ont fini par contraindre. La différence n'est devenue claire qu'à travers les tests. Si vous ne retenez qu'une chose de cet article, que ce soit celle-ci : testez ce que votre modèle peut réellement faire avant de commencer à concevoir une architecture pour compenser ce que vous supposez qu'il ne peut pas.