DTC-Sites vs Marktplätze im agentischen Commerce
Ein praktischer Leitfaden, um Marktplätze zu nutzen und parallel einen DTC-Kanal mit Produktdaten, Kundenbeziehung, Content und Messung aufzubauen.
Weiterlesen
Big Tech hat KI-Codierung bereits in seine Workflows eingebettet. Doch für die meisten Teams geht es nicht darum, schneller mehr Code zu schreiben, sondern ein klares Projektbild zu haben.
KI-gestütztes Programmieren hat die Frage, ob KI Code schreiben kann, längst hinter sich gelassen.
Vor nicht allzu langer Zeit drehten sich die meisten Gespräche über KI-Programmierung noch um Demos: Kann sie eine Seite generieren? Kann sie eine Funktion schreiben? Kann sie einen Fehler beheben? Diese Frage ist nicht mehr die interessanteste.
Im Jahr 2026 sagte Google-CEO Sundar Pichai, dass 75 % des neuen Codes von Google jetzt von KI generiert und von Ingenieuren geprüft werden. Microsoft-CEO Satya Nadella hat ebenfalls gesagt, dass etwa 20–30 % des Codes in Microsoft-Repositories von KI generiert werden. Der GitHub Octoverse 2025 zeigt, wie schnell neue Entwickler in KI-gestützte Workflows einsteigen: 80 % der neuen GitHub-Entwickler nutzen Copilot innerhalb ihrer ersten Woche.
Der Trend ist bereits klar: KI-Programmierung hält Einzug in die echte Softwareentwicklung.
Aber eine andere Realität ist genauso klar: Entwickler vertrauen ihr noch nicht vollständig.
Die Stack Overflow Developer Survey 2025 ergab, dass 46 % der Entwickler die Genauigkeit von KI-Tools anzweifeln, verglichen mit 33 %, die ihr vertrauen. METRs randomisierte kontrollierte Studie von 2025 mit erfahrenen Open-Source-Entwicklern ergab, dass die Verwendung damaliger KI-Tools in ausgereiften Codebasen die Aufgabenbearbeitungszeit tatsächlich um 19 % erhöhte. DORAs Bericht 2025 über KI-gestützte Softwareentwicklung beschreibt KI ebenfalls als Verstärker: Sie verstärkt die Stärken, die eine Organisation bereits hat, und sie kann auch bestehende Probleme verstärken.
Das erzeugt eine sehr reale Spannung.
Große Tech-Unternehmen nutzen KI-Programmierung. Entwickler nutzen sie ebenfalls. Aber Menschen, die für reale Systeme verantwortlich sind, vertrauen einer „Laut KI ist es erledigt“-Nachricht nicht einfach blind.
Der Grund dafür ist leicht zu verstehen.
KI kann schnell eine Funktion produzieren, die isoliert betrachtet korrekt aussieht. Die Seite öffnet sich. Der Button funktioniert. Die API antwortet. Die UI sieht gut aus. Aber sobald die Änderung zurück in ein echtes Produkt eingefügt wird, bricht ein anderes Modul, ein alter Pfad wird umgangen, Komponentenkonventionen werden inkonsistent, Sprach-Fallbacks verschwinden, SEO-Metadaten werden überschrieben oder ein Randfall, den niemand erwähnt hat, funktioniert nicht mehr.
Dieses Gefühl ist vertraut: Die Änderung sieht für sich genommen gut aus, aber etwas fühlt sich falsch an, sobald sie im gesamten System sitzt.
Die eigentliche Frage ist also nicht, ob KI Code schreiben kann.
Die wichtigere Frage ist:
Erledigt KI eine Aufgabe, oder versteht sie das System?
Wenn sie nur die Aufgabe versteht, kann sie lokal korrekt und systemisch falsch sein. Wenn sie zuerst das System versteht, hat KI-Programmierung eine viel bessere Chance, echte Produktivität zu werden.
---
Wenn ein Team zum ersten Mal KI-Programmierung einsetzt, ist der natürliche Impuls, Aufgaben auf sie zu werfen.
„Füge hier einen Filter hinzu.“ „Aktualisiere diese Seite.“ „Refaktoriere diese Komponente.“ „Verbinde einen Zahlungseinstiegspunkt.“ „Füge ein mehrsprachiges Feld hinzu.“
KI reagiert normalerweise schnell. Das Problem ist, dass sie möglicherweise nur die wörtliche Aufgabe erfüllt.
Du bittest sie, einen Filter hinzuzufügen, und sie fügt einen Filter hinzu. Du bittest sie, eine Seite zu aktualisieren, und sie aktualisiert die Seite. Du bittest sie, eine Komponente zu refaktorieren, und sie refaktorisiert die Komponente.
Aber sie weiß möglicherweise nicht, warum diese Seite existiert, wo die Komponente wiederverwendet wird, ob das Feld vom Storefront konsumiert wird oder ob der Zahlungseinstiegspunkt an Bestellstatus, Callbacks, Rückerstattungen und Fehlerbehandlung gebunden ist.
Deshalb ist das Projektbild wichtig.
Ein Projektbild ist kein Satz wie „das ist ein SaaS-Produkt“ oder „das ist eine E-Commerce-Website“.
Das ist Hintergrundwissen, nicht Systemverständnis.
Ein brauchbares Projektbild sollte mindestens fünf Fragen beantworten.
Erstens, das Ziel.
Was versucht dieses Produkt zu erreichen? Suchverkehr, Conversion, Produktmanagement, Lead-Erfassung, Transaktionsverarbeitung oder operative Effizienz? Dieselbe „Seite erstellen“-Aufgabe bedeutet je nach Ziel sehr unterschiedliche Dinge. Wenn das Ziel SEO ist, benötigt die Seite Metadaten, strukturierte Inhalte, interne Links und Crawlfähigkeit. Wenn das Ziel Backend-Effizienz ist, benötigt sie Formulare, Filter, Bulk-Aktionen und Fehlerbehandlung. Wenn das Ziel Conversion ist, darf die Seite nicht nur gut aussehen; sie muss Vertrauen, Zahlung, Bestellungen und Erwartungen nach dem Verkauf unterstützen.
Zweitens, die Objekte.
Was sind die Kernobjekte im System und wie stehen sie zueinander in Beziehung? Begriffe wie Benutzer, Produkt, Bestellung, Seite, Inhalt und Website können in verschiedenen Systemen sehr unterschiedliche Bedeutungen haben. Wenn die Objekte unklar sind, kann KI leicht Dinge vermischen, die technisch ähnlich aussehen, aber geschäftlich unterschiedlich sind.
Drittens, die Einschränkungen.
Was sollte nicht leichtfertig geändert werden? Vorhandene Komponentenbibliotheken, Routing-Muster, i18n-Struktur, Berechtigungsmodelle, Publishing-Workflows, Zahlungsworkflows, Migrationsbeschränkungen, Markenstimme und SEO-Strategie sind alles Einschränkungen. Einschränkungen sind nicht dazu da, KI zu begrenzen. Sie helfen KI, den falschen Weg zu vermeiden.
Viertens, die Auswirkungsfläche.
Wenn sich etwas ändert, wohin kann die Auswirkung wandern? Betrifft es nur eine Seite oder berührt es Datenmodelle, APIs, Storefront-Rendering, i18n, Caching, Suche, Berechtigungen oder Analysen? Je klarer die Auswirkungsfläche, desto unwahrscheinlicher ist es, dass „diese Funktion funktioniert, aber etwas anderes ist kaputtgegangen.“
Fünftens, die zukünftige Richtung.
Ist das ein einmaliger Patch oder wird es zu einer Produktfähigkeit? Wenn es wiederverwendet wird, ist Hardcodierung riskant. Wenn es eine kurzfristige Korrektur ist, kann Überabstrahierung unnötig sein.
Diese fünf Fragen zusammen ergeben das Bild, das KI benötigt.
Ohne Bild behandelt KI die Aufgabe als isoliert. Mit Bild kann KI die Aufgabe innerhalb des Systems beurteilen.
Praktische Regel: Ein Projektbild ist keine Projektvorstellung. Es sind das Ziel, die Objekte, die Einschränkungen, die Auswirkungsfläche und die zukünftige Richtung. Ohne es sollte man sich nicht voreilig darum kümmern, KI um größere Codeänderungen zu bitten.
---
Tech-Stack-Diskussionen werden oft zu Argumenten darüber, was moderner ist.
React oder Vue? Next.js oder Remix? Node.js oder Go? PostgreSQL oder MySQL? Sollten wir das neueste Framework verwenden, über das alle sprechen?
Diese Fragen sind wichtig, aber sie können nicht außerhalb des Projektbildes beantwortet werden.
Eine Content-Site, ein Transaktionssystem, ein internes Admin-Tool, eine B2B-Lead-Generierungsplattform und eine KI-Workflow-Plattform benötigen nicht dieselben Fähigkeiten. Was das Produkt unterstützen muss, sollte das Datenmodell, die Routing-Struktur, das Berechtigungsmodell, die Rendering-Strategie, die SEO-Fähigkeit, das Zahlungs-Ökosystem, das Komponentensystem und den Bereitstellungspfad bestimmen.
Im Zeitalter der KI-Programmierung hat der Tech-Stack auch eine neue Dimension:
Kann KI ihn leicht verstehen, und können Menschen ihn leicht überprüfen?
Modelle verstehen eine Codebasis nicht aus dem Nichts. Ihr Verständnis eines Stacks hängt davon ab, wie viel echter Code, Open-Source-Arbeit, Dokumentation, Fehlerdiskussionen und Ingenieurspraxis in diesem Ökosystem existiert. Je mehr zuverlässige Beispiele KI gesehen hat, desto weniger wahrscheinlich ist es, dass sie aus der Luft greift.
Deshalb bevorzugen viele Web-Produkte, Administrationssysteme, Content-Systeme und transaktionsorientierte Produkte oft ausgereifte Kombinationen wie TypeScript, React / Next.js, Node.js, PostgreSQL, ausgereifte Zahlungs-Ökosysteme und stabile UI-Komponentensysteme.
Das bedeutet nicht, dass diese Technologien immer die beste Wahl sind.
Es bedeutet, dass sie für KI leichter zu verstehen und für Menschen leichter zu überprüfen sind.
Der GitHub Octoverse 2025 zeigt, dass TypeScript die am meisten verwendete Sprache auf GitHub geworden ist. State of JavaScript 2024 ergab ebenfalls, dass 67 % der Befragten mehr TypeScript als JavaScript schreiben. Das ist für KI-Programmierung wichtig, denn je mehr Code KI schreibt, desto mehr benötigen Teams starke Typsysteme, IDE-Rückmeldungen, statische Prüfungen und konsistente Engineering-Muster, um die Ausgabe einzuschränken.
Bei TypeScript geht es nicht nur um Typsicherheit.
In der KI-Programmierung gibt es dem Modell auch strukturelle Signale:
Welche Parameter eine Funktion erwartet. Welche Props eine Komponente erhält. Ob einem Objekt ein Feld fehlt. Ob eine API-Antwort der erwarteten Form entspricht. Ob die Änderung die Typüberprüfung noch besteht.
Ausgereifte Frameworks, Zahlungs-Ökosysteme, Datenbanken und UI-Systeme spielen eine ähnliche Rolle. Sie reduzieren den Raum für Improvisation durch KI und helfen sowohl Menschen als auch Modellen, stabile Muster einzuhalten.
Natürlich ist ein ausgereifter Stack nicht immer die Antwort.
Wenn das Projektbild Hochkonkurrenz-Infrastruktur, Echtzeit-Video, Edge-Netzwerke oder tiefgehende Datenverarbeitung umfasst, muss der Tech-Stack anders bewertet werden. KI-Freundlichkeit ist nicht der einzige Standard. Die geschäftliche Eignung kommt immer zuerst.
Praktische Regel: Verwende das Projektbild, um zu entscheiden, was das Unternehmen braucht, und bewerte dann die KI-Freundlichkeit, um zu beurteilen, ob der Stack leicht zu verstehen, zu überprüfen und zu warten ist. Ein guter KI-Programmier-Stack ist geschäftstauglich, von Modellen häufig gesehen, menschlich überprüfbar, typenconstraint und durch starke Community-Muster unterstützt.
Wenn du einen E-Commerce-Stack oder Site-Builder evaluierst, möchtest du vielleicht auch diese Fallstudie lesen: Plattform-„Versteckte Steuern“ und die wahren Kosten eines aufgeblähten Tech-Stacks.
---
Wenn ein Projekt wächst, ist der schwierigste Teil der KI-Programmierung nicht immer, dass es zu viel Code gibt. Es ist oft, dass der Code zu verrauscht ist.
Eine häufige Szene sieht so aus: Du bittest KI, eine Funktion zu ändern. Sie liest viele Dateien und bemüht sich sichtlich, aber sie erstellt trotzdem eine parallele Implementierung.
Sie ignoriert die vorhandene Komponente und schreibt eine neue. Sie überspringt die vorhandene API und erstellt einen anderen Pfad. Sie verwendet den vorhandenen Typ nicht wieder und definiert einen ähnlichen. Sie umgeht die i18n-Struktur und hardcodiert Text. Sie entfernt keine alte Logik; sie fügt einfach eine weitere Kompatibilitätsschicht hinzu.
An diesem Punkt solltest du nicht voreilig dem Modell die Schuld geben.
Schau zurück auf das Projekt selbst. Das Problem könnte bereits da sein: drei verschiedene Fallback-Pfade, i18n gemischt mit hartcodiertem Text, „geteilte“ Komponenten mit Geschïtslogik darin, alte Implementierungen, die nicht mehr verwendet, aber nie gelöscht wurden. KI betritt diese Umgebung und wählt eines der widersprüchlichen Signale aus, das ihr vernünftig erscheint.
Das erklärt, warum dieselbe Anweisung immer und immer wieder wiederholt werden muss.
„Erstelle keine neue Komponente.“ „Hardcodiere nicht.“ „Diese Seite muss i18n verwenden.“ „Dieser Button sollte die vorhandene Komponente verwenden.“ „Diese API sollte das gemeinsame Fehlerbehandlungsmuster verwenden.“
Wenn diese Regeln jedes Mal in Prompts wiederholt werden müssen, liegt das Problem nicht einfach darin, dass KI vergessen hat. Es liegt daran, dass die Projektstruktur die Regeln nicht klar genug ausdrückt.
Prompt-Erinnerungen sind kurzfristig in Ordnung.
Aber mit der Zeit ist der bessere Ansatz, die gegenteilige Frage zu stellen: Enthält der Code bereits widersprüchliche Fallbacks? Ist i18n inkonsistent? Ist die Grenze der Komponentenbibliothek unklar? Hat dasselbe Geschäftsobjekt mehrere Namen? Sind alte Implementierungen noch vorhanden, sodass KI unmöglich weiß, was der aktuelle Standard ist?
Die wirkliche Lösung ist kein längerer Prompt. Es ist, die Regeln zu einem Teil der Codebasis zu machen.
Die Ordnerstruktur sagt KI, wo Modulgrenzen sind. Typen sagen KI, was Datenbeziehungen sind. Adapter sagen KI, was Transformationsregeln sind. Schemata sagen KI, was Eingabe- und Ausgabebeschränkungen sind. Tests sagen KI, was Schlüsselverhalten sind. Benennungen sagen KI, was die Geschäftssprache ist. Dokumentation sagt KI, was die Designabsicht ist.
An diesem Punkt wird der Code selbst zur Dokumentation.
Wenn KI Funktionen erstellt, refaktoriert oder Probleme untersucht, braucht sie keinen Menschen, der alles von Grund auf neu erklärt. Sie kann der Struktur folgen, relevante Module finden, die Auswirkungsfläche verstehen, doppelte Implementierungen identifizieren und das Risiko verringern, dass eine Aufgabe einen anderen Teil des Produkts beeinträchtigt.
Praktische Regel: Wann immer du dieselbe Regel gegenüber KI wiederholen musst, überprüfe zuerst, ob die Codebasis bereits widersprüchliche Signale enthält. Verschiebe die Regel dann in die Struktur, Typen, Benennungen, Schemata, Adapter, Tests oder Dokumentation. Ansonsten verwendest du Prompts, um die Systemkonsistenz aufrechtzuerhalten.
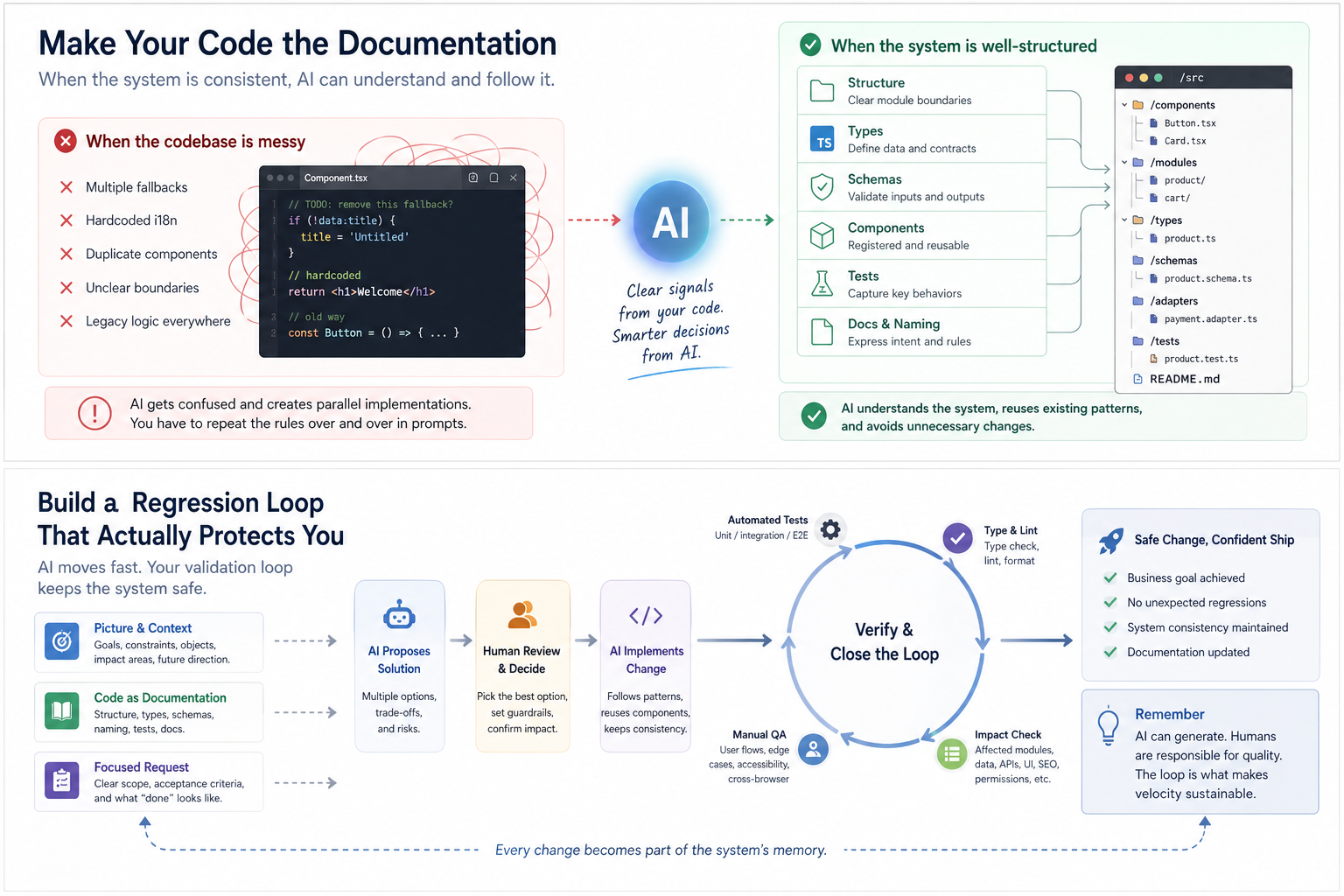
Der gefährlichste Teil der Einzelaufgaben-KI-Arbeit ist nicht, dass KI den Code nicht schreiben kann. Es ist, dass KI nur das sieht, was direkt vor ihr liegt.
Die Seite wird gerendert, aber SEO bricht ein. Das Formular wird abgeschickt, aber Berechtigungen werden umgangen. Der Zahlungseinstieg wird geöffnet, aber der Bestellstatus ist unvollständig. Das mehrsprachige Feld wird gespeichert, aber die Storefront-Laufzeitumgebung konsumiert es nicht korrekt. Die Komponente sieht besser aus, passt aber nicht mehr in das bestehende Designsystem.
Das sind keine Syntaxfehler.
Es sind Auswirkungsflächen-Fehler.
Das Schmerzhafte daran ist, dass sie sich oft nicht sofort zeigen. Die Seite sieht heute gut aus. Der Build läuft durch. Die KI-Zusammenfassung klingt zuversichtlich. Ein paar Tage später hat eine andere Sprachversion den falschen Titel, ein alter Link gibt 404 zurück, eine Formularübermittlung erreicht nie das Admin-Panel oder ein scheinbar unrelatedter Publishing-Workflow beginnt zu versagen.
Das kannst du nicht lösen, indem du die Aufgabe einfach detaillierter beschreibst.
Das Problem ist nicht, dass KI nicht weiß, was du diesmal möchtest. Das Problem ist, dass sie nicht weiß, was diese Änderung berühren könnte.
Wenn das Projekt ein Bild hat und die Codebasis nach und nach zur Dokumentation wird, kann KI mehr tun als nur eine Datei zu bearbeiten. Sie kann beginnen, der Systemstruktur zu folgen, um Upstream- und Downstream-Abhängigkeiten zu verstehen.
Wenn du sie bittest, ein Inhaltsmodul zu ändern, kann sie Typen, Adapter, Seitenkonsumenten, SEO-Metadaten, i18n-Schlüssel und Storefront-Rendering-Pfade verfolgen.
Wenn du sie bittest, ein Formular zu ändern, kann sie Schemata, APIs, Validierung, Absendelogik, Benachrichtigungen, Lead-Datensätze und Frontend-Interaktionen verfolgen.
Wenn du sie bittest, eine Komponente anzupassen, kann sie die Komponentenregistrierung, wiederverwendete Seiten, Theme-Token, responsives Verhalten und Barrierefreiheitsprüfungen verfolgen.
Das ist der Wert von Code als Dokumentation.
Ohne Bild kann KI nur antworten: „Wie implementiere ich das?“ Mit Bild kann KI auch antworten: „Was könnte das beeinflussen?“
Praktische Regel: Bevor du KI bittest, eine Aufgabe zu implementieren, frage nicht nur, wie sie es tun wird. Bitte sie, die Module, Pfade und Regressionspunkte zu verfolgen, die möglicherweise betroffen sind.
---
Aufgaben sollten klar sein.
Aber Klarheit bedeutet nicht, jeden Button, jedes Feld, jede Farbe und jede Interaktion in äußerster Detailgenauigkeit zu beschreiben.
Einige KI-Programmieraufgaben wirken zunächst reibungslos: Du schreibst die Anforderung sorgfältig auf, und KI befolgt sie. Aber wenn sie fertig ist, fühlt sich der Systemzustand merkwürdiger an. Alte Logik bleibt bestehen, neue Logik wird oben drauf geschichtet, die Seite funktioniert, aber die Wiederverwendung ist kaputt, ein Feld wird hinzugefügt, aber die Quelle und das Ziel der Daten sind unvollständig.
Diese Erfahrung kann irreführend sein. Sie lässt dich fragen, ob die Anforderung nicht detailliert genug war.
Oft ist das Fehlende nicht das Detail. Es ist der Zielsystemzustand.
Du sagst KI „Füge einen Button hinzu“, und sie fügt einen Button hinzu. Du sagst KI „Füge ein Feld hinzu“, und sie fügt ein Feld hinzu. Du sagst KI „Mach das zu einer zweistufigen Bestätigung“, und sie ändert den Ablauf.
Aber du hast ihr nicht gesagt, was das System nach der Änderung weniger haben sollte, was bleiben sollte und was vereinheitlicht werden sollte.
Sollte die alte Logik nach dem Hinzufügen neuer Logik gelöscht werden? Wie soll nach dem Hinzufügen eines neuen Feldes mit historischen Daten umgegangen werden? Sollte der alte Einstieg nach dem Start einer neuen Seite noch existieren? Sollten doppelte Komponenten nach dem Hinzufügen einer neuen Komponente konsolidiert werden? Sollte alter hartcodierter Text nach der Einführung eines neuen i18n-Ansatzes ebenfalls entfernt werden?
Das ist der Teil, der bei einer einzelnen Aufgabe am leichtesten übersehen wird.
Eine gute Anforderung sollte KI nicht nur sagen, was zu bauen ist. Sie sollte drei Dinge enthalten.
Erstens, warum die Aufgabe existiert.
Ist es für die Benutzererfahrung, Conversion, operative Effizienz, SEO, Stabilität oder technische Schulden? Wenn das Ziel unklar ist, wird KI normalerweise den direktesten Weg wählen, nicht unbedingt den besten Weg.
Zweitens, wie das System nach der Änderung aussehen soll.
Was soll sich ändern? Was soll sich nicht ändern? Welche alte Logik soll entfernt werden? Welche Kompatibilitätslogik soll bleiben?
Drittens, wie man feststellen kann, ob nichts kaputtgegangen ist.
Welche Seiten sollten überprüft werden? Welche Pfade sollten ausgeführt werden? Welche Daten sollten inspiziert werden? Welches Fallback-Verhalten sollte bestätigt werden? Ohne Akzeptanzkriterien kann KI leicht etwas produzieren, das nur erledigt aussieht.
Also ja, eine Aufgabe kann detailliert sein.
Aber sie kann nicht nur Details enthalten. Sie muss KI auch sagen, in welchem Zustand sich das System nach der Änderung befinden soll.
Praktische Regel: Lokale Aufgabendetails sind nützlich, aber sie müssen mit dem Warum der Aufgabe, dem Zielsystemzustand und der Möglichkeit zur Überprüfung, dass nichts kaputtgegangen ist, einhergehen.
---
Da KI-Programmierwerkzeuge immer beliebter werden, füllt sich das Internet natürlich mit Regeln, Fähigkeiten, Prompts und Best Practices.
Das ist verständlich. Jeder will KI zuverlässiger machen.
Aber ein häufiges Problem ist, dass Teams einen Stapel externer Regeln hinzufügen, bevor das Projektbild klar oder die Codestruktur sauber ist.
Frontend-Entwicklungs-Fähigkeiten. UI-Design-Fähigkeiten. React-Best-Practices. SaaS-Architekturregeln. SEO-Schreib-Prompts. Sicherheitschecklisten. Code-Review-Regeln. „Godmode“-Konfigurationen für Cursor, Claude Code oder Codex.
Diese sind nicht nutzlos.
Das Problem ist, dass sie nicht dieselbe Art von Regel sind.
Die erste Art sind externe Basisregeln.
Sicherheitsprüfungen, SQL-Injection-Risiken, XSS-Risiken, Berechtigungsprüfungen, Zahlungsidempotenz, API-Fehlerbehandlung, Barrierefreiheitsgrundlagen, SEO-Grundlagen, Leistungsprüfungen und Testabdeckungserinnerungen fallen in diese Kategorie.
Diese Regeln sind relativ universell. Sie kollidieren normalerweise weniger mit dem Projektstil, und viele von ihnen sind grundlegende Sicherheitsvorkehrungen. Externe Fähigkeiten, Checklisten und Best Practices können hier wertvoll sein.
Die zweite Art sind projekteigene Regeln.
Seitenstil, Komponentennutzung, Theme-Tokens, Abstandsgewohnheiten, Formularkomponenten, Modalverhalten, Routing-Struktur, i18n-Organisation, Geschäftsschichtung, Datenbenennung, Ordnerkonventionen und Komponentenwiederverwendungsgrenzen gehören hierher.
Diese Regeln sollten nicht zuerst aus dem Internet kopiert werden.
Ihre wichtigste Quelle ist nicht, wie es jemand anderes macht. Es ist, wie dein Projekt bereits funktioniert.
Die Frontend-Seitengenerierung ist ein gutes Beispiel.
Du möchtest, dass die Seite besser aussieht, also fügst du externe Frontend-Fähigkeiten hinzu: moderner SaaS-Stil, Premium-Gefühl, Glas-Morphismus, Kartenlayout, Bewegung, starke visuelle Hierarchie, Landing-Page-Best-Practices.
Jede einzelne davon kann für sich genommen vernünftig sein.
Aber wenn das Projekt bereits eine eigene Komponentenbibliothek, Tailwind-Tokens, Buttons, Karten, Formulare, responsive Regeln, Markenstil und Seitenstruktur hat, können diese externen Fähigkeiten stattdessen Störungen verursachen.
KI beginnt zu zögern:
Sollte sie der externen Fähigkeit oder den vorhandenen Komponenten folgen? Sollte sie die vorhandene Karte wiederverwenden oder ein neues Kartendesign erstellen? Sollte sie Bewegung für ein Premium-Gefühl hinzufügen oder Leistung und Konsistenz bewahren? Sollte sie das externe Landing-Page-Layout verwenden oder der eigenen Informationsarchitektur des Produkts folgen?
Das Endergebnis mag an einer Stelle „standardmäßiger“ aussehen, aber insgesamt weniger konsistent sein.
Es ist nicht so, dass KI es versäumt hat, die Regeln zu befolgen. Sie hat zu viele Regeln befolgt, die nicht zu diesem Projekt gehörten.
An diesem Punkt, anstatt weitere Regeln hinzuzufügen, bitte KI, die tatsächlichen Regeln des Projekts zusammenzufassen.
Welche Komponenten werden häufig verwendet? Wie sind Seiten normalerweise strukturiert? Werden Formulare, Modals, Buttons und Karten auf konsistente Weise geschrieben? Wo leben i18n-Schlüssel normalerweise? Welche Konventionen gibt es für API-Aufrufe und Fehlerbehandlung? Welche Komponenten sollten wiederverwendet werden und welche Logik sollte nicht dupliziert werden? Wie wurden ähnliche Funktionen in letzter Zeit implementiert? Welche impliziten, aber stabilen Engineering-Gewohnheiten hat das Projekt bereits?
Fasse diese zuerst zusammen. Entscheide dann, welche externen Fähigkeiten es wert sind, übernommen zu werden und welche nicht zum aktuellen Projekt passen.
Praktische Regel: Externe Fähigkeiten sind nützlich für Basisregeln wie Sicherheit, Compliance, Leistung, Barrierefreiheit und SEO. Für Komponentenstil, Geschäftsschichtung, Seitenstruktur und Namenskonventionen lass das Modell zuerst deine Codebasis zusammenfassen.

Eine der schwächsten Arten, KI-Programmierung einzusetzen, ist, sie als gehorsamen Ausführer zu behandeln.
Du entscheidest die Lösung und bittest dann KI, sie zu implementieren. Sie implementiert sie. Aber hinterher stellst du fest, dass der Weg von Anfang an falsch war.
Das passiert häufig: Du bittest KI, ein Problem zu beheben, und sie behebt es mit einer schwerfälligen Lösung. Du bittest sie, eine Funktion hinzuzufügen, und sie fügt sie hinzu, obwohl die Wiederverwendung eines vorhandenen Moduls besser gewesen wäre. Du bittest sie, einen Logikblock zu refaktorieren, und sie tut es, übersieht aber, dass das eigentliche Problem die Datenstruktur ist.
Was ein großes Sprachmodell von einem traditionellen Automatisierungswerkzeug unterscheidet, ist, dass es nicht nur Anweisungen ausführt. Es kann Code schreiben, weil es eine große Menge realer Softwaremuster, Open-Source-Projekte, technischer Diskussionen, Fehlerfälle und Best Practices aufgenommen hat.
Es weiß, wie CMS-Systeme normalerweise Inhalte organisieren. Es weiß, warum E-Commerce-Systeme sich um Bestellstatus kümmern. Es weiß, warum i18n nicht überall hartcodiert werden sollte. Es weiß, warum Zahlungs-Callbacks Idempotenz benötigen. Es weiß, warum Storefront-Laufzeitumgebung und Admin-Editor einen stabilen Vertrag brauchen. Es weiß auch, warum SEO, strukturierte Daten, Formulare, Berechtigungen, Logs und Tests sich in echten Systemen gegenseitig beeinflussen.
Wenn du es nur nutzt, um deine Idee in Code umzusetzen, lässt du eine Menge Wert ungenutzt.
Ein besserer Ansatz ist, KI zunächst basierend auf dem Projektbild und dem Code-Kontext Optionen erkunden zu lassen:
Gibt es ein ausgereifteres Implementierungsmuster? Zu welcher Schicht sollte diese Funktion gehören? Gibt es ein vorhandenes Muster, das wir wiederverwenden sollten? Welche Module könnte diese Änderung beeinflussen? Gibt es doppelte Logik im aktuellen Code? Sollte alte Logik entfernt werden? Ist diese Anforderung überhaupt die richtige Lösung für das Problem?
Das bedeutet nicht, KI die endgültige Entscheidung treffen zu lassen.
Es bedeutet, KI zu bitten, den Entscheidungsraum zu erweitern.
KI kann konservative Korrekturen, lokale Refactorings, Protokollabstraktionen, die Wiederverwendung vorhandener Komponenten, die Löschung alter Logik, die Aufteilung in ein separates Modul vorschlagen oder sogar darauf hinweisen, dass die aktuelle Anforderung möglicherweise nicht die richtige ist.
Die endgültige Wahl bleibt beim Menschen.
Weil viele echte Produktentscheidungen nicht rein technischer Natur sind. Frühphasen-Produkte legen möglicherweise mehr Wert auf Geschwindigkeit. Transaktionsabläufe legen möglicherweise mehr Wert auf Stabilität. SEO-Seiten legen möglicherweise mehr Wert auf Struktur und Crawlfähigkeit. Interne Tools legen möglicherweise mehr Wert auf Wartbarkeit. Kundenseitige Seiten legen möglicherweise mehr Wert auf Vertrauen und Konsistenz.
KI kann dir Optionen zeigen. Sie kann keine Verantwortung für den Kompromiss übernehmen.
Praktische Regel: Wenn der Implementierungspfad unklar ist, bitte KI zunächst um 2–3 Optionen, Annahmen, Auswirkungsflächen und Risiken. Wenn die Grenze klar ist, zerlege die Aufgabe und lass sie ausführen.
---
KI ist sehr gut darin, ein Gefühl der Fertigstellung zu erzeugen.
Der Code ist geschrieben. Die Erklärung ist geschrieben. Die Zusammenfassung ist geschrieben. Die Testvorschläge sind geschrieben. Selbst der Lieferhinweis klingt professionell.
Aber echte Projekte können sich nicht auf „erledigt“ verlassen.
Eine realistischere Erfahrung sieht so aus: Die Zusammenfassung klingt beruhigend, aber der Diff zeigt, dass KI ein paar Dateien berührt hat, die sie nicht hätte berühren sollen. Die aktuelle Seite funktioniert, aber ein anderer Einstieg bricht. Du dachtest, sie hätte nur Text geändert, aber Metadaten, Fallback-Logik und Komponentenreferenzen wurden dabei ebenfalls geändert.
Deshalb darf die Verifizierung kein nachträglicher Gedanke sein.
Je schneller KI generiert, desto wichtiger wird die Regressionsschleife. Sobald die Generierung billig wird, ist der knappe Teil nicht mehr die Code-Produktion. Es ist der Nachweis, dass der Code das System nicht kaputt gemacht hat.
Eine gute Regressionsschleife beginnt vor der Änderung.
Erstens, bitte KI, die Auswirkungsfläche zu identifizieren.
Welche Module, Seiten, APIs, Typen, Daten, SEO, i18n, Berechtigungen, Zahlungen, Formulare, Caching oder Publishing-Workflows könnten betroffen sein?
Zweitens, bitte KI während der Implementierung, der vorhandenen Struktur zu folgen.
Verwende wieder, was wiederverwendet werden sollte. Folge vorhandenen Mustern, wo möglich. Erstelle keine parallele Implementierung leichtfertig. Verstoße nicht gegen Systemkonventionen, nur um eine lokale Aufgabe zu erfüllen.
Drittens, bitte KI nach der Implementierung, Regressionspunkte gegenläufig zu überprüfen.
Welche Seiten sollten überprüft werden? Welche Pfade sollten ausgeführt werden? Welche Tests könnten fehlschlagen? Welche Typen benötigen Validierung? Welche alte Logik sollte entfernt werden? Welches Fallback-Verhalten benötigt Bestätigung?
Viertens, Menschen und CI müssen das Ergebnis verifizieren.
Lies nicht nur die KI-Zusammenfassung. Lies den Diff. Überprüfe nicht nur die Seite. Führe den Ablauf aus. Teste nicht nur den Happy Path. Teste den Ausnahmepfad. Überprüfe nicht nur die Standardsprache. Prüfe das Fallback-Verhalten. Überprüfe nicht nur, ob eine Zahlung oder ein Abonnement erstellt wurde. Prüfe Callbacks, Kündigung, Upgrade, Downgrade und doppelte Auslöser. Überprüfe nicht nur, ob generierte Inhalte flüssig lesbar sind. Prüfe, ob sie zur Marke, zum Seitenziel und zur SEO-Struktur passen.
Das ist auch der Grund, warum große Tech-Unternehmen KI-Programmierung in Entwicklungsworkflows integrieren können. Nicht weil KI niemals Fehler macht, sondern weil sie Code-Review, Tests, CI/CD, Monitoring, Berechtigungen, Logs, Rollbacks und Engineering-Governance haben, die den Effizienzschub auffangen können.
Praktische Regel: KI generiert das Ergebnis. Menschen und CI beweisen, dass das Ergebnis das System nicht kaputt gemacht hat. Was zu beweisen ist und wie es zu beweisen ist, sollte aus dem Projektbild, der Codestruktur und der Auswirkungsanalyse stammen.
---
Wenn wir mit „KI ist ein Ausführungsmultiplikator, nicht das Steuerrad“ beginnen, klingt das richtig, aber ein wenig hohl.
In echten Projekten ist die Arbeitsteilung spezifischer.
KI ist gut in:
Vorschlagen von Optionen basierend auf Weltwissen. Verfolgen von Auswirkungen durch die Codestruktur. Finden doppelter Implementierungen und potenzieller Konflikte. Erstellen erster Entwürfe von Code, Tests und Dokumentation. Erklären komplexer Module. Helfen bei Refactorings und Migrationen. Auflisten von Regressionsprüfungen vor der Veröffentlichung.
Menschen sind besser in:
Beurteilen von Geschäftszielen. Bestätigen des Projektbildes. Treffen technischer Kompromisse. Entscheiden, ob ein Refactoring in der aktuellen Phase sinnvoll ist. Akzeptieren oder Ablehnen von Risiken. Entscheiden, welche Fähigkeiten produktisiert werden sollen. Übernehmen der endgültigen Qualität und Benutzererfahrung.
Hier geht es nicht darum, wer wen ersetzt.
KI erweitert das Urteilsvermögen; Menschen treffen Kompromisse. KI erhöht die Ausführungsgeschwindigkeit; Menschen besitzen die Systemrichtung. KI legt mehr Möglichkeiten offen; Menschen wählen den Weg.
Praktische Regel: Nutze KI nicht nur als Ausführer, und lass KI nicht die Richtung bestimmen. Lass KI Optionen und Auswirkungsanalysen erweitern; lass Menschen die Phasenbeurteilung, geschäftlichen Kompromisse und die endgültige Qualität verantworten.
---
Die Logik hinter KI-Programmierung lässt sich natürlich auf Händler-KI-Workflows ausweiten.
Beide stehen vor demselben grundlegenden Problem:
KI muss den Kontext verstehen, bevor sie nützliche Aufgaben ausführen kann.
KI braucht ein Projektbild, um gut Code zu schreiben. KI braucht ein Händlerbild, um nützliche Inhalte zu generieren. KI braucht Marken-, Produkt-, Seiten- und Conversion-Struktur, um SEO und GEO zu unterstützen.
Deshalb nutzen viele Händler KI, um Texte zu schreiben, Seiten zu erstellen, FAQs zu generieren oder Artikel zu entwerfen, und das Ergebnis sieht vollständig aus, konvertiert aber nicht.
Das Problem ist normalerweise nicht, dass KI nicht schreiben kann.
Das Problem ist, dass KI nicht weiß:
Wer der Händler ist. Was sie verkaufen. An wen sie verkaufen. Warum Kunden ihnen vertrauen sollten. Welche Aufgabe die Seite erfüllen soll. Ob der Inhalt Anfragen, Käufe oder langfristigen Suchverkehr fördern soll. Welche echten Bedenken die FAQ beantworten soll. Wie Produkte, Seiten, Formulare und SEO zusammenhängen.
Ohne diesen Kontext kann KI leicht Inhalte generieren, die wie Text aussehen.
Er mag glatt, vollständig und sogar ausgefeilt sein. Aber ihm fehlt das geschäftliche Urteilsvermögen.
Der Schlüssel zu Händler-KI-Workflows ist also nicht, Benutzer zu bitten, mehr Prompts zu schreiben.
Die wichtigere Frage ist, ob das System automatisch Marken-, Produkt-, Seitenziel-, FAQ-, Formular-, SEO- und Conversion-Pfad-Daten in einen höherwertigen Kontext organisieren kann – sodass KI den Händler und das Geschäft versteht, bevor sie die Aufgabe ausführt.
Dies ist die Richtung, auf die Foundax sich bei der Entwicklung von KI-Workflows konzentriert.
Wir sehen KI nicht als isolierten „Generieren“-Button. Ein wertvollerer Ansatz ist es, KI in den Betriebsablauf des Händlers zu integrieren: Händler dabei zu unterstützen, Inhalte, Seiten, mehrsprachige Assets, SEO und Marketingmaterialien schneller zu organisieren, während das System Produkte, Formulare, Zahlungen, Bestellungen, Publishing und Conversion-Pfade handhabt.
In diesem Design schreibt KI nicht einfach „einen Absatz für dich“.
Sie sollte zuerst verstehen:
Wofür die Marke steht. Welches Problem das Produkt oder die Dienstleistung löst. Welche Aufgabe die Seite erfüllen muss. Welche Bedenken die FAQ beantworten soll. Welche Art von Lead das Formular sammeln soll. Welcher Suchintention der Inhalt dienen soll. Ob die Seite Anfragen, Käufe oder langfristiges Vertrauen fördern soll.
Dann kann sie etwas Nützliches generieren.
Das ist dieselbe Logik wie bei der KI-Programmierung.
Gib KI nicht nur eine lokale Aufgabe. Lass sie zuerst das Bild verstehen. Verwende dann strukturierte Daten, geschäftliche Verträge und Kontextinjektion, um sie in die richtige Informationsumgebung zu versetzen.
Praktische Regel: Der Schlüssel zu Händler-KI-Workflows ist kein besserer Prompt. Es sind strukturierte Daten, geschäftliche Verträge und hochwertiger Kontext, die dem Modell helfen, die Marke und das Geschäft zu verstehen, bevor es Texte, Seiten, mehrsprachige Inhalte, SEO-Assets oder Betriebsmaterialien generiert.
---
Traditionelles SEO hat sich oft auf Keywords, Titel, Beschreibungen und Backlinks konzentriert.
Diese sind immer noch wichtig.
Aber da KI-Suche und generative Antworten immer häufiger werden, wird eine tiefere Frage wichtiger:
Können Maschinen verstehen, wer du bist?
Bist du eine Marken-Website oder eine temporäre Landing Page? Was verkaufst du? Wem dienst du? Wo sind deine Produkte, Dienstleistungen, Fälle, FAQ und Kontaktpunkte? Gibt es eine Struktur zwischen deinen Inhalten? Können deine Seiten gecrawlt, verstanden und zitiert werden?
Das ist dasselbe grundlegende Problem wie bei der KI-Programmierung.
KI-Programmierung erfordert, dass das Modell die Projektstruktur versteht. KI-Inhaltsgenerierung erfordert, dass das Modell die Händlerstruktur versteht. SEO erfordert, dass Suchmaschinen die Seitenstruktur verstehen. GEO erfordert, dass generative Suchsysteme die Beziehung zwischen Marke, Produkten, Dienstleistungen und Inhalten verstehen.
Die Zukunft wird also nicht nur darum gehen, wer mehr Inhalte generieren kann.
Je einfacher Inhalte zu generieren sind, desto wichtiger wird die Struktur.
Wenn eine Marke nur eine große Anzahl isolierter Seiten generiert, sehen Suchmaschinen und KI-Suche immer noch Fragmente. Wenn eine Marke ihre Website, Produkte, Dienstleistungen, Fälle, FAQ, Inhalte, Formulare, Conversion-Pfade und mehrsprachigen Seiten in einer klaren Struktur organisiert, wird es für Benutzer, Suchmaschinen und KI-Systeme einfacher, sie zu verstehen.
Praktische Regel: SEO und GEO sind nicht nur Content-Produktionsprobleme. Sie sind Strukturprobleme. Je klarer du Marke, Produkt, Inhalte, FAQ und Conversion-Pfade organisierst, desto einfacher ist es für Maschinen und Benutzer, dich zu verstehen.
Wenn du SEO und GEO für einen Storefront aufbaust, möchtest du vielleicht auch lesen: Die neuen Regeln für SEO: Das KI-Such-(GEO)-Spiel im Jahr 2026 gewinnen, Wie man Produkte in ChatGPT und Google AI Mode sichtbar macht: Ein Händler-Leitfaden für 2026.
Wenn dich interessiert, wie Marken-Assets, Inhalte und SEO zusammenwirken, lies auch: Warum 2026 der richtige Zeitpunkt ist, um deine persönlichen Marken-Assets aufzubauen.
Wenn du KI-Programmierwerkzeuge oder Tech-Stack-Entscheidungen evaluierst, lies den Begleitartikel: Wie sollten Multi-Market-DTC-Marken 2026 einen E-Commerce-Stack wählen?.
Wenn du den produktstrategischen Blickwinkel darauf möchtest, warum Web-First-Auslieferung im KI-Zeitalter wichtiger ist, lies: Wird KI 2026 mehr Produkte zurück ins Web bringen?.
Wenn du SEO und GEO für einen Storefront aufbaust, lies weiter: Die neuen Regeln für SEO: Das KI-Such-(GEO)-Spiel im Jahr 2026 gewinnen, Wie man Produkte in ChatGPT und Google AI Mode sichtbar macht.
Wenn du sehen möchtest, wie Foundax KI-Workflows in Händlerabläufe integriert, informiere dich über die Funktionen.
Nicht Code. Nicht Fähigkeiten. Das Projektbild.
Mindestens sollte KI fünf Dinge verstehen: Ziel, Objekte, Einschränkungen, Auswirkungsfläche und zukünftige Richtung. Andernfalls behandelt sie Anforderungen als isolierte Aufgaben und kann lokal korrekte, aber systemisch falsche Ergebnisse produzieren.
Entscheidungsregel: Wenn KI nicht erklären kann, warum das Projekt existiert, was die Kernobjekte sind und welche Einschränkungen nicht verletzt werden dürfen, bitte sie noch nicht um größere Codeänderungen.
---
Beginne mit dem Geschäftsbild und bewerte dann die KI-Freundlichkeit.
Wenn das Produkt Inhalte, Seiten, SEO, Admin-Operationen, Transaktionen, Formulare, Zahlungen und mehrsprachige Unterstützung umfasst, benötigt es normalerweise ausgereifte Frameworks, klare Typen, stabile Datenbanken, ausgereifte Zahlungs-Ökosysteme und verifizierbare Engineering-Workflows.
Ein KI-freundlicher Stack ist nicht der neueste Stack. Es ist ein Stack, den Modelle oft gesehen haben, den Menschen überprüfen können, den Typen einschränken können und für den die Community starke Muster hat.
Entscheidungsregel: Frage nicht nur, ob die Technologie neu ist. Frage, ob sie zum Geschäft passt, ob KI sie verstehen kann, ob das Team sie überprüfen kann und ob die langfristige Wartung handhabbar ist.
---
Ja, wenn das Projekt verrauschter wird.
Aber wenn das Projekt strukturierter wird, könnte KI tatsächlich einfacher zu verwenden sein. Ordner, Typen, Schemata, Adapter, Tests, Benennungen und Dokumentation können nach und nach zum Betriebshandbuch des Modells werden.
Das eigentliche Problem ist nicht die Projektgröße. Es ist das Kontextrauschen.
Entscheidungsregel: Reduziere mit zunehmender Projektgröße das Kontextrauschen, bevor du die KI-Automatisierung erhöhst.
---
Nicht unbedingt.
Detaillierte Anforderungen können die Einzelaufgabengenauigkeit verbessern, aber sie garantieren keine Systemkorrektheit. Eine bessere Anforderung sollte nicht nur sagen, was zu tun ist. Sie sollte auch erklären, warum die Aufgabe existiert, wie der Zielsystemzustand ist und wie zu überprüfen ist, dass nichts kaputtgegangen ist.
Entscheidungsregel: Lokale Aufgabendetails sind nützlich, aber sie müssen mit Ziel, Systemzustand und Akzeptanzkriterien einhergehen.
---
Nicht am Anfang.
Regeln, Fähigkeiten und Best Practices sind nützlich, aber sie müssen nach Typ getrennt werden. Externe Fähigkeiten sind nützlich für Basisregeln wie Sicherheit, Compliance, Leistung, Barrierefreiheit und SEO. Aber projekteigene Regeln wie Komponentenstil, Geschäftsschichtung, Seitenstruktur und Namenskonventionen sollten zunächst aus der Codebasis abgeleitet werden.
Entscheidungsregel: Verwende externe Fähigkeiten für universelle Basisrisiken. Verwende die Codebasis selbst, um Projektstil und Geschäftsstruktur abzuleiten.
---
Bitte KI, die Auswirkungsfläche vor der Ausführung zu identifizieren, entlang der vorhandenen Struktur zu implementieren, Regressionspunkte nach der Ausführung gegenläufig zu überprüfen und dann Menschen und CI das Ergebnis verifizieren zu lassen.
Regression ist nicht nur ein abschließendes Testproblem. Es ist ein Workflow-Problem, das auf Projektbild, Code-Dokumentation und Auswirkungsanalyse aufbaut.
Entscheidungsregel: Frage vor jeder Änderung, was sie beeinflussen könnte. Frage nach jeder Änderung, was sie kaputt gemacht haben könnte.
---
Weil „große Tech-Unternehmen nutzen KI-Programmierung“ und „KI-generierter Code kann ohne Überprüfung ausgeliefert werden“ zwei verschiedene Dinge sind.
Google sagte, 75 % des neuen Codes sei KI-generiert, aber er wird immer noch von Ingenieuren geprüft. Die 20–30 %-Zahl von Microsoft bedeutet ebenfalls nicht, dass Code-Review, Tests und Qualitätsgovernance verschwinden.
Die Stack Overflow Developer Survey 2025 zeigt, dass das Vertrauen der Entwickler in die Genauigkeit von KI-Ausgaben begrenzt bleibt. METRs Studie zeigt ebenfalls, dass KI-Tools in ausgereiften Codebasen Entwickler aufgrund von Verständnis-, Warte-, Überprüfungs- und Korrekturkosten verlangsamen können.
Entscheidungsregel: KI-Programmierung ist es wert, in echte Workflows integriert zu werden, aber sie muss mit Review-, Test-, Validierungs- und Rollback-Mechanismen einhergehen.
---
Beide sind Kontextprobleme.
KI braucht ein Projektbild, um Code zu schreiben. KI braucht ein Händlerbild, um Texte zu schreiben, Seiten zu erstellen, FAQs zu generieren und SEO zu unterstützen.
Wenn das System nicht in der Lage ist, Marke, Produkt, Seitenziele, FAQ, Formulare, SEO und Conversion-Pfade zu organisieren, kann KI nur Inhalte generieren, die vollständig aussehen, denen aber das geschäftliche Urteilsvermögen fehlt.
Entscheidungsregel: Der Schlüssel zu Händler-KI-Workflows sind nicht mehr Prompts. Es ist hochwertiger strukturierter Kontext.
---
KI-Programmierung ist bereits in echten Entwicklungsworkflows angekommen.
Aber das bedeutet nicht, dass Software beiläufig generiert werden kann oder dass das Produkturteil an ein Modell übergeben werden kann.
In echten Projekten besteht der Wert von KI nicht darin, das Urteilsvermögen zu ersetzen. Es ist, das Urteilsvermögen zu erweitern.
Aber das funktioniert nur, wenn KI zuerst das System versteht.
Die richtige Reihenfolge ist also nicht, KI zu bitten, mehr Code zu schreiben.
Es ist:
Baue das Projektbild auf. Wähle einen Stack, der zum Geschäft passt und die KI-Zusammenarbeit unterstützt. Verwandle die Codestruktur in Dokumentation. Lass KI durch diese Struktur Upstream, Downstream und Auswirkungen verstehen. Bearbeite dann spezifische Aufgaben, wähle Fähigkeiten sorgfältig aus und baue eine Regressionsschleife auf. Schließlich übernehmen Menschen die Kompromisse und die endgültige Qualität.
Diese Logik gilt für die Softwareentwicklung. Sie gilt auch für Händler, die KI nutzen, um Texte zu schreiben, Seiten zu erstellen, mehrsprachige Inhalte zu unterstützen und SEO zu verbessern. Sie gilt auch für GEO und den langfristigen Aufbau von Marken-Assets.
Die nächste Phase der KI-Programmierung besteht nicht darin, KI dazu zu bringen, mehr zu schreiben.
Es ist, KI dazu zu bringen, innerhalb des richtigen Systems zu arbeiten.
---