Sites DTC vs marketplaces dans le commerce agentique
Un guide pratique pour utiliser les marketplaces tout en construisant un canal DTC avec données produit, relation client, contenu et mesure.
Lire la suite
Les Big Tech ont déjà intégré le codage IA dans leurs flux de travail. Mais pour la plupart des équipes, la première étape n'est pas d'écrire plus de code plus vite, c'est d'avoir une vision projet claire.
Le codage par IA a depasse la question de savoir si l'IA peut ecrire du code.
Il n'y a pas si longtemps, la plupart des discussions sur le codage par IA tournaient encore autour de demonstrations : Peut-elle generer une page ? Peut-elle ecrire une fonction ? Peut-elle corriger un bug ? Cette question n'est plus la plus interessante.
En 2026, Sundar Pichai, PDG de Google, a declare que 75 % du nouveau code de Google est maintenant genere par l'IA et revu par des ingenieurs. Satya Nadella, PDG de Microsoft, a egalement declare qu'environ 20 a 30 % du code dans les depots Microsoft est genere par l'IA. GitHub Octoverse 2025 montre a quelle vitesse les nouveaux developpeurs adoptent les flux de travail assistes par l'IA : 80 % des nouveaux developpeurs GitHub utilisent Copilot dans leur premiere semaine.
La tendance est deja claire : le codage par IA entre dans le developpement logiciel reel.
Mais une autre realite est tout aussi claire : les developpeurs ne lui font pas encore entierement confiance.
Le Stack Overflow Developer Survey 2025 a revele que 46 % des developpeurs se mefient de la precision des outils d'IA, contre 33 % qui leur font confiance. L'essai randomise controle de METR en 2025 avec des developpeurs open-source experimentes a montre que, dans des codebases matures, l'utilisation des outils d'IA de l'epoque augmentait en fait le temps d'achevement des tâches de 19 %. Le rapport DORA 2025 sur le developpement logiciel assiste par l'IA presente egalement l'IA comme un amplificateur : elle amplifie les forces qu'une organisation possede deja, et elle peut aussi amplifier les problemes existants.
Cela cree une tension tres reelle.
Les grandes entreprises utilisent le codage par IA. Les developpeurs l'utilisent aussi. Mais les personnes responsables des systemes reels ne font toujours pas simplement confiance a un message du type "l'IA dit que c'est fait".
La raison est facile a comprendre.
L'IA peut rapidement produire une fonctionnalite qui semble correcte isolement. La page s'ouvre. Le bouton fonctionne. L'API repond. L'UI a l'air bien. Mais une fois que le changement est fusionne dans un produit reel, un autre module se casse, un ancien chemin est contourne, les conventions de composants deviennent incoherentes, le fallback linguistique disparait, les metadonnees SEO sont ecrasees, ou un cas limite dont personne n'a parle cesse de fonctionner.
Ce sentiment est familier : le changement semble correct en soi, mais quelque chose cloche une fois qu'il se trouve dans le systeme complet.
Donc la vraie question n'est pas de savoir si l'IA peut ecrire du code.
La question la plus importante est :
Est-ce que l'IA complete une tâche, ou comprend-elle le systeme ?
Si elle ne comprend que la tâche, elle peut etre localement correcte et systemiquement fausse. Si elle comprend d'abord le systeme, le codage par IA a bien plus de chances de devenir une productivite reelle.
---
Lorsqu'une equipe commence a utiliser le codage par IA, le geste naturel est de lui lancer des tâches.
"Ajoute un filtre ici." "Mets a jour cette page." "Refactore ce composant." "Connecte un point d'entree de paiement." "Ajoute un champ multilingue."
L'IA repond generalement rapidement. Le probleme est qu'elle ne fait peut-etre que completer la tâche litterale.
Vous lui demandez d'ajouter un filtre, et elle ajoute un filtre. Vous lui demandez de mettre a jour une page, et elle met a jour la page. Vous lui demandez de refactorer un composant, et elle refactore le composant.
Mais elle ne sait peut-etre pas pourquoi cette page existe, ou le composant est reutilise, si le champ est consomme par la vitrine, ou si le point d'entree de paiement est lie aux etats de commande, aux callbacks, aux remboursements et a la gestion des erreurs.
C'est pourquoi le projet image compte.
Le projet image n'est pas une phrase du genre "c'est un produit SaaS" ou "c'est un site e-commerce".
C'est du contexte, pas une comprehension du systeme.
Un projet image utile devrait repondre a au moins cinq questions.
Premierement, l'objectif.
Qu'est-ce que ce produit essaie d'accomplir ? Trafic de recherche, conversion, gestion de produits, capture de leads, traitement de transactions, ou efficacite operationnelle ? La meme tâche "construire une page" signifie des choses tres differentes selon l'objectif. Si l'objectif est le SEO, la page a besoin de metadonnees, de contenu structure, de liens internes et de capacite d'exploration par les robots. Si l'objectif est l'efficacite back-end, elle a besoin de formulaires, de filtres, d'actions groupées et de gestion des erreurs. Si l'objectif est la conversion, la page ne peut pas seulement etre belle ; elle doit soutenir la confiance, le paiement, les commandes et les attentes apres-vente.
Deuxiemement, les objets.
Quels sont les objets centraux du systeme, et comment sont-ils relies entre eux ? Des mots comme utilisateur, produit, commande, page, contenu et site peuvent signifier des choses tres不同es selon les systemes. Si les objets sont flous, l'IA peut facilement melanger des choses qui se ressemblent techniquement mais sont不同es dans le metier.
Troisiemement, les contraintes.
Qu'est-ce qui ne doit pas etre modifie a la legere ? Les bibliotheques de composants existantes, les modeles de routage, la structure i18n, les modeles d'autorisation, les flux de publication, les flux de paiement, les contraintes de migration, la voix de la marque et la strategie SEO sont autant de contraintes. Les contraintes ne sont pas la pour limiter l'IA. Elles aident l'IA a eviter la mauvaise voie.
Quatriemement, la surface d'impact.
Quand quelque chose change, ou l'impact peut-il se propager ? Cela n'affecte-t-il qu'une seule page, ou cela touche-t-il les modeles de donnees, les API, le rendu de la vitrine, l'i18n, le cache, la recherche, les autorisations ou l'analytique ? Plus la surface d'impact est claire, moins il est probable que "cette fonctionnalite marche, mais quelque chose d'autre s'est casse."
Cinquiemement, la direction future.
S'agit-il d'un correctif ponctuel, ou cela deviendra-t-il une capacite du produit ? Si cela sera reutilise, le codage en dur est risqué. S'il s'agit d'un correctif a court terme, une sur-abstraction peut etre inutile.
Ces cinq questions forment ensemble l'image dont l'IA a besoin.
Sans image, l'IA traite la tâche comme isolee. Avec une image, l'IA peut juger la tâche a l'interieur du systeme.
Regle pratique : le projet image n'est pas une introduction de projet. C'est l'objectif, les objets, les contraintes, la surface d'impact et la direction future. Sans cela, ne vous precipitez pas a demander a l'IA d'apporter des modifications majeures au code.
---
Les discussions sur la pile technologique deviennent souvent des arguments sur ce qui est plus moderne.
React ou Vue ? Next.js ou Remix ? Node.js ou Go ? PostgreSQL ou MySQL ? Devrions-nous utiliser le framework le plus recent dont tout le monde parle ?
Ces questions comptent, mais elles ne peuvent pas etre repondues en dehors du projet image.
Un site de contenu, un systeme de transactions, un outil d'administration interne, une plateforme de generation de leads B2B et une plateforme de flux de travail IA n'ont pas besoin des memes capacites. Ce que le produit doit supporter devrait decider du modele de donnees, de la structure de routage, du modele d'autorisation, de la strategie de rendu, de la capacite SEO, de l'ecosysteme de paiement, du systeme de composants et du chemin de deploiement.
A l'ere du codage par IA, la pile technologique a egalement une nouvelle dimension :
L'IA peut-elle la comprendre facilement, et les humains peuvent-ils la verifier facilement ?
Les modeles ne comprennent pas un codebase de nulle part. Leur comprehension d'une pile depend de la quantite de code reel, de travail open-source, de documentation, de discussions sur les erreurs et de pratiques d'ingenierie qui existent dans cet ecosysteme. Plus l'IA a vu d'exemples fiables, moins elle est susceptible de deviner a partir de rien.
C'est pourquoi de nombreux produits web, systemes d'administration, systemes de contenu et produits orientes transactions preferent souvent des combinaisons matures comme TypeScript, React / Next.js, Node.js, PostgreSQL, des ecosystemes de paiement matures et des systemes de composants UI stables.
Cela ne signifie pas que ces technologies sont toujours le meilleur choix.
Cela signifie qu'elles sont plus faciles a comprendre pour l'IA, et plus faciles a verifier pour les humains.
GitHub Octoverse 2025 montre que TypeScript est devenu le langage le plus utilise sur GitHub. State of JavaScript 2024 a egalement revele que 67 % des repondants ecrivent plus de TypeScript que de JavaScript. Cela compte pour le codage par IA car, a mesure que l'IA ecrit plus de code, les equipes ont besoin de systemes de typage plus forts, de retours IDE, de controles statiques et de modeles d'ingenierie coherents pour contraindre la sortie.
TypeScript n'est pas seulement une question de securite de type.
Dans le codage par IA, il donne egalement au modele des signaux structurels :
Quels parametres une fonction attend. Quelles props un composant recoit. Si un objet manque d'un champ. Si une reponse API correspond a la forme attendue. Si la modification passe toujours la verification de type.
Les frameworks matures, les ecosystemes de paiement, les bases de donnees et les systemes d'UI jouent un role similaire. Ils reduisent l'espace dans lequel l'IA peut improviser et aident les humains et les modeles a suivre des modeles stables.
Bien sur, une pile mature n'est pas toujours la reponse.
Si le projet image implique une infrastructure a haute concurrence, de la video en temps reel, du reseau de peripherie ou du traitement profond de donnees, la pile technologique doit etre jugee differemment. La convivialite pour l'IA n'est pas le seul critere. L'adequation metier prime toujours.
Regle pratique : utilisez le projet image pour decider de ce dont le metier a besoin, puis utilisez la convivialite pour l'IA pour juger si la pile est facile a comprendre, a verifier et a maintenir. Une bonne pile de codage IA est adaptee au metier, largement vue par les modeles, verifiable par les humains, contrainte par les types et soutenue par des modeles communautaires solides.
Si vous evaluez une pile e-commerce ou un constructeur de site, vous voudrez peut-etre aussi lire cette etude de cas : Plateforme « Taxes Cachees » et le Veritable Cout d'une Pile Technologique Gonflee.
---
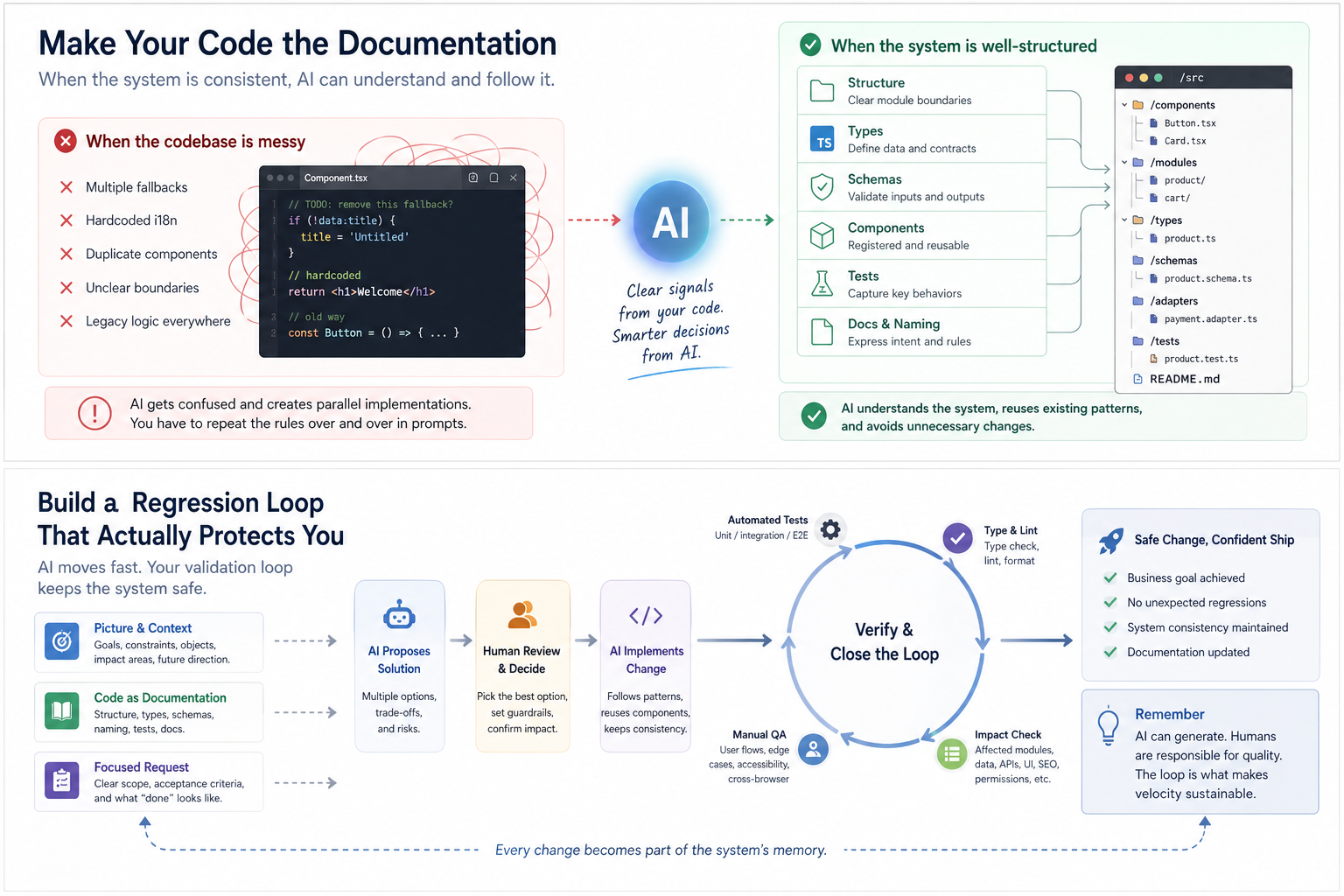
A mesure qu'un projet grandit, la partie la plus difficile du codage par IA n'est pas toujours qu'il y a trop de code. C'est souvent que le code est trop bruyant.
Une scene courante ressemble a ceci : vous demandez a l'IA de modifier une fonctionnalite. Elle lit de nombreux fichiers et essaie clairement, mais elle cree neanmoins une implementation parallele.
Elle ignore le composant existant et en ecrit un nouveau. Elle saute l'API existante et cree un autre chemin. Elle ne reutilise pas le type existant et en definit un similaire. Elle contourne la structure i18n et code le texte en dur. Elle ne supprime pas l'ancienne logique ; elle ajoute simplement une autre couche de compatibilite.
A ce stade, ne vous precipitez pas a blamer le modele.
Regardez plutot le projet lui-meme. Le probleme est peut-etre deja la : trois chemins de fallback differents, i18n melange avec du texte code en dur, des composants « partages » avec de la logique metier a l'interieur, d'anciennes implementations qui ne sont plus utilisees mais jamais supprimees. L'IA entre dans cet environnement et choisit l'un des signaux contradictoires qui lui semble raisonnable.
Cela explique pourquoi la meme instruction doit etre repetee encore et encore.
« Ne cree pas un nouveau composant. » « Ne code pas en dur. » « Cette page doit utiliser i18n. » « Ce bouton doit utiliser le composant existant. » « Cette API doit utiliser le modele de gestion des erreurs partage. »
Si ces regles doivent etre repetees dans les invites a chaque fois, le probleme n'est pas simplement que l'IA a oublie. C'est que la structure du projet n'exprime pas les regles assez clairement.
Les rappels dans les invites sont acceptables a court terme.
Mais avec le temps, la meilleure demarche est de poser la question inverse : le code contient-il deja des fallbacks contradictoires ? L'i18n est-elle incoherente ? La limite de la bibliotheque de composants est-elle floue ? Le meme objet metier a-t-il plusieurs noms ? Les anciennes implementations sont-elles toujours la, rendant impossible pour l'IA de savoir quelle est la norme actuelle ?
La vraie solution n'est pas une invite plus longue. C'est de faire des regles une partie du codebase.
La structure des dossiers indique a l'IA les limites des modules. Les types indiquent a l'IA les relations entre les donnees. Les adaptateurs indiquent a l'IA les regles de transformation. Les schemas indiquent a l'IA les contraintes d'entree et de sortie. Les tests indiquent a l'IA les comportements cles. La denomination indique a l'IA le langage metier. La documentation indique a l'IA l'intention de conception.
A ce stade, le code lui-meme devient la documentation.
Lorsque l'IA construit des fonctionnalites, refactore ou enquete sur des problemes, elle n'a pas besoin qu'un humain lui reexplique tout depuis le debut. Elle peut suivre la structure, trouver les modules pertinents, comprendre la surface d'impact, identifier les implementations en double et reduire le risque qu'une tâche casse une autre partie du produit.
Regle pratique : chaque fois que vous devez repeter la meme regle a l'IA, verifiez d'abord si le codebase contient deja des signaux contradictoires. Ensuite, deplacez la regle dans la structure, les types, la denomination, les schemas, les adaptateurs, les tests ou la documentation. Sinon, vous utilisez des invites pour maintenir la coherence du systeme.
La partie la plus dangereuse du travail d'IA mono-tâche n'est pas que l'IA ne peut pas ecrire le code. C'est que l'IA ne voit que ce qui est devant elle.
La page s'affiche, mais le SEO se casse. Le formulaire est soumis, mais les autorisations sont contournees. Le point d'entree de paiement s'ouvre, mais l'etat de la commande est incomplet. Le champ multilingue est sauvegarde, mais le runtime de la vitrine ne le consomme pas correctement. Le composant a meilleure allure, mais ne correspond plus au systeme de conception existant.
Ce ne sont pas des erreurs de syntaxe.
Ce sont des erreurs de surface d'impact.
La partie penible est qu'elles n'apparaissent souvent pas immediatement. La page a l'air bien aujourd'hui. La build passe. Le resume de l'IA a l'air confiant. Quelques jours plus tard, une autre version linguistique a le mauvais titre, un ancien lien renvoie une erreur 404, une soumission de formulaire n'atteint jamais le panneau d'administration, ou un flux de publication apparemment sans rapport commence a echouer.
Vous ne pouvez pas resoudre cela simplement en redigeant la tâche plus en detail.
Le probleme n'est pas que l'IA ne sait pas ce que vous voulez cette fois-ci. Le probleme est qu'elle ne sait pas ce que ce changement peut toucher.
Lorsque le projet a une image, et que le codebase devient progressivement de la documentation, l'IA peut faire plus que modifier un fichier. Elle peut commencer a suivre la structure du systeme pour comprendre les dependances en amont et en aval.
Si vous lui demandez de modifier un module de contenu, elle peut tracer les types, les adaptateurs, les consommateurs de pages, les metadonnees SEO, les cles i18n et les chemins de rendu de la vitrine.
Si vous lui demandez de modifier un formulaire, elle peut tracer les schemas, les API, la validation, la logique de soumission, les notifications, les enregistrements de leads et les interactions front-end.
Si vous lui demandez d'ajuster un composant, elle peut tracer l'enregistrement du composant, les pages reutilisees, les jetons de theme, le comportement responsive et les controles d'accessibilite.
Voila la valeur du code comme documentation.
Sans image, l'IA ne peut que repondre « comment implementer ceci ? » Avec une image, l'IA peut aussi repondre « qu'est-ce que cela pourrait affecter ? »
Regle pratique : avant de demander a l'IA d'implementer une tâche, ne demandez pas seulement comment elle va le faire. Demandez-lui de tracer les modules, les chemins et les points de regression qui pourraient etre affectes.
---
Les tâches doivent etre claires.
Mais la clarte ne signifie pas decrire chaque bouton, champ, couleur et interaction dans un detail extreme.
Certaines tâches de codage IA semblent fluides au debut : vous redigez soigneusement le besoin, et l'IA le suit. Mais quand elle termine, l'etat du systeme semble plus etrange. L'ancienne logique persiste, la nouvelle logique s'ajoute par-dessus, la page fonctionne mais la reutilisation est cassee, un champ est ajoute mais la source et la destination des donnees sont incompletes.
Cette experience peut etre trompeuse. Elle vous fait vous demander si le besoin n'etait pas assez detaille.
Souvent, ce qui manque n'est pas le detail. C'est l'etat cible du systeme.
Vous dites a l'IA « ajoute un bouton », et elle ajoute un bouton. Vous dites a l'IA « ajoute un champ », et elle ajoute un champ. Vous dites a l'IA « fais-en une confirmation en deux etapes », et elle modifie le flux.
Mais vous ne lui avez pas dit ce que le systeme devrait avoir en moins, ce qui devrait rester, et ce qui devrait etre unifie apres le changement.
Apres avoir ajoute une nouvelle logique, l'ancienne logique doit-elle etre supprimee ? Apres avoir ajoute un nouveau champ, comment les donnees historiques doivent-elles etre traitees ? Apres avoir lance une nouvelle page, l'ancienne entree doit-elle encore exister ? Apres avoir ajoute un nouveau composant, les composants en double doivent-ils etre consolides ? Apres avoir introduit une nouvelle approche i18n, l'ancien texte code en dur doit-il aussi etre supprime ?
C'est la partie la plus facile a manquer dans une tâche unique.
Un bon besoin ne devrait pas seulement dire a l'IA quoi construire. Il devrait aussi inclure trois choses.
Premierement, pourquoi la tâche existe.
Est-ce pour l'experience utilisateur, la conversion, l'efficacite operationnelle, le SEO, la stabilite ou la dette technique ? Si l'objectif n'est pas clair, l'IA choisira generalement le chemin le plus direct, pas necessairement le meilleur chemin.
Deuxiemement, a quoi le systeme devrait ressembler apres le changement.
Qu'est-ce qui devrait changer ? Qu'est-ce qui ne devrait pas changer ? Quelle ancienne logique devrait etre supprimee ? Quelle logique de compatibilite devrait rester ?
Troisiemement, comment savoir si rien n'a ete casse.
Quelles pages devraient etre verifiees ? Quels chemins devraient etre executes ? Quelles donnees devraient etre inspectees ? Quel comportement de fallback devrait etre confirme ? Sans criteres d'acceptation, l'IA peut facilement produire quelque chose qui a simplement l'air termine.
Donc oui, une tâche peut etre detaillee.
Mais elle ne peut pas contenir uniquement des details. Elle doit aussi dire a l'IA dans quel etat le systeme devrait etre apres le changement.
Regle pratique : les details locaux de la tâche sont utiles, mais ils doivent etre accompagnes de la raison pour laquelle la tâche existe, de l'etat cible du systeme et de la maniere de verifier que rien n'a ete casse.
---
A mesure que les outils de codage par IA deviennent plus populaires, Internet se remplit naturellement de regles, de competences, d'invites et de meilleures pratiques.
C'est comprehensible. Tout le monde veut rendre l'IA plus fiable.
Mais un probleme courant est que les equipes ajoutent un tas de regles externes avant que le projet image soit clair ou que la structure du code soit propre.
Competences de developpement front-end. Competences de conception UI. Meilleures pratiques React. Regles d'architecture SaaS. Invites de redaction SEO. Listes de verification de securite. Regles de revue de code. Configurations « mode dieu » pour Cursor, Claude Code ou Codex.
Celles-ci ne sont pas inutiles.
Le probleme est qu'elles ne sont pas le meme type de regle.
Le premier type est celui des regles de base externes.
Les controles de securite, les risques d'injection SQL, les risques XSS, les controles d'autorisation, l'idempotence des paiements, la gestion des erreurs API, les bases de l'accessibilite, les bases du SEO, les controles de performance et les rappels de couverture de test entrent dans cette categorie.
Ces regles sont relativement universelles. Elles entrent generalement moins en conflit avec le style du projet, et beaucoup d'entre elles sont des garde-fous de base. Les competences externes, les listes de verification et les meilleures pratiques peuvent etre precieuses ici.
Le deuxieme type est celui des regles natives du projet.
Le style de page, l'utilisation des composants, les jetons de theme, les habitudes d'espacement, les composants de formulaire, le comportement des modales, la structure de routage, l'organisation i18n, la stratification metier, la denomination des donnees, les conventions de dossiers et les limites de reutilisation des composants appartiennent tous a cette categorie.
Ces regles ne devraient pas etre copiees d'Internet en premier lieu.
Leur source la plus importante n'est pas la maniere dont quelqu'un d'autre le fait. C'est comment votre projet fonctionne deja.
La generation de pages front-end est un bon exemple.
Vous voulez que la page ait meilleure allure, alors vous ajoutez des competences front-end externes : style SaaS moderne, aspect premium, glassmorphisme, disposition en cartes, mouvement, forte hierarchie visuelle, meilleures pratiques de landing page.
Chacune de ces pratiques peut etre raisonnable en soi.
Mais si le projet a deja sa propre bibliotheque de composants, ses jetons Tailwind, ses boutons, ses cartes, ses formulaires, ses regles responsives, son style de marque et sa structure de page, ces competences externes peuvent creer des interférences plutôt que des améliorations.
L'IA commence a hesiter :
Doit-elle suivre la competence externe ou les composants existants ? Doit-elle reutiliser la Carte existante ou creer un nouveau design de carte ? Doit-elle ajouter du mouvement pour un aspect premium ou preserver la performance et la coherence ? Doit-elle utiliser la disposition de landing page externe ou suivre la propre architecture d'information du produit ?
Le resultat final peut sembler plus « standard » a un endroit, mais moins coherent dans son ensemble.
Ce n'est pas que l'IA a echoue a suivre les regles. Elle a suivi trop de regles qui n'appartenaient pas a ce projet.
A ce stade, au lieu d'ajouter plus de regles, demandez a l'IA de resumer les vraies regles du projet.
Quels composants sont couramment utilises ? Comment les pages sont-elles generalement structurees ? Les formulaires, modales, boutons et cartes sont-ils ecrits de maniere coherente ? Ou vivent habituellement les cles i18n ? Quelles sont les conventions pour les appels API et la gestion des erreurs ? Quels composants devraient etre reutilises, et quelle logique ne devrait pas etre dupliquee ? Comment les fonctionnalites similaires ont-elles ete implementees recemment ? Quelles habitudes d'ingenierie implicites mais stables le projet a-t-il deja ?
Resumez d'abord tout cela. Ensuite, decidez quelles competences externes meritent d'etre adoptees et lesquelles ne correspondent pas au projet actuel.
Regle pratique : les competences externes sont utiles pour les regles de base telles que la securite, la conformite, la performance, l'accessibilite et le SEO. Pour le style des composants, la stratification metier, la structure des pages et les conventions de denomination, laissez d'abord le modele resumer votre codebase.

L'une des pires façons d'utiliser le codage par IA est de la traiter comme un executeur obeissant.
Vous decidez la solution, puis demandez a l'IA de l'implementer. Elle l'implemente. Mais apres coup, vous realisez que la voie etait fausse depuis le debut.
Cela arrive souvent : vous demandez a l'IA de corriger un probleme, et elle le corrige avec une solution lourde. Vous lui demandez d'ajouter une fonctionnalite, et elle l'ajoute, meme si reutiliser un module existant aurait ete mieux. Vous lui demandez de refactorer un bloc de logique, et elle le fait, mais rate le fait que le vrai probleme est la structure de donnees.
Ce qui rend un grand modele de langage different d'un outil d'automatisation traditionnel est qu'il ne se contente pas d'executer des instructions. Il peut ecrire du code parce qu'il a absorbe une grande quantite de modeles logiciels reels, de projets open-source, de discussions d'ingenierie, de cas d'echec et de meilleures pratiques.
Il sait comment les systemes CMS organisent generalement le contenu. Il sait pourquoi les systemes e-commerce se soucient des etats de commande. Il sait pourquoi l'i18n ne devrait pas etre codee en dur partout. Il sait pourquoi les callbacks de paiement ont besoin d'idempotence. Il sait pourquoi le runtime de la vitrine et l'editeur d'administration ont besoin d'un contrat stable. Il sait aussi pourquoi le SEO, les donnees structurees, les formulaires, les autorisations, les logs et les tests s'affectent mutuellement dans les systemes reels.
Si vous l'utilisez seulement pour transformer votre idee en code, vous laissez beaucoup de valeur inutilisee.
Une meilleure approche est de laisser l'IA explorer les options en se basant d'abord sur le projet image et le contexte du code :
Existe-t-il un modele d'implementation plus mature ? A quelle couche cette fonctionnalite devrait-elle appartenir ? Existe-t-il un modele existant que nous devrions reutiliser ? Quels modules ce changement pourrait-il affecter ? Y a-t-il de la logique dupliquee dans le code actuel ? Une ancienne logique devrait-elle etre supprimee ? Ce besoin est-il meme la bonne solution au probleme ?
Il ne s'agit pas de demander a l'IA de prendre la decision finale.
Il s'agit de demander a l'IA d'elargir l'espace de decision.
L'IA peut proposer des correctifs conservateurs, des refactorisations locales, des abstractions de protocole, la reutilisation de composants existants, la suppression d'ancienne logique, la division en un module separe, ou meme souligner que le besoin actuel n'est peut-etre pas le bon.
Le choix final appartient toujours a l'humain.
Parce que beaucoup de decisions reelles de produit ne sont pas purement techniques. Les produits en phase de demarrage peuvent privilegier la vitesse. Les flux de transaction peuvent privilegier la stabilite. Les pages SEO peuvent privilegier la structure et la capacite d'exploration. Les outils internes peuvent privilegier la maintenabilite. Les pages destinees aux clients peuvent privilegier la confiance et la coherence.
L'IA peut vous montrer des options. Elle ne peut pas prendre la responsabilite du compromis.
Regle pratique : lorsque le chemin d'implementation n'est pas clair, demandez d'abord a l'IA 2 a 3 options, hypotheses, surfaces d'impact et risques. Quand la limite est claire, ensuite decomposez la tâche et laissez-la executer.
---
L'IA est tres douee pour creer un sentiment d'achevement.
Le code est ecrit. L'explication est ecrite. Le resume est ecrit. Les suggestions de test sont ecrites. Meme la note de livraison a l'air professionnelle.
Mais les projets reels ne peuvent pas se fier a « c'est fait ».
Une experience plus realiste ressemble a ceci : le resume a l'air rassurant, mais le diff montre que l'IA a touché quelques fichiers qu'elle n'aurait pas du toucher. La page actuelle fonctionne, mais une autre entree se casse. Vous pensiez qu'elle n'avait changé que le texte, mais les metadonnees, la logique de fallback et les references de composants ont ete modifiees en chemin.
C'est pourquoi la verification ne peut pas etre une pensee apres coup.
Plus l'IA genere rapidement, plus la boucle de regression devient importante. Une fois que la generation devient bon marche, la partie rare n'est plus la production de code. C'est prouver que le code n'a pas casse le systeme.
Une bonne boucle de regression commence avant le changement.
Premierement, demandez a l'IA d'identifier la surface d'impact.
Quels modules, pages, API, types, donnees, SEO, i18n, autorisations, paiements, formulaires, cache ou flux de publication pourraient etre affectes ?
Deuxiemement, pendant l'implementation, demandez a l'IA de suivre la structure existante.
Reutilisez ce qui doit etre reutilise. Suivez les modeles existants autant que possible. Ne creez pas d'implementation parallele a la legere. Ne brisez pas les conventions du systeme juste pour completer une tâche locale.
Troisiemement, apres l'implementation, demandez a l'IA de revérifier les points de regression.
Quelles pages devraient etre verifiees ? Quels chemins devraient etre executes ? Quels tests pourraient echouer ? Quels types necessitent une validation ? Quelle ancienne logique devrait etre supprimee ? Quel comportement de fallback necessite une confirmation ?
Quatriemement, les humains et l'IC doivent verifier le resultat.
Ne lisez pas seulement le resume de l'IA. Lisez le diff. Ne verifiez pas seulement la page. Executez le flux. Ne testez pas seulement le chemin heureux. Testez le chemin d'exception. Ne verifiez pas seulement la langue par defaut. Verifiez le comportement de fallback. Ne verifiez pas seulement qu'un paiement ou un abonnement a ete cree. Verifiez les callbacks, l'annulation, la mise a niveau, la downgrade et les declencheurs en double. Ne verifiez pas seulement si le contenu genere se lit bien. Verifiez s'il correspond a la marque, a l'objectif de la page et a la structure SEO.
C'est aussi pourquoi les grandes entreprises peuvent integrer le codage par IA dans leurs flux de travail de developpement. Pas parce que l'IA ne fait jamais d'erreurs, mais parce qu'elles ont la revue de code, les tests, l'IC/CD, la surveillance, les autorisations, les logs, le rollback et la gouvernance d'ingenierie qui peuvent absorber le changement d'efficacite.
Regle pratique : l'IA genere le resultat. Les humains et l'IC prouvent que le resultat n'a pas casse le systeme. Ce qui doit etre prouve, et comment le prouver, devrait venir du projet image, de la structure du code et de l'analyse d'impact.
---
Si nous commençons par « l'IA est un multiplicateur d'execution, pas le volant », cela semble correct mais un peu vide.
Dans les projets reels, la division du travail est plus specifique.
L'IA est douee pour :
Proposer des options basees sur la connaissance du monde. Tracer l'impact a travers la structure du code. Trouver des implementations en double et des conflits potentiels. Generer des premieres ebauches de code, de tests et de documentation. Expliquer des modules complexes. Aider avec les refactorisations et les migrations. Lister les verifications de regression avant la publication.
Les humains sont meilleurs pour :
Juger des objectifs metier. Confirmer le projet image. Prendre des compromis techniques. Decider si une refactorisation en vaut la peine au stade actuel. Accepter ou rejeter le risque. Decider quelles capacites doivent etre industrialisees. Assumer la qualite finale et l'experience utilisateur.
Il ne s'agit pas de savoir qui remplace qui.
L'IA elargit le jugement ; les humains font les compromis. L'IA augmente la vitesse d'execution ; les humains assurent la direction du systeme. L'IA expose plus de possibilites ; les humains choisissent quelle voie emprunter.
Regle pratique : n'utilisez pas l'IA seulement comme un executeur, et ne laissez pas l'IA decider de la direction. Laissez l'IA elargir les options et l'analyse d'impact ; laissez les humains assumer le jugement d'etape, les compromis metier et la qualite finale.
---
La logique derriere le codage par IA s'etend naturellement aux flux de travail IA du marchand.
Les deux font face au meme probleme sous-jacent :
L'IA a besoin de comprendre le contexte avant de pouvoir executer des tâches utiles.
L'IA a besoin du projet image pour bien ecrire le code. L'IA a besoin du portrait marchand pour generer du contenu utile. L'IA a besoin de la structure de marque, de produit, de page et de conversion pour soutenir le SEO et le GEO.
C'est pourquoi de nombreux marchands utilisent l'IA pour ecrire des textes, construire des pages, generer des FAQ ou rediger des articles, et le resultat a l'air complet mais ne convertit pas.
Le probleme n'est generalement pas que l'IA ne sait pas ecrire.
Le probleme est que l'IA ne sait pas :
Qui est le marchand. Ce qu'il vend. A qui il vend. Pourquoi les clients devraient lui faire confiance. Quel est le travail que la page est censee accomplir. Si le contenu doit generer des demandes de renseignements, des achats ou du trafic de recherche a long terme. A quelles preoccupations reelles la FAQ devrait repondre. Comment les produits, les pages, les formulaires et le SEO sont connectes.
Sans ce contexte, l'IA peut facilement generer un contenu qui ressemble a du texte.
Il peut etre fluide, complet et meme soigne. Mais il manque de jugement metier.
Donc la cle des flux de travail IA du marchand n'est pas de demander aux utilisateurs d'ecrire plus d'invites.
La question la plus importante est de savoir si le systeme peut organiser automatiquement les donnees de marque, de produit, d'objectif de page, de FAQ, de formulaire, de SEO et de chemin de conversion en un contexte de meilleure qualite — afin que l'IA comprenne le marchand et son metier avant d'executer la tâche.
C'est la direction dans laquelle Foundax se concentre lors de la conception des flux de travail IA.
Nous ne considerons pas l'IA comme un bouton « generer » isole. Une approche plus precieuse est d'integrer l'IA dans le flux operationnel du marchand : aider les marchands a organiser le contenu, les pages, les actifs multilingues, le SEO et les documents marketing plus rapidement, tandis que le systeme gere les produits, les formulaires, les paiements, les commandes, la publication et les chemins de conversion.
Dans cette conception, l'IA ne se contente pas « d'ecrire un paragraphe pour vous ».
Elle doit d'abord comprendre :
Ce que la marque represente. Quel probleme le produit ou service resout. Quel travail la page doit accomplir. A quelle preoccupation la FAQ devrait repondre. Quel type de lead le formulaire devrait collecter. Quelle intention de recherche le contenu devrait servir. Si la page doit generer une demande de renseignement, un achat ou une confiance a long terme.
Ensuite, elle peut generer quelque chose d'utile.
C'est la meme logique que le codage par IA.
Ne donnez pas a l'IA seulement une tâche locale. Laissez-la d'abord comprendre l'image. Ensuite, utilisez des donnees structurees, des contrats metier et une injection de contexte pour la placer dans le bon environnement informationnel.
Regle pratique : la cle des flux de travail IA du marchand n'est pas une meilleure invite. Ce sont des donnees structurees, des contrats metier et un contexte de haute qualite qui aident le modele a comprendre la marque et le metier avant de generer des textes, des pages, du contenu multilingue, des actifs SEO ou des documents operationnels.
---
Le SEO traditionnel s'est souvent concentré sur les mots-cles, les titres, les descriptions et les backlinks.
Ceux-ci comptent toujours.
Mais a mesure que la recherche IA et les reponses generatives deviennent plus courantes, une question plus profonde devient plus importante :
Les machines peuvent-elles comprendre qui vous etes ?
Etes-vous un site de marque ou une landing page temporaire ? Que vendez-vous ? Qui servez-vous ? Ou se trouvent vos produits, services, cas clients, FAQ et points de contact ? Y a-t-il une structure entre vos contenus ? Vos pages peuvent-elles etre explorees, comprises et citees ?
C'est le meme probleme sous-jacent que le codage par IA.
Le codage par IA necessite que le modele comprenne la structure du projet. La generation de contenu par IA necessite que le modele comprenne la structure du marchand. Le SEO necessite que les moteurs de recherche comprennent la structure de la page. Le GEO necessite que les systemes de recherche generatifs comprennent la relation entre la marque, les produits, les services et le contenu.
Donc l'avenir ne consistera pas seulement a savoir qui peut generer plus de contenu.
Plus le contenu devient facile a generer, plus la structure devient importante.
Si une marque genere seulement un grand nombre de pages isolees, les moteurs de recherche et la recherche IA voient encore des fragments. Si une marque organise son site web, ses produits, ses services, ses cas clients, sa FAQ, son contenu, ses formulaires, ses chemins de conversion et ses pages multilingues en une structure claire, il devient plus facile pour les utilisateurs, les moteurs de recherche et les systemes d'IA de la comprendre.
Regle pratique : le SEO et le GEO ne sont pas seulement des problemes de production de contenu. Ce sont des problemes de structure. Plus vous organisez clairement la marque, le produit, le contenu, la FAQ et les chemins de conversion, plus il est facile pour les machines et les utilisateurs de vous comprendre.
Si vous construisez le SEO et le GEO pour une vitrine, vous voudrez peut-etre aussi lire : Les Nouvelles Regles du SEO : Gagner le Jeu de la Recherche IA (GEO) en 2026, Comment Faire Apparaitre vos Produits dans ChatGPT et le Mode IA de Google : Un Guide Marchand 2026.
Si vous vous souciez de la façon dont les actifs de marque, le contenu et le SEO fonctionnent ensemble, lisez aussi : Pourquoi 2026 est le Bon Moment pour Construire vos Actifs de Marque Personnelle.
Si vous evaluez des outils de codage IA ou des choix de pile technologique, lisez l'article complementaire : Comment les Marques DTC Multi-Marche Devraient-elles Choisir une Pile E-commerce en 2026 ?.
Si vous voulez l'angle strategie-produit sur pourquoi la livraison web-first compte plus a l'ere de l'IA, lisez : L'IA Va-t-elle Pousser Plus de Produits a Revenir sur le Web en 2026 ?.
Si vous construisez le SEO et le GEO pour une vitrine, continuez a lire : Les Nouvelles Regles du SEO : Gagner le Jeu de la Recherche IA (GEO) en 2026, Comment Faire Apparaitre vos Produits dans ChatGPT et le Mode IA de Google.
Si vous voulez voir comment Foundax integre les flux de travail IA dans les operations marchandes, consultez fonctionnalites.
Pas le code. Pas les competences. Le projet image.
Au minimum, l'IA devrait comprendre cinq choses : l'objectif, les objets, les contraintes, la surface d'impact et la direction future. Sinon, elle traitera les besoins comme des tâches isolees et pourrait produire des resultats localement corrects mais systemiquement faux.
Regle de decision : si l'IA ne peut pas expliquer pourquoi le projet existe, quels sont les objets centraux et quelles contraintes ne doivent pas etre enfreintes, ne lui demandez pas encore d'apporter des modifications majeures au code.
---
Commencez par le portrait metier, puis evaluez la convivialite pour l'IA.
Si le produit implique du contenu, des pages, du SEO, des operations d'administration, des transactions, des formulaires, des paiements et un support multilingue, il a generalement besoin de frameworks matures, de types clairs, de bases de donnees stables, d'ecosystemes de paiement matures et de flux de travail d'ingenierie verifiables.
Une pile conviviale pour l'IA n'est pas la pile la plus recente. C'est une pile que les modeles ont souvent vue, que les humains peuvent verifier, que les types peuvent contraindre et pour laquelle la communaute a des modeles solides.
Regle de decision : ne demandez pas seulement si la technologie est nouvelle. Demandez si elle correspond au metier, si l'IA peut la comprendre, si l'equipe peut la verifier et si la maintenance a long terme est gerable.
---
Oui, si le projet devient plus bruyant.
Mais si le projet devient plus structure, l'IA peut en fait devenir plus facile a utiliser. Les dossiers, les types, les schemas, les adaptateurs, les tests, la denomination et la documentation peuvent progressivement devenir le manuel d'utilisation du modele.
Le vrai probleme n'est pas la taille du projet. C'est le bruit contextuel.
Regle de decision : a mesure que le projet grandit, reduisez le bruit contextuel avant d'augmenter l'automatisation par IA.
---
Pas necessairement.
Des besoins detailles peuvent ameliorer la precision d'une tâche unique, mais ils ne garantissent pas la correction du systeme. Un meilleur besoin ne devrait pas seulement dire quoi faire. Il devrait aussi expliquer pourquoi la tâche existe, quel est l'etat cible du systeme et comment verifier que rien n'a ete casse.
Regle de decision : les details locaux de la tâche sont utiles, mais ils doivent etre accompagnes de l'objectif, de l'etat du systeme et des criteres d'acceptation.
---
Pas au debut.
Les regles, les competences et les meilleures pratiques sont utiles, mais elles doivent etre separees par type. Les competences externes sont utiles pour les regles de base telles que la securite, la conformite, la performance, l'accessibilite et le SEO. Mais les regles natives du projet telles que le style des composants, la stratification metier, la structure des pages et les conventions de denomination devraient d'abord etre resumees a partir du codebase.
Regle de decision : utilisez les competences externes pour les risques de base universels. Utilisez le codebase lui-meme pour deriver le style du projet et la structure metier.
---
Demandez a l'IA d'identifier la surface d'impact avant l'execution, d'implementer en suivant la structure existante, de reverifier les points de regression apres l'execution, puis laissez les humains et l'IC verifier le resultat.
La regression n'est pas seulement un probleme de test final. C'est un probleme de flux de travail base sur le projet image, la documentation du code et l'analyse d'impact.
Regle de decision : avant chaque changement, demandez ce qu'il pourrait affecter. Apres chaque changement, demandez ce qu'il a pu casser.
---
Parce que « les grandes entreprises utilisent le codage par IA » et « le code genere par l'IA peut etre livre sans revue » sont deux choses differentes.
Google a declare que 75 % du nouveau code est genere par l'IA, mais il est toujours revu par des ingenieurs. Le chiffre de 20 a 30 % de Microsoft ne signifie pas non plus que la revue de code, les tests et la gouvernance de qualite disparaissent.
Le Stack Overflow Developer Survey 2025 montre que la confiance des developpeurs dans la precision des resultats de l'IA reste limitee. L'etude de METR montre egalement que dans les codebases matures, les outils d'IA peuvent ralentir les developpeurs en raison des couts de comprehension, d'attente, de verification et de correction.
Regle de decision : le codage par IA merite d'etre integre dans les flux de travail reels, mais il doit etre accompagne de mecanismes de revue, de test, de validation et de rollback.
---
Les deux sont des problemes de contexte.
L'IA a besoin du projet image pour ecrire du code. L'IA a besoin du portrait marchand pour ecrire des textes, construire des pages, generer des FAQ et soutenir le SEO.
Si le systeme ne peut pas organiser la marque, le produit, les objectifs de page, la FAQ, les formulaires, le SEO et les chemins de conversion, l'IA ne peut generer qu'un contenu qui a l'air complet mais qui manque de jugement metier.
Regle de decision : la cle des flux de travail IA du marchand n'est pas plus d'invites. C'est un contexte structure de meilleure qualite.
---
Le codage par IA est deja dans les flux de travail reels de developpement.
Mais cela ne signifie pas que le logiciel peut etre genere a la legere, ou que le jugement produit peut etre confie a un modele.
Dans les projets reels, la valeur de l'IA n'est pas de remplacer le jugement. C'est d'elargir le jugement.
Mais cela ne fonctionne que si l'IA comprend d'abord le systeme.
Donc la bonne sequence n'est pas de demander a l'IA d'ecrire plus de code.
C'est :
Construire le projet image. Choisir une pile qui correspond au metier et soutient la collaboration avec l'IA. Transformer la structure du code en documentation. Laisser l'IA comprendre l'amont, l'aval et l'impact a travers cette structure. Ensuite, traiter les tâches specifiques, choisir les competences avec soin et construire une boucle de regression. Enfin, les humains assument les compromis et la qualite finale.
Cette logique s'applique au developpement logiciel. Elle s'applique aussi aux marchands qui utilisent l'IA pour ecrire des textes, construire des pages, soutenir le contenu multilingue et ameliorer le SEO. Elle s'applique aussi au GEO et a la construction d'actifs de marque a long terme.
La prochaine phase du codage par IA n'est pas de faire ecrire plus a l'IA.
C'est de faire travailler l'IA a l'interieur du bon systeme.
---