DTC-Sites vs Marktplätze im agentischen Commerce
Ein praktischer Leitfaden, um Marktplätze zu nutzen und parallel einen DTC-Kanal mit Produktdaten, Kundenbeziehung, Content und Messung aufzubauen.
Weiterlesen
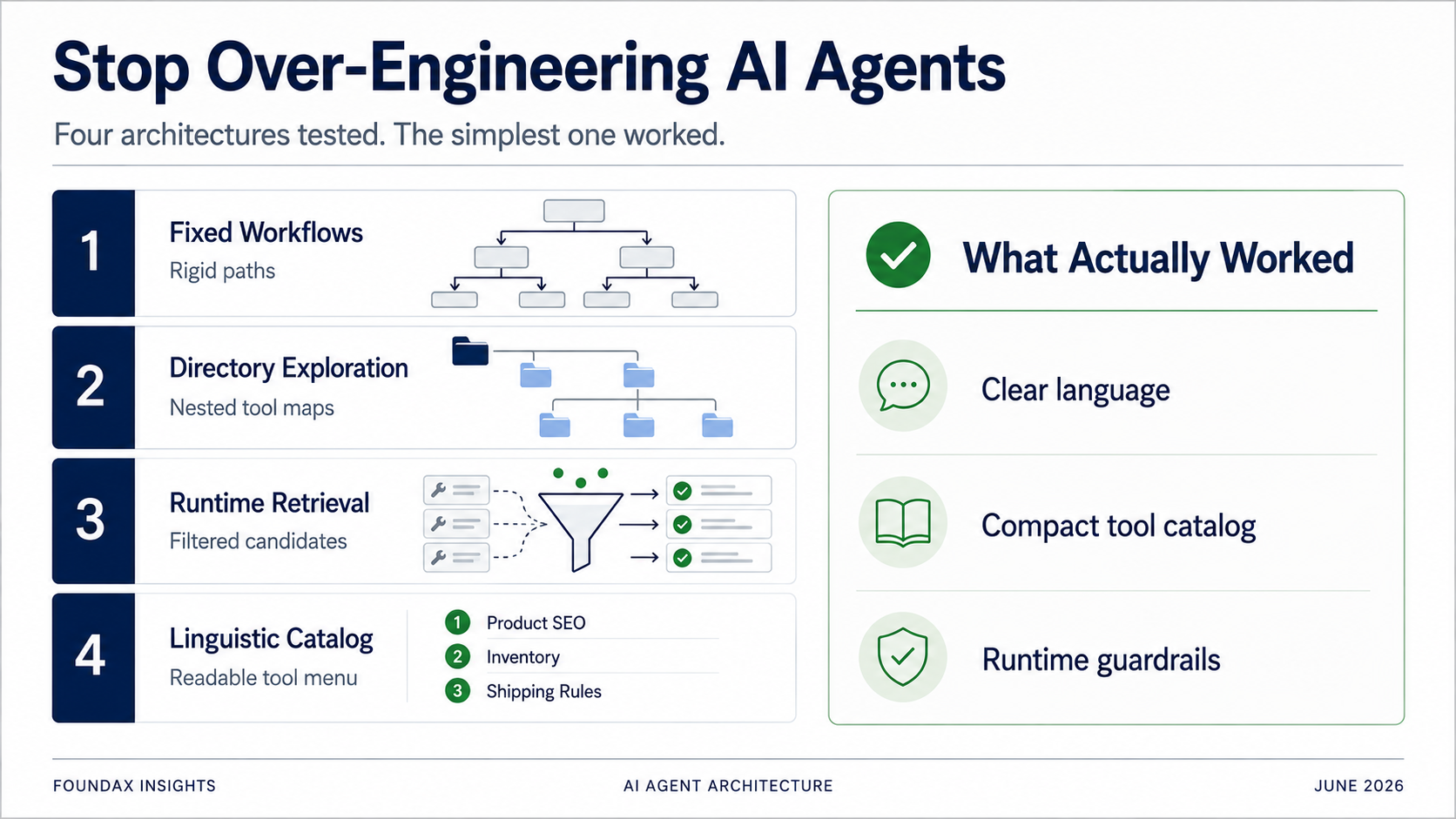
Vom festen Workflow über Verzeichnis-Exploration bis zum Runtime Retrieval: Jede »Optimierung« war im Grunde wir, die dem Modell seine Arbeit abnahmen. Die beste Architektur war die, die aufhörte, schlauer sein zu wollen als das Modell.
Beim Bau des Foundax Agent gab es einen absurden Moment, an den ich immer wieder zurückdenke.
Wir haben vieles ausprobiert. Fixe Workflows. Verzeichnisbasierte Tool-Erkundung. Skill-basierte Tool-Empfehlungen. Runtime Retrieval. Regex-Matching. Strukturierte Pläne. Multi-Round ReAct-Loops. Zwischendurch haben wir sogar ernsthaft über Embedding-basiertes Retrieval nachgedacht.
Jede Version ergab auf dem Papier Sinn.
Zu viele Tools – also müssen wir filtern. Das Modell übersieht Dinge – also müssen wir einschränken. Der Context ist zu lang – also müssen wir retrieven. Die Ausführung muss sicher sein – also müssen wir prozeduralisieren. Geschäftliche Präzision verlangt atomare Bottom-Layer-Tools.
Für sich genommen war keines dieser Urteile falsch.
Dann machten wir den einfachsten – fast schon primitiven – Test: Alle Tools in einen kompakten, sprachlichen Katalog pressen, dem Modell vorwerfen und es selbst lesen und auswählen lassen.
Das Ergebnis war verblüffend gut.
Ich war ehrlich sprachlos.
Denn es bedeutete: Die meisten unserer komplexen Entwürfe haben die Fähigkeiten des Modells nicht freigesetzt. Sie haben unterstellt, das Modell würde versagen – und es dann mit Architekturschichten ummantelt, um das zu kompensieren.
Dieser Artikel sagt nicht: „Alle Tools ungefiltert exponieren ist die Best Practice."
Was ich wirklich sagen will: Die größte Gefahr beim Bau eines Business-Agenten ist nicht, dass das Modell nicht schlau genug ist – sondern dass du anfängst, einen Käfig zu bauen, bevor du überhaupt getestet hast, was es in deiner Domäne leisten kann.
Foundax ist eine E-Commerce-SaaS-Plattform.
Der Foundax Agent hat es also nicht mit lockerem Geplauder oder allgemeinen Wissensfragen zu tun. Er begegnet den echten operativen Problemen, mit denen Händler in ihrem Backend konfrontiert sind.
Händler sagen nicht:
„Bitte rufe die Product-Variant-Read-API auf."
Sie sagen:
„Warum verkauft sich dieses Produkt nicht?"
„Ist meine spanische Seite schon eingerichtet?"
„Kann dieses Produkt auf Google Shopping laufen?"
„Warum legen Leute in den Warenkorb, zahlen aber nicht?"
„Ergänze meine fehlenden SEO-Daten."
Diese Fragen klingen nach natürlicher Sprache – aber hinter jeder steht ein komplettes Geschäftssystem. Produkte, SKUs, Lagerbestände, Preise, SEO, Übersetzungen, Aktionen, Versand, Zahlung, Checkout, Bestellungen, Retouren, GMC-Feeds, Storefront-Anzeigestatus – jeder dieser Faktoren kann das Ergebnis beeinflussen.
Das Ziel des Foundax Agent ist also nicht, „menschlich zu klingen."
Was er wirklich können muss: die tatsächliche Absicht des Händlers verstehen, die relevanten Fakten im System finden, die richtigen Tools auswählen, bei Bedarf Schreibvorgänge vorbereiten und unter Runtime-Constraints ausführen – mit Berechtigungen, Bestätigung und Readback.
Die Benutzereingabe darf unscharf sein. Die Systemausführung muss präzise sein.
Diese Spannung ist der Ausgangspunkt für jedes architektonische Dilemma, das folgt.
Ich habe einen ausgeprägten Hang zum Engineering-Perfektionismus.
Als ich den Foundax Agent entwarf, lehnte ich grob granulare Tools instinktiv ab.
Ein Tool namens analyzeProductReadiness klingt praktisch. Aber welche Felder liest es intern? Welche Kriterien legt es an? Wo liegen die Berechtigungsgrenzen? Kann man nach einem Schreibvorgang ein Readback machen? All das wird undurchsichtig.
Foundax ist keine Demo. Wenn ein Händler dich bittet, seine SEO zu korrigieren, kannst du nicht einfach ein Black-Box-Tool im Hintergrund Dinge ändern lassen.
Also bestand ich auf atomaren Bottom-Layer-Tools:
Produktbasisfelder lesen. Produktvarianten lesen. Bestand und Preise lesen. Produkt-SEO lesen. Produktübersetzungen lesen. Versandkonfiguration lesen. Zahlungskonfiguration lesen. Ein bestimmtes Feld schreiben. Inhalte für eine bestimmte Locale schreiben. Einen Änderungsentwurf generieren. Readback nach Schreibvorgang.
Jedes Tool mit einer einzigen Aufgabe, sauber, überschneidungsfrei. Präzise Ausführung, klare Berechtigungen, einfach zu testen.
Ich halte dieses Urteil immer noch für richtig.
Das eigentliche Problem war ein anderes: Je atomarer deine Bottom-Layer-Tools, desto mehr Tools hast du. Je mehr Tools du hast, desto schwerer fällt es dem Modell, sie im Context zu verstehen und auszuwählen.
Das war das erste Paradoxon.
Je besser ein Bottom-Layer-Tool zur Systemausführung passt, desto schlechter passt es zur kognitiven Schnittstelle des Modells.
Atomizität war nicht der Fehler. Der Fehler war, dem Modell einen Haufen atomarer Werkzeuge direkt vor die Füße zu kippen und zu erwarten, dass es jedes Mal zuverlässig die richtigen auswählt.
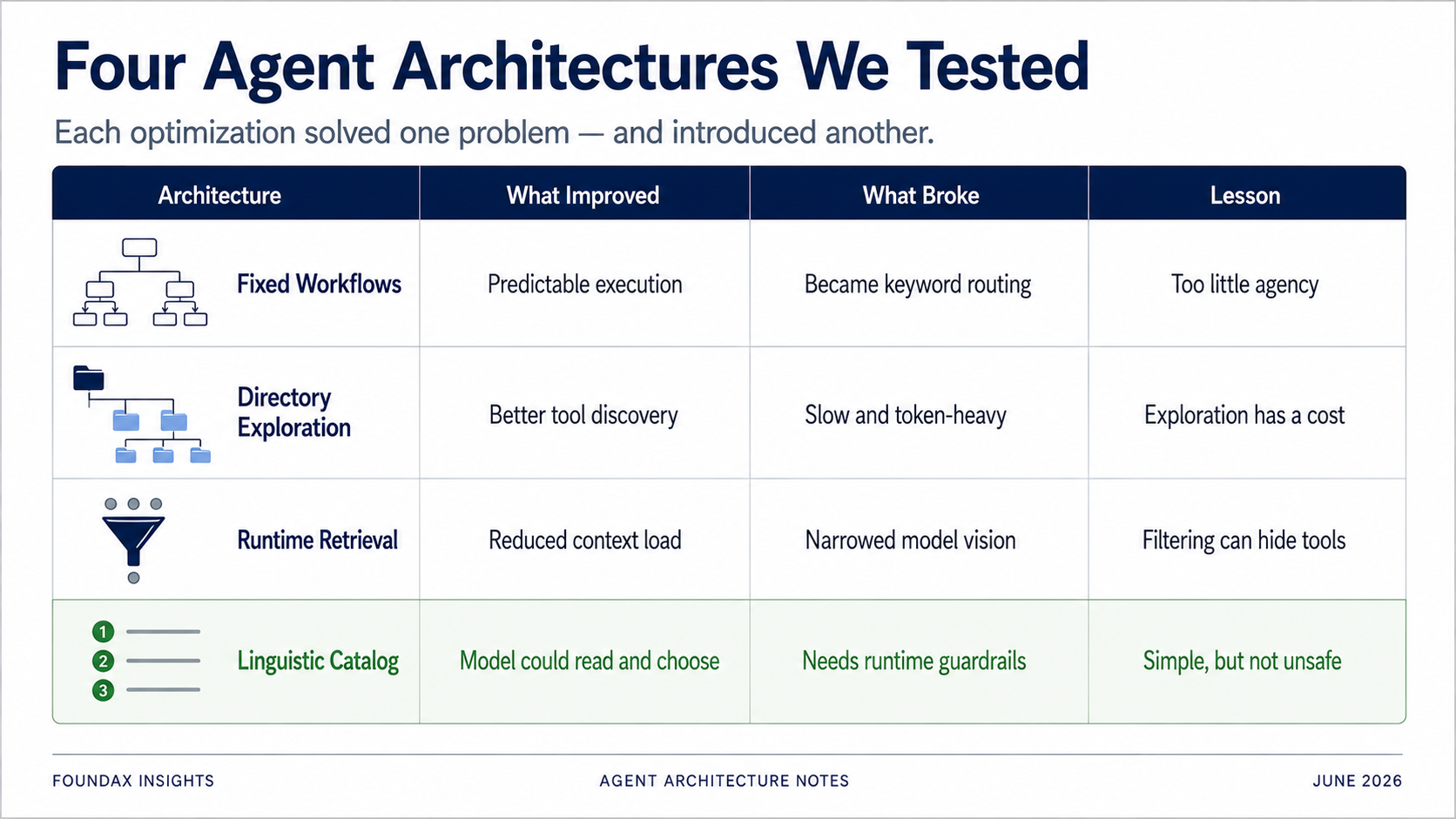
Um das Tool-Auswahlproblem zu lösen, war unser erster Ansatz: fixe Workflows.
Ein naheliegender Instinkt. Wenn die hochfrequenten Aufgaben der Händler endlich sind, skripten wir sie vor.
Produkt-SEO-Check. Übersetzungsabdeckungs-Check. Produkt-Launch-Readiness-Check. Diagnose niedriger Conversion. GMC-Readiness-Check.
Aufgabe des Modells: Benutzerabsicht erkennen, einem Workflow zuordnen, dann an die Runtime zur fixen Ausführung übergeben.
Das sah sicher aus. Das sah durchdesigned aus.
Aber im Test degenerierte es schnell zu einem dummen Keyword-System.
Der sprachliche Ausdruck von Nutzern ist viel zu variantenreich. Einer sagt: „Ist meine SEO vollständig?" Ein anderer: „Kann Google diese Seite indexieren?" Ein dritter: „Hab ich den Produkttitel vermurkst?" Ein vierter: „Warum schlägt mein Feed bei Ads immer fehl?"
Damit jede Variante eine Aufgabe trifft, fügst du ständig Keywords, Aliase, Regeln hinzu. Irgendwann ist das System weder treffsicher, noch ist es wartbar.
Schwerwiegender: Das Modell hatte kaum noch Spielraum. Es war nur noch ein Intent-Classifier. Der eigentliche Analysepfad, die Tool-Auswahl, die Evidenz-Erhebung – alles von uns vorbestimmt.
Da traf mich die Erkenntnis:
Wenn jede Aufgabe in einen Workflow vorgescriptet ist, ist das Ding kein Agent mehr – es ist ein Workflow-Tool im AI-Kostüm.
Fixe Workflows ersetzen im Kern modellbasiertes Reasoning durch menschliche Business-Enumeration. Sie machen das System kontrollierbarer – aber sie nehmen dem Agenten seine Agency.
Also schwenkten wir um.
Statt alle Tools auf einmal zu exponieren: in einem Verzeichnis organisieren. Das Modell wählt zuerst eine Business-Domäne, expandiert dann Unterverzeichnisse, wählt dann spezifische Tools.
Produkte. Bestellungen. Zahlungen. Versand. Aktionen. Analytics. GMC.
Unter „Produkte": Basisinformationen, SKUs, Bestand, Preise, SEO, Übersetzungen.
Das war deutlich treffsicherer als fixe Workflows. Das Modell matchte keine Keywords auf vordefinierte Pfade – es erkundete eine strukturierte Tool-Landkarte. Es fand tatsächlich öfter die richtigen Tools.
Aber das Problem war offensichtlich: Geschwindigkeit.
Jede Aufgabe erforderte eine Verzeichnis-Traversierung. Selbst einfache Fragen durchliefen die gesamte Erkundungskette. Token-Verbrauch hoch. Latenz hoch.
Ein Händler fragt: „Ist die SEO dieses Produkts vollständig?" – und der Agent verhält sich, als blättere er durch ein dickes Backend-Handbuch.
Die Verzeichnis-Exploration war richtungsmäßig nicht falsch. Das Problem: Sie machte das „Verstehen des Tool-Systems" zu Kosten pro Aufruf. Das Modell musste das System bei jedem einzelnen Aufruf von Grund auf neu erkunden. Das ist als Produkterlebnis schwer zu akzeptieren.
Als Nächstes bauten wir etwas Anspruchsvolleres.
Das Modell erzeugt zuerst ein strukturiertes Verständnis des User-Prompts: Intent-Dekomposition, Keywords, involvierte Business-Domänen, und ob die Aufgabe Read, Write, Mixed oder Unknown ist.
Dann geht dieser Plan an die Runtime. Die Runtime nutzt Skills, Regex-Matching und Tool-Metadaten, um Kandidaten-Tools zu retrieven. Das Modell wählt aus den Kandidaten. Nach dem Lesen der Fakten kann das Modell entscheiden, ob es in einer weiteren Runde weiter exploriert.
Diese Version sah aus wie eine ausgereifte Agent Runtime. Und sie brachte tatsächlich echte Fortschritte.
Wir entdeckten zum Beispiel, dass strukturierte Felder das Modellverhalten verbessern können. Um zu verhindern, dass das Modell das erste relevant aussehende Tool greift, ohne die gesamte Kandidatenliste gelesen zu haben, entwarfen wir ein Feld wie hasreadalltools – das Modell sollte explizit erklären müssen, ob es alle Kandidaten gelesen hatte, bevor es einen Tool Call machte. Das half tatsächlich.
Noch interessanter war aber: Wir fanden später heraus, dass eine einzige, gut geschriebene Natural-Language-Anweisung effektiver sein kann als ein komplexes strukturiertes Feld.
Bevor das Modell Tools auswählte, fügten wir hinzu:
„Wähle basierend auf dem Geschäftsziel des Nutzers alle notwendigen Analyse- und Schreib-Tools aus. Greif nicht einfach das erste Tool, das relevant aussieht."
Bevor das Modell eine Antwort ausgeben wollte, fügten wir hinzu:
„Beeil dich nicht mit der Antwort. Prüfe zuerst, ob die benötigten Fakten vollständig sind. Falls nicht, wähle weitere Tools."
Diese einfachen Prompts verbesserten die Reasoning-Tiefe des Modells signifikant.
Das war ein wichtiger Weckruf:
Ein LLM ist kein traditionelles Programm. Strukturierte Protokolle sind nützlich, aber das Modell liest immer Sprache und imitiert Reasoning. In den meisten Fällen funktioniert eine präzise, direkte, wenig mehrdeutige Natural-Language-Anweisung besser als ein komplexes strukturiertes Feld.
Aber auch diese Architektur legte ein tieferes Problem offen.
Runtime Tool Retrieval war darauf ausgelegt, Context-Überlast und ungenaue Tool-Auswahl zu lösen. Aber eine Runtime ist im Kern ein Regelwerk.
Ob Regex, Skills, Keywords oder Domain-Filter – sie kann bereits im ersten Durchlauf Tools herausfiltern, die das Modell tatsächlich braucht.
Stell dir einen Händler vor, der fragt: „Warum verkauft sich dieses Produkt nicht?"
Diese Frage könnte Analytics betreffen. Sie könnte aber auch Produktinhalte, Preisgestaltung, Bestand, Aktionen, Versand, Zahlung, Checkout, Traffic-Quellen, Geografie, Gerätetyp, SEO, Page-Copy-Authentizität betreffen.
Wenn die Runtime die Frage voreilig in eine einzelne Domäne einsortiert, wird das Sichtfeld des Modells eingeschränkt.
Das ist das dritte Paradoxon:
Runtime Tool Retrieval spart Context – kann aber auch zur Decke des modellseitigen Sichtfelds werden.
Wir wollten die Last des Modells verringern und schränkten am Ende potenziell sein Urteilsvermögen ein.
Als die Tool-Anzahl wuchs, erwog ich ernsthaft Embedding-basiertes Retrieval.
Die Idee liegt nahe: User-Prompt → Vektor. Tool-Beschreibungen → Vektoren. Similarity-Score. Top-k ans Modell.
Klingt nach Standard. Klingt „AI-nativ."
Aber je länger ich darüber nachdachte, desto falscher fühlte es sich an.
Für Ad-Retrieval, Content-Empfehlungen oder massive Dokumentensuche machen Embeddings Sinn. Die Kandidatenmenge ist riesig, und traditionelle Systeme können Sprache wirklich nicht verstehen. Du musst Semantik in Vektoren komprimieren, um approximativ zu matchen.
Aber Foundax' Tools sind keine Millionen unbekannter Dokumente in einer offenen Welt. Sie sind endliche, aufzählbare, beschreibbare, komprimierbare Geschäftsfähigkeiten innerhalb unseres eigenen Systems.
Und die größte Stärke des LLM ist genau: Sprache lesen, Sprache verstehen, Semantik vergleichen, Absicht beurteilen.
Warum also Tool-Beschreibungen in Vektoren umwandeln und dann per Similarity-Score entscheiden – stellvertretend für das Modell –, was es zu sehen bekommt?
Es ist, als hättest du ein Buch mit einem perfekt lesbaren Inhaltsverzeichnis. Statt es zu lesen, codierst du das Verzeichnis in Zahlen und lässt den Leser anhand numerischer Distanz beurteilen, welches Kapitel er lesen soll.
Das ergibt in traditionellen Suchsystemen Sinn. In einem LLM-nativen Agenten halte ich es zunehmend für einen Umweg.
Für einen Business-Agenten wie Foundax ist die Priorität nicht Vektor-Retrieval. Es ist Sprachkompression – Tools, Dokumente, Fähigkeiten und Grenzen in klaren, präzisen, hochdichten sprachlichen Context zu komprimieren, den das Modell direkt lesen kann.
Wir stießen auch auf ein weiteres klassisches Problem: Die Tool-Exposition war zu schwergewichtig.
Anfangs exponierte jedes Tool sehr vollständige Informationen ans Modell: Funktionsname, lange Beschreibung, Fact-Scope, Answer-Boundary, ausgeschlossene Quellen, Feld-Enums, Detail-Level-Enums, Argumentbeschreibungen, Observation-Return-Format.
Sieht nach gründlichem Engineering aus.
Aber ich erkannte schließlich: Das meiste davon muss das Modell gar nicht wissen.
Wenn die tatsächliche Query-Ausführung, Feldvalidierung, Berechtigungsprüfung, Owner-Executor-Grenzen, Confirmation-Flows und Readback alle von der Runtime gehandhabt werden, dann hat das Modell kein Geschäft damit, bei jedem Aufruf das vollständige API-Schema zu lesen.
Was das Modell tatsächlich wissen muss:
Zum Beispiel:
Das reicht aus.
„Read / Write / Search"-Präfixe in der Kandidatenliste genügen dem Modell bereits, um Aktionstypen zu unterscheiden. Die tatsächlichen Lese-/Schreibberechtigungen, Confirmation-Flows, Owner-Executor-Grenzen – diese müssen innerhalb der Runtime bleiben und bei der Ausführung durchgesetzt werden. Verschwende keine Tokens dafür, dass das Modell sie liest. Und verlass dich erst recht nicht darauf, dass das Modell freiwillig Regeln befolgt.
Das Fazit hier:
Schema ist für die Runtime, nicht für das Modell. Das Modell sollte einen sprachlichen Fähigkeitskatalog sehen, kein API-Wörterbuch.
Schließlich machten wir den einfachsten Test.
Alle Tools als extrem komprimierte sprachliche Beschreibungen ans Modell. Das Modell lesen lassen. Das Modell auswählen lassen.
Das Ergebnis war verblüffend gut.
Ehrlicherweise war dieses Ergebnis eine kleine Ohrfeige. Denn jede komplexe Architektur, die wir zuvor gebaut hatten, war in einer Annahme verankert: Das Modell verträgt es nicht, zu viele Tools zu sehen, also muss die Runtime für es filtern.
Aber der Test zeigte: Diese Annahme hält – zumindest in Foundax' aktuellem Context – nicht vollständig.
Die Frage ist nicht: „Können alle Tools exponiert werden?" Die Frage ist: „Was genau exponierst du dem Modell?"
Wenn du eine Wand aus vollständigen API-Schemas exponierst – lange Beschreibungen, Feld-Enums, Parameterspezifikationen – wirst du das Modell mit Sicherheit ertränken. Aber wenn du einen leichten, klaren, sprachlichen Fähigkeitskatalog exponierst, kann das Modell selbst lesen und auswählen – und es macht das unter Umständen besser als das Pre-Filtering der Runtime.
Das ist keine Rückkehr zur kruden Voll-Exposition vom Anfang.
Der Anfang war: das vollständige API-Wörterbuch auf das Modell kippen.
Das Ende war: dem Modell ein komprimiertes Betriebshandbuch in die Hand geben – ein leichtgewichtiges, nummeriertes, sprachliches Fähigkeitsmenü.
Das sind fundamental verschiedene Dinge. Das eine ist ein Tool-Ozean. Das andere ist eine lesbare Landkarte.
Konkret: Unser System hat Dutzende Read-Tools und Write-Commands – über hundert kanonische Tools insgesamt. Pro Aufgabe werden höchstens etwa ein Dutzend Tools ans Modell exponiert, kontrolliert durch ein Exposure-Budget. Die Tool-Selection-Phase hat ein Context-Budget von mehreren Zehntausend Zeichen. Jede Tool-Schema-Beschreibung umfasst etwa tausend Zeichen (einige hundert Tokens). Ein Dutzend Tools zu exponieren bedeutet etwa zehn- bis zwanzigtausend Zeichen – rund viertausend bis fünftausend Tokens. Sehr handhabbar.
Aber wenn wir alle Tools mit vollständigen Schemas exponiert hätten? Das wären fast zweihunderttausend Zeichen – etwa fünfzigtausend Tokens. Das würde wirklich nicht passen.
Die entscheidende Einsicht: Die Runtime liefert kompakte, nummerierte Tool-Signaturen aus der kanonischen Registry. Das Modell liest eine Karteikarte, keinen Enzyklopädie-Eintrag.
Es wäre leicht, das misszuverstehen.
Heißt „das Modell lesen und auswählen lassen", dass die Runtime unwichtig ist?
Das Gegenteil ist der Fall.
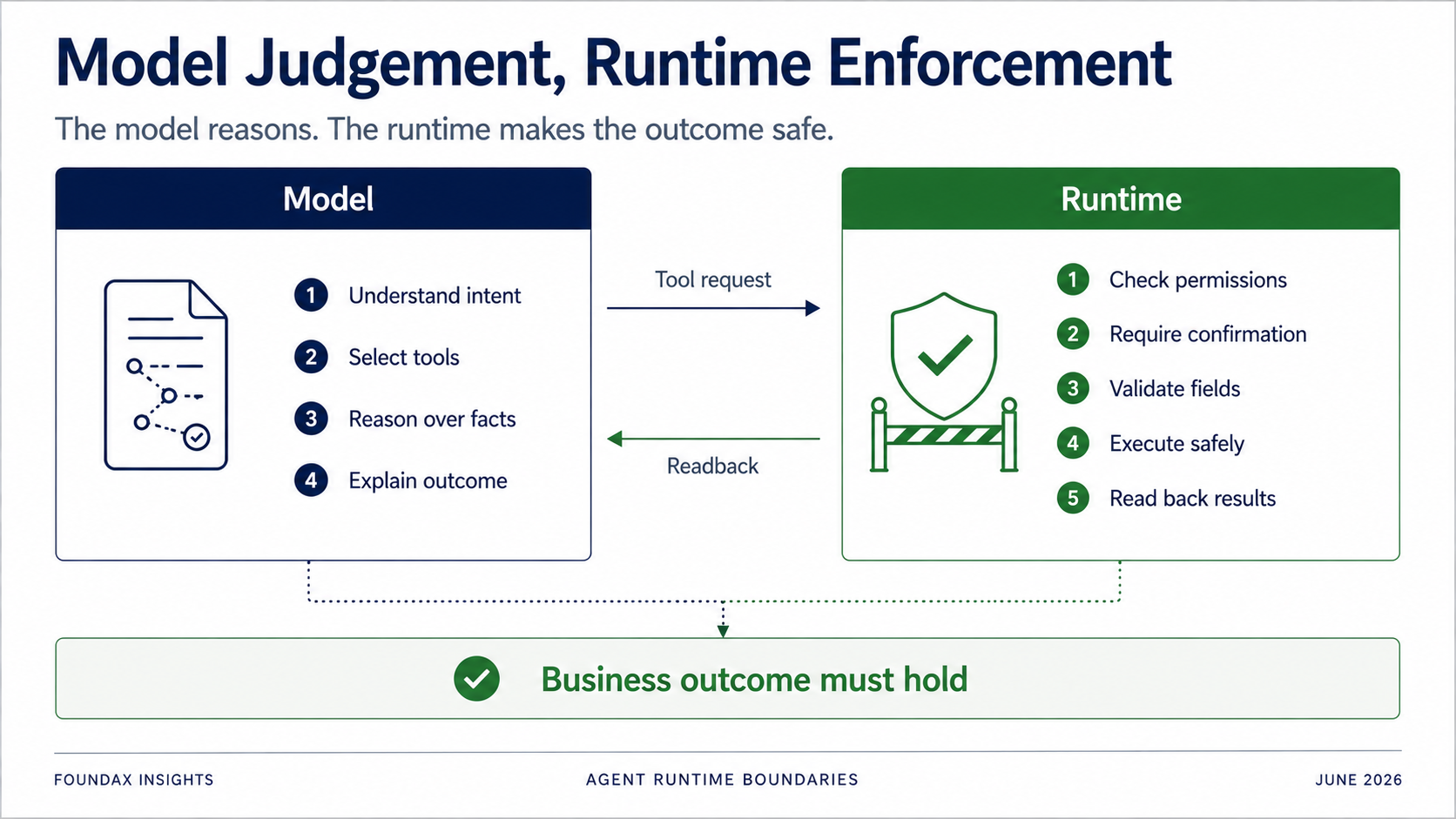
Die Runtime bleibt kritisch – sie darf nur nicht voreilig für das Modell denken.
Das Modell ist verantwortlich für Verstehen, Beurteilen, Auswählen und Erklären.
Die Runtime ist verantwortlich für Berechtigungen, Bestätigung, Feldvalidierung, Owner-Executor-Grenzen, tatsächliche Ausführung und Readback.
Besonders bei Schreiboperationen: Du kannst dich absolut nicht darauf verlassen, dass das Modell freiwillig Regeln befolgt.
Das Modell kann sagen: „Ich möchte die SEO dieses Produkts aktualisieren."
Aber die Runtime muss bestimmen: Hat der aktuelle Benutzer die Berechtigung? Erfordert diese Aktion eine Bestätigung? Sollte erst nur ein Entwurf generiert werden? Ist das Feld auf der Allowlist? Gehört das Objekt zum aktuellen Händler? War der Schreibvorgang tatsächlich erfolgreich? Stimmt nach dem Readback der Geschäftszustand wirklich mit dem Ziel überein?
Das Ziel des Agenten ist nicht, zu beweisen, dass ein Tool Call erfolgreich war. Es ist, zu beweisen, dass das Geschäftsergebnis Bestand hat.
Diese Grenze ist essenziell. Nicht alles gehört ins Modell, und nicht alles gehört in die Runtime. Die eigentliche Frage ist die der Arbeitsteilung.
Die wichtigste Erkenntnis aus dieser Reise ist nicht, dass 4.0 definitiv die beste Architektur ist.
Sondern dass es beim Bau eines Agenten gefährlich leicht ist, sich von einer Kette realer Engineering-Sorgen mitreißen zu lassen.
Sorge, dass High-Frequency-Tasks nicht stabil sind, wenn das Modell jedes Mal improvisiert? → Baue fixe Workflows.
Sorge, dass der Context zu lang ist und das Modell unter Attention-Dilution leidet? → Baue Verzeichnis-Exploration.
Sorge, dass wachsende Tool-Zahlen die Tokens explodieren lassen? → Baue Runtime Retrieval.
Sorge, dass Keyword-basiertes Retrieval für mehrsprachige und domainübergreifende Aufgaben zu spröde ist? → Erwäge Embeddings, Scoring, Reranking.
Sorge, dass das Modell Tools auswählt, ohne die vollständige Liste zu lesen, oder Antworten ausgibt, bevor Fakten vollständig sind? → Füge strukturierte Constraint-Felder hinzu.
Keine dieser Sorgen ist eingebildet. Sie alle entsprechen realen Problemen.
Wir haben nur – auf die harte Tour – festgestellt, dass viele Lösungen ein Problem lösen und ein anderes einführen.
Fixe Workflows brachten Stabilität, aber deckelten das modellseitige Reasoning. Verzeichnis-Exploration war treffsicher, aber langsam und token-intensiv. Runtime Retrieval sparte Context, konnte aber Tools blockieren, die das Modell brauchte. Embeddings sahen smart aus, waren aber für LLM-native Tool-Auswahl wahrscheinlich ein Umweg. Strukturierte Felder konnten das Modell einschränken, aber manchmal funktionierte ein Natural-Language-Prompt besser.
Und die noch wichtigere Erkenntnis:
Diese Probleme sind real – aber sie sind in deinem Projekt nicht notwendigerweise gleich schwerwiegend.
Verursacht langer Context bei deinem Use Case tatsächlich Attention-Dilution? Teste es. Machen deine Tool-Zahlen die Token-Kosten wirklich inakzeptabel? Teste es. Macht vollständige Tool-Exposition dein Modell tatsächlich träge, pfadabhängig oder fehleranfällig? Teste es. Blockiert Runtime Retrieval tatsächlich Tools, die dein Modell braucht? Teste es ebenfalls.
Der einfachste Fehler in der Agent-Architektur ist: „Probleme, die in jemand anderem Projekt real existieren" mit „Problemen, die in deinem definitiv existieren" gleichzusetzen.
Der erste Schritt beim Bau eines Agenten ist also nicht, eine komplexe Architektur zu entwerfen, die jedem möglichen Problem zuvorkommt. Der erste Schritt ist Testen:
Was kann das Modell in deiner Domäne tatsächlich verstehen? Kann es deine Tool-Beschreibungen lesen? Kann es Tools selbstständig auswählen? Wo übersieht es Fakten? Welche Entscheidungen kannst du ihm überlassen? Welche muss die Runtime erzwingen? Welche Aktionen erfordern Benutzerbestätigung? Welche Ergebnisse müssen per Readback verifiziert werden?
Die Antworten auf diese Fragen – nicht eine Referenzarchitektur aus einem Blogpost – sollten das Design deines Agenten bestimmen.
Für Foundax haben wir jetzt Klarheit: E-Commerce-Operationen sind eine Domäne, die das Modell gut kennt. Conversion-Funnels, Produktseiten, Preisgestaltung, Versand, Aktionen, Zahlung, Traffic-Qualität, SEO – diese Analyse-Frameworks erscheinen unzählige Male in den Trainingsdaten. Dem Modell fehlt es nicht an Business-Analyse-Instinkt. Was ihm fehlt, ist Kenntnis des spezifischen Foundax-Systems: welche Fakten es lesen kann, welche Schreibvorgänge es vorbereiten kann, welche Aktionen die Runtime besitzen muss, welche Ergebnisse per Readback verifiziert werden müssen.
Beim Foundax Agent geht es also nicht darum, dem Modell beizubringen, wie man E-Commerce-Analysen macht. Es geht darum, dem Modell Foundax' Geschäftsfähigkeiten in einer Sprache zu überreichen, die es lesen kann.
Der erste Schritt beim Bau eines Business-Agenten ist nicht, eine perfekte Architektur zu entwerfen. Es ist, zu testen, wie weit du dem Modell tatsächlich vertrauen kannst.
Wir sind nicht die Einzigen, die zu diesen Schlüssen kommen.
Im Dezember 2024 veröffentlichte Anthropic seinen Leitfaden "Building Effective Agents". Die Kernbotschaft: Einfachheit gewinnt. Fang mit der einfachsten möglichen Lösung an. Ein augmentiertes LLM mit Tool-Zugriff kann alles sein, was du brauchst. Als ich es damals las, nickte ich. Nachdem ich das oben Beschriebene durchlebt habe, verstehe ich es mit jeder Faser.
Dann, im Mai 2026, hielt LangChain seine Interrupt-Konferenz mit einem bemerkenswerten Schwenk: Das Thema verschob sich von „Können Agenten in Produktion gehen?" zu „Enterprise-Skalierung und Produktionsbetrieb." Der eigentliche Engpass, wie ihre Materialien betonten, ist nicht das Schreiben von Agenten – es ist, sie in Produktion und im großen Maßstab zu managen.
Eine wachsende Zahl von Forschungsarbeiten untermauert diese Richtung. Google DeepMinds Arbeit von 2025 zu Embedding-Limitationen zeigte mathematisch, dass Fixed-Size-Vector-Embeddings bei Skalierung strukturelle und relationale Informationen verlieren – direkt relevant für jeden, der Embedding-basiertes Tool-Retrieval erwägt. Neo4js Konzept des "Context Engineering" argumentiert, dass zuverlässige KI aus Architektur kommt, nicht aus cleverem Prompt-Phrasing.
Unsere Erfahrung deckt sich mit einer Richtung, die wir branchenweit sehen: Anthropics einfache/komponierbare Muster, LangChains Fokus auf Produktionsbetrieb statt Framework-Abstraktionen. Weniger vorgefertigtes Scaffolding, mehr direkte Modellfähigkeit – aber stets validiert gegen reale Nutzung, nicht als Doktrin übernommen. Weniger Pre-Filtering, mehr modellseitiges Urteilsvermögen. Die Frage ist nicht: „Wie bauen wir eine perfekte Architektur um das Modell herum?" Sondern: „Wie geben wir dem Modell, was es tatsächlich braucht, und gehen ihm dann aus dem Weg?"
Das macht Foundax' Schlussfolgerungen nicht universell. Unterschiedliche Businesses, unterschiedliche Modelle, unterschiedliche Tool-Oberflächen werden zu unterschiedlichen Antworten kommen. Was universell ist, ist die Methode: Erst testen, dann designen.
F: Heißt das, ich sollte immer alle Tools ans Modell exponieren?
Nein. Es hängt von deiner Tool-Anzahl, deinem Modell, deinem Context-Budget und deiner Domäne ab. Der Punkt ist nicht „immer alles exponieren." Der Punkt ist: Teste, bevor du filterst. Unterstell nicht, dass das Modell es nicht kann – verifiziere es. In unserem Fall war etwa ein Dutzend komprimierter Tool-Signaturen pro Aufgabe handhabbar und effektiv. Deine Zahlen können anders aussehen.
F: Wann sollte ich stattdessen fixe Workflows verwenden?
Wenn die Aufgabe wirklich deterministisch ist, das Fehlerrisiko katastrophal und das Hintergrundwissen des Modells in dieser Domäne schwach. Workflows sind nicht falsch – sie sind falsch, wenn sie Reasoning ersetzen, das das Modell selbst hätte leisten können. Nutze sie für Safety-Guardrails und deterministisches Post-Processing, nicht als Ersatz für modellseitiges Urteilsvermögen.
F: Was ist der Unterschied zwischen einem sprachlichen Katalog und einem API-Schema?
Ein sprachlicher Katalog sagt dem Modell, was ein Tool tun kann – in komprimierter natürlicher Sprache, z. B. „Read: [12] Product Variants – SKU / Preis / Bestand / Verfügbarkeitsstatus." Ein API-Schema sagt dem Modell, wie es das Tool aufruft, mit vollständigen Parameter-Spezifikationen, Enums und Constraints. Das Modell braucht das Fähigkeitsmenü. Die Runtime braucht das technische Handbuch. Diese beiden zu vermischen ist einer der teuersten Fehler, die du machen kannst.
F: Wie entscheide ich, was ins Modell und was in die Runtime gehört?
Eine gute Heuristik: Das Modell übernimmt Verstehen, Beurteilen, Auswählen und Erklären. Die Runtime übernimmt Berechtigung, Ausführung, Bestätigung, Validierung und Readback. Wenn du das Modell bittest, Regeln durchzusetzen, bist du auf der falschen Seite der Linie. Das Modell schlägt vor; die Runtime entscheidet und führt aus.
F: Was ist mit den Kosten? Erhöht das Exponieren von mehr Tools nicht den Token-Verbrauch?
In unserem Fall war ein komprimierter sprachlicher Katalog tatsächlich günstiger als Multi-Round-Verzeichnis-Exploration oder Retrieval-Ketten. Jeder Tool-Eintrag umfasst etwa tausend Zeichen. Bei etwa einem Dutzend exponierter Tools pro Aufgabe liegt die Summe bei etwa zehn- bis zwanzigtausend Zeichen – rund viertausend bis fünftausend Tokens. Vergleiche das mit mehreren Runden Intent Decomposition, Retrieval, Candidate Review und Re-Selection. Der einfachere Ansatz war oft token-effizienter, nicht weniger.
F: Was war die wichtigste einzelne Erkenntnis aus diesem Prozess?
Dass „dem Modell helfen" und „das Modell einschränken" aus der Designer-Perspektive identisch aussehen können – aber entgegengesetzte Wirkung auf das System haben. Jede Architektur, die wir bauten, sollte helfen. Die meisten endeten als Einschränkung. Der Unterschied wurde erst durch Testen sichtbar. Wenn du eine Sache aus diesem Artikel mitnimmst, lass es diese sein: Teste, was dein Modell tatsächlich kann, bevor du anfängst, Architektur zu entwerfen, die kompensieren soll, was du ihm unterstellst, nicht zu können.