مواقع DTC مقابل الأسواق في agentic commerce
دليل عملي لاستخدام الأسواق الإلكترونية مع بناء قناة DTC تحفظ بيانات المنتج وعلاقة العميل والمحتوى والقياس.
اقرأ المزيد
أربع معماريات Agent، من workflows الثابتة إلى كتالوج لغوي خفيف. كل 'تحسين' كان في الحقيقة نحن نقوم بعمل النموذج بدلاً عنه. المعمارية الفائزة كانت التي توقفت عن محاولة أن تكون ذكية.
هناك لحظة عبثية من بناء Foundax Agent أعود إليها باستمرار.
جربنا معماريات كثيرة. Workflows ثابتة. استكشاف أدوات قائم على الدليل. توصية أدوات قائمة على skills. استرجاع في runtime. مطابقة regex. خطط منظمة. حلقات ReAct متعددة الجولات. في مرحلة ما، فكرنا جدياً في الاسترجاع القائم على embedding.
كل نسخة بدت منطقية على الورق.
أدوات كثيرة جداً، إذن نحتاج إلى تصفية. النموذج يفوّت أشياء، إذن نحتاج إلى تقييد. السياق طويل جداً، إذن نحتاج إلى استرجاع. التنفيذ يجب أن يكون آمناً، إذن نحتاج إلى إجرأة. دقة الأعمال تتطلب أدوات ذرية في الطبقة السفلية.
إذا نظرنا لكل حكم على حدة، لم يكن أي منها خاطئاً.
لكننا بعد ذلك أجرينا أبسط — بل يكاد يكون بدائياً — اختبار: ضغطنا كل الأدوات في كتالوج لغوي خفيف، ألقيناه إلى النموذج، وتركناه يقرأ ويختار بنفسه.
النتيجة كانت جيدة بشكل مدهش.
كنت عاجزاً عن الكلام بصراحة.
لأن ذلك عنى أن معظم تصاميمنا المعقدة لم تكن تطلق قدرات النموذج. كانت تفترض أن النموذج سيفشل، ثم تغلفه بطبقات من المعمارية لتعويض ذلك.
هذا المقال لا يقول "تعريض كل الأدوات هو أفضل ممارسة."
ما أريد قوله حقاً هو: الخطر الأكبر في بناء Agent أعمال ليس أن النموذج ليس ذكياً بما يكفي — بل أن تبدأ في تصميم قفص له قبل أن تختبر ما يمكنه فعله في مجالك.
Foundax هي منصة SaaS للتجارة الإلكترونية.
لذا فإن Foundax Agent لا يتعامل مع دردشة عابرة أو أسئلة معرفة عامة. إنه يتعامل مع المشكلات التشغيلية الحقيقية التي يواجهها التجار في لوحة التحكم الخلفية.
التجار لا يقولون:
"من فضلك استدعِ API قراءة product variant."
بل يقولون:
"لماذا لا يُباع هذا المنتج؟"
"هل صفحتي الإسبانية جاهزة؟"
"هل يمكن لهذا المنتج أن يعمل على Google Shopping؟"
"لماذا يضيف الناس إلى السلة ولا يدفعون؟"
"املأ لي تحسين محركات البحث الناقص."
تبدو هذه الأسئلة كلغة طبيعية، لكن خلف كل منها يكمن نظام أعمال كامل. المنتجات، SKUs، المخزون، التسعير، SEO، الترجمات، العروض الترويجية، الشحن، الدفع، checkout، الطلبات، الاسترجاعات، تغذيات GMC، حالة عرض واجهة المتجر — أي من هذه يمكن أن يؤثر على النتيجة.
لذا فإن هدف Foundax Agent ليس "أن يبدو بشرياً."
ما يحتاج فعلاً إلى فعله هو: فهم نية التاجر الحقيقية، إيجاد الحقائق المقابلة في النظام، اختيار الأدوات الصحيحة، تحضير الكتابات عند الضرورة، والتنفيذ تحت قيود runtime — مع الصلاحيات، التأكيد، و readback في مكانها.
إدخال المستخدم يمكن أن يكون غامضاً. تنفيذ النظام يجب أن يكون دقيقاً.
هذا التوتر هو نقطة انطلاق كل معضلة معمارية تلت.
لدي نزعة كمالية هندسية.
لذا عندما بدأت تصميم Foundax Agent، رفضت غريزياً الأدوات الخشنة.
أداة اسمها analyzeProductReadiness تبدو مريحة. لكن ما الحقول التي تقرأها داخلياً؟ ما المعايير التي تطبقها؟ أين حدود الصلاحيات؟ هل يمكنك readback بعد الكتابة؟ كل هذا يصبح معتماً.
Foundax ليس عرضاً تجريبياً. عندما يطلب منك تاجر إصلاح SEO الخاص به، لا يمكنك استخدام أداة صندوق أسود تغير الأشياء بصمت في الخلفية.
لذا أصررت على أدوات ذرية في الطبقة السفلية:
قراءة حقول المنتج الأساسية. قراءة product variants. قراءة المخزون والتسعير. قراءة SEO المنتج. قراءة ترجمات المنتج. قراءة إعدادات الشحن. قراءة إعدادات الدفع. كتابة حقل محدد. كتابة محتوى للغة محددة. إنشاء مسودة تعديل. Readback بعد الكتابة.
كل أداة وحيدة الغرض، نظيفة، غير متداخلة. تنفيذ دقيق، صلاحيات واضحة، سهلة الاختبار.
ما زلت أعتقد أن هذا الحكم كان صحيحاً.
المشكلة الحقيقية كانت شيئاً آخر: كلما زادت ذرية أدوات الطبقة السفلية، زاد عدد الأدوات لديك. وكلما زاد عدد الأدوات، زادت صعوبة فهم النموذج لها واختيارها في السياق.
كانت تلك المفارقة الأولى.
كلما كانت أداة الطبقة السفلية أكثر ملاءمة لتنفيذ النظام، كانت أقل ملاءمة كواجهة إدراكية للنموذج.
الذرية لم تكن الخطأ. الخطأ كان إلقاء كومة من الأدوات الذرية مباشرة أمام النموذج وتوقع أن يختار الأدوات الصحيحة باستمرار.
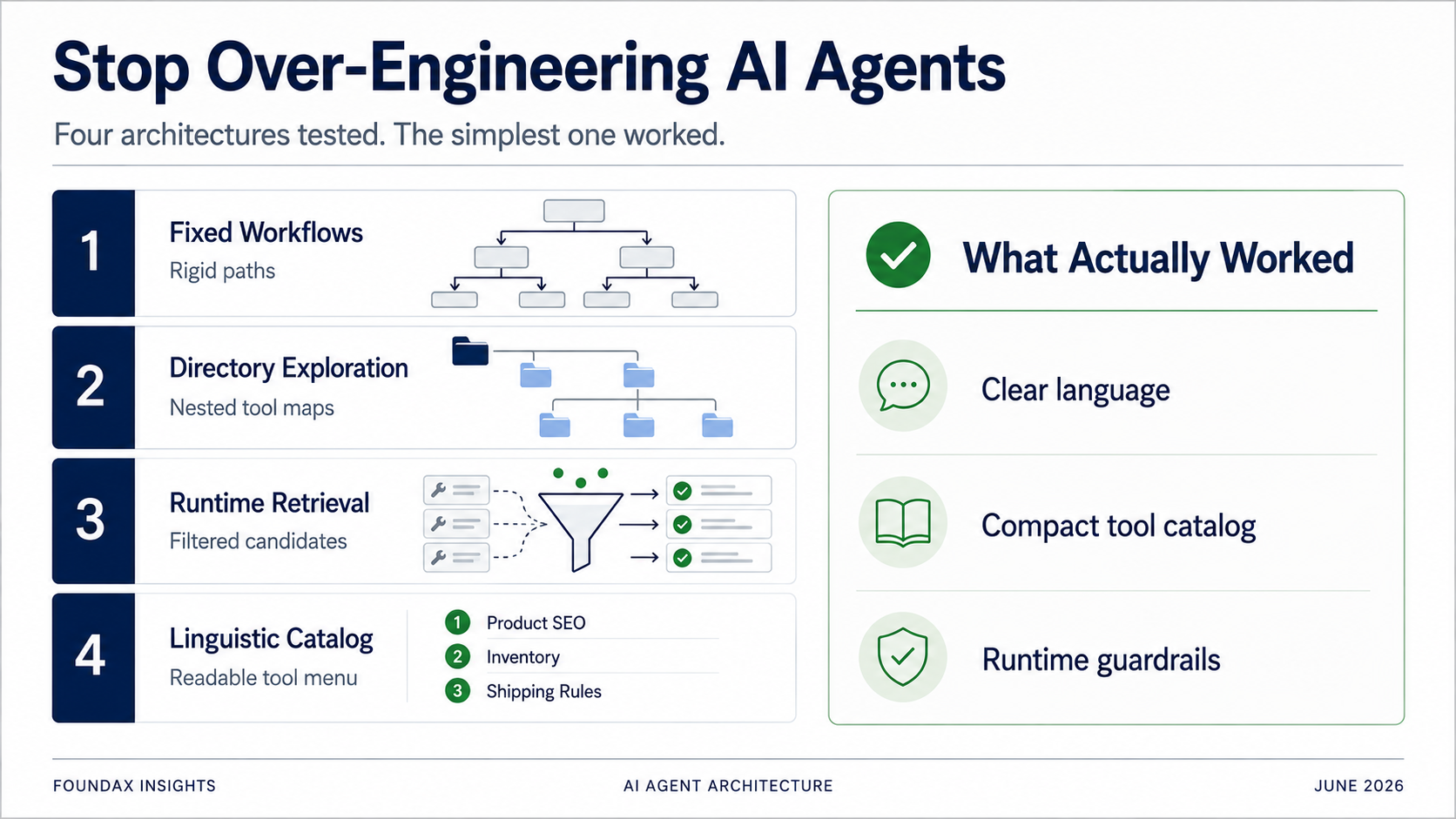
لحل مشكلة اختيار الأدوات، كانت محاولتنا الأولى هي workflows ثابتة.
كانت هذه غريزة طبيعية. إذا كانت مهام التجار عالية التكرار محدودة، فقم ببرمجتها مسبقاً.
فحص SEO المنتج. فحص تغطية الترجمة. فحص جاهزية إطلاق المنتج. تشخيص انخفاض التحويل. فحص جاهزية GMC.
كانت مهمة النموذج هي تحديد نية المستخدم، مطابقتها مع workflow، ثم تسليمها إلى runtime للتنفيذ الثابت.
بدا هذا آمناً. بدا هندسياً.
لكن في الاختبار، تدهور سريعاً إلى نظام كلمات مفتاحية غبي.
تعبير المستخدم متنوع جداً. شخص يقول "هل SEO مكتمل؟" وآخر يقول "هل يمكن لـ Google فهرسة هذه الصفحة؟" وآخر يقول "هل أخطأت في عنوان المنتج؟" وآخر يقول "لماذا يستمر feed في الخطأ عندما أشغل الإعلانات؟"
لجعل كل تنوع يصل إلى مهمة، تستمر في إضافة كلمات مفتاحية، مرادفات، قواعد. في النهاية النظام ليس دقيقاً، وصيانته أصعب من أي وقت مضى.
الأهم من ذلك، لم يكن لدى النموذج أي مساحة تقريباً للعمل. كان مجرد مصنف نوايا. مسار التحليل الفعلي، اختيار الأدوات، تسلسل جمع الأدلة — كلها محددة مسبقاً من قبلنا.
عندها أدركت:
إذا كانت كل مهمة مبرمجة مسبقاً في workflow، فإن الشيء لم يعد Agent — إنه أداة workflow ترتدي زي ذكاء اصطناعي.
Workflows الثابتة، في جوهرها، تستبدل استدلال النموذج بتعداد بشري للأعمال. إنها تجعل النظام أكثر قابلية للتحكم، لكنها تجرد Agent من Agency.
بعد ذلك، غيرنا الاتجاه.
بدلاً من إلقاء كل الأدوات دفعة واحدة، ننظمها في دليل. يختار النموذج مجال عمل أولاً، ثم يوسع الأدلة الفرعية، ثم يختار أدوات محددة.
المنتجات. الطلبات. المدفوعات. الشحن. العروض الترويجية. التحليلات. GMC.
تحت "المنتجات": المعلومات الأساسية، SKUs، المخزون، التسعير، SEO، الترجمات.
كان هذا أكثر دقة بكثير من workflows الثابتة. لم يكن النموذج يطابق كلمات مفتاحية مع مسار محدد مسبقاً — بل كان يستكشف خريطة أدوات منظمة. وجد الأدوات الصحيحة بشكل حقيقي في كثير من الأحيان.
لكن المشكلة كانت واضحة: السرعة.
كل مهمة تتطلب اجتياز الدليل. الأسئلة البسيطة كانت تمر عبر سلسلة الاستكشاف. استهلاك tokens كان مرتفعاً. زمن الاستجابة كان مرتفعاً.
تاجر يسأل "هل SEO هذا المنتج مكتمل؟" ويتصرف Agent كما لو كان يتصفح دليل استخدام سميكاً للنظام الخلفي.
استكشاف الدليل لم يكن خاطئاً في الاتجاه. المشكلة كانت أنه حوّل "فهم نظام الأدوات" إلى تكلفة لكل استدعاء. كان على النموذج إعادة استكشاف النظام من الصفر في كل مرة، وهو أمر يصعب قبوله كتجربة منتج.
بعد ذلك، بنينا شيئاً أكثر تطوراً.
ينتج النموذج أولاً فهماً منظماً لموجه المستخدم: تفكيك النية، كلمات مفتاحية، مجالات العمل المعنية، وما إذا كانت المهمة قراءة، كتابة، مختلطة، أو غير معروفة.
ثم تذهب هذه الخطة إلى runtime. يستخدم runtime الـ skills، مطابقة regex، وبيانات الأدوات الوصفية لاسترجاع الأدوات المرشحة. يختار النموذج من المرشحين. بعد قراءة الحقائق، يمكن للنموذج أن يقرر مواصلة الاستكشاف في جولة أخرى.
بدت هذه النسخة كـ Agent Runtime ناضج. وحققت بعض التقدم الحقيقي.
على سبيل المثال، اكتشفنا أن الحقول المنظمة يمكنها تحسين سلوك النموذج. لمنع النموذج من اختيار أول أداة تبدو ذات صلة دون قراءة قائمة المرشحين الكاملة، صممنا حقلاً مثل hasreadalltools — نطلب من النموذج أن يعلن صراحة ما إذا كان قد انتهى من قراءة كل المرشحين قبل إجراء استدعاء أداة. ساعد ذلك حقاً.
لكن ما كان أكثر إثارة للاهتمام: وجدنا لاحقاً أن تعليمة واحدة مكتوبة جيداً بلغة طبيعية يمكن أن تكون أكثر فعالية من حقل منظم معقد.
قبل أن يختار النموذج الأدوات، أضفنا:
"بناءً على هدف عمل المستخدم، اختر كل أدوات التحليل والكتابة الضرورية. لا تختر فقط أول أداة تبدو ذات صلة."
قبل أن يستعد النموذج لإخراج إجابة، أضفنا:
"لا تتسرع في الإجابة. حدد أولاً ما إذا كانت الحقائق الضرورية مكتملة. إذا لم تكن كذلك، استمر في اختيار الأدوات."
حسّنت هذه التعليمات البسيطة عمق استدلال النموذج بشكل كبير.
كان هذا جرس إنذار كبير:
LLM ليس برنامجاً تقليدياً. البروتوكولات المنظمة مفيدة، لكن النموذج دائماً يقرأ اللغة ويحاكي الاستدلال. في أغلب الأحيان، تعليمة واحدة دقيقة ومباشرة ومنخفضة الغموض بلغة طبيعية تعمل بشكل أفضل من حقل منظم معقد.
لكن هذه المعمارية كشفت أيضاً مشكلة أعمق.
استرجاع أدوات runtime صُمم لحل مشكلتي الحمل الزائد للسياق وعدم دقة اختيار الأدوات. لكن runtime هو، جوهرياً، نظام قواعد.
سواء كان regex، skills، كلمات مفتاحية، أو تصفية المجال — يمكنه تصفية أدوات يحتاجها النموذج حقاً، من أول تمريرة.
انظر إلى تاجر يسأل: "لماذا لا يُباع هذا المنتج؟"
قد يشمل هذا السؤال التحليلات. وقد يشمل أيضاً محتوى المنتج، التسعير، المخزون، العروض الترويجية، الشحن، الدفع، checkout، مصادر الزيارات، الجغرافيا، الجهاز، SEO، أصالة نسخة الصفحة.
إذا قام runtime بتصنيفه بحماس زائد في مجال واحد، فسيتم تقييد مجال رؤية النموذج.
هذه هي المفارقة الثالثة:
استرجاع أدوات Runtime يوفر السياق — لكنه يمكن أيضاً أن يصبح سقف مجال رؤية النموذج.
انطلقنا لتقليل عبء النموذج، وانتهى بنا الأمر باحتمال تقييد حكم النموذج.
مع نمو عدد الأدوات، فكرت جدياً في الاسترجاع القائم على embedding.
الفكرة طبيعية. موجه المستخدم → متجه. أوصاف الأدوات → متجهات. درجة التشابه. Top-k إلى النموذج.
يبدو معيارياً. يبدو "أصيل الذكاء الاصطناعي."
لكن كلما فكرت فيه أكثر، بدا أكثر خطأ.
لاسترجاع الإعلانات، توصية المحتوى، أو البحث في مستندات ضخمة، الـ embeddings منطقية. مجموعة المرشحين هائلة، والأنظمة التقليدية حقاً لا تستطيع فهم اللغة. تحتاج إلى ضغط الدلالات إلى متجهات للمطابقة التقريبية.
لكن أدوات Foundax ليست ملايين المستندات غير المعروفة في عالم مفتوح. إنها قدرات أعمال محدودة، قابلة للتعداد، قابلة للوصف، قابلة للضغط داخل نظامنا الخاص.
وأعظم قوة لـ LLM هي تحديداً قراءة اللغة، فهم اللغة، مقارنة الدلالات، والحكم على النية.
فلماذا نحول أوصاف الأدوات إلى متجهات، ثم نستخدم درجة التشابه لنقرر — نيابة عن النموذج — ما الذي يسمح له برؤيته؟
الأمر أشبه بامتلاك كتاب بجدول محتويات قابل للقراءة تماماً. بدلاً من قراءته، تشفر جدول المحتويات إلى أرقام وتجعل القارئ يحكم على أي فصل يقرأ بناءً على المسافة الرقمية.
هذا منطقي في أنظمة البحث التقليدية. في Agent أصيل LLM، أعتقد بشكل متزايد أنه منعطف خاطئ.
بالنسبة لـ Agent أعمال مثل Foundax، الأولوية ليست الاسترجاع المتجهي. إنها الضغط اللغوي — ضغط الأدوات، المستندات، القدرات، والحدود إلى سياق لغوي واضح، دقيق، وعالي الكثافة يمكن للنموذج قراءته مباشرة.
واجهنا أيضاً مشكلة كلاسيكية أخرى: تعريض الأدوات كان ثقيلاً جداً.
في البداية، كل أداة كانت تعرض معلومات كاملة جداً للنموذج: اسم الوظيفة، وصف طويل، نطاق الحقائق، حدود الإجابة، المصادر المستبعدة، تعدادات الحقول، تعدادات مستوى التفصيل، أوصاف المعاملات، تنسيق إرجاع الملاحظة.
يبدو دقيقاً.
لكنني أدركت في النهاية: النموذج لا يحتاج إلى معرفة معظم هذا.
إذا كان تنفيذ الاستعلام الفعلي، التحقق من الحقول، فحص الصلاحيات، حدود المنفذ المالك، تدفقات التأكيد، و readback كلها تُعالج من قبل runtime، فلا شأن للنموذج بقراءة مخطط API الكامل في كل مرة.
ما يحتاج النموذج فعلاً إلى معرفته:
على سبيل المثال:
هذا يكفي.
بادئات "قراءة / كتابة / بحث" في قائمة المرشحين كافية بالفعل للنموذج لتمييز أنواع الإجراءات. صلاحيات القراءة/الكتابة الحقيقية، تدفقات التأكيد، حدود المنفذ المالك — هذه يجب أن تبقى داخل runtime، مفروضة عند التنفيذ. لا تحرق tokens بجعل النموذج يقرأها. وبالتأكيد لا تعتمد على النموذج ليلتزم طواعية.
الخلاصة هنا:
المخطط هو لـ runtime، وليس للنموذج. النموذج يجب أن يرى كتالوج قدرات لغوي، وليس قاموس API.
أخيراً، أجرينا أبسط اختبار.
عرضنا كل الأدوات على النموذج كأوصاف لغوية مضغوطة للغاية. دعونا النموذج يقرأ. دعونا النموذج يختار.
النتيجة كانت جيدة بشكل مدهش.
بصراحة، كانت هذه النتيجة صفعة على الوجه. لأن كل معمارية معقدة بنيناها من قبل كانت مرتكزة على افتراض واحد: النموذج لا يمكنه التعامل مع رؤية أدوات كثيرة جداً، لذا يجب على runtime أن يصفي له.
لكن الاختبار أظهر أن هذا الافتراض — على الأقل في سياق Foundax الحالي — لا يصمد بالكامل.
السؤال ليس "هل يمكن تعريض كل الأدوات؟" السؤال هو "ما الذي تعرضه بالضبط على النموذج؟"
إذا كنت تعرض جداراً من مخططات API الكاملة — أوصاف طويلة، تعدادات حقول، مواصفات معاملات — ستغرق النموذج بالتأكيد. لكن إذا كنت تعرض كتالوج قدرات لغوياً خفيفاً وواضحاً، يمكن للنموذج أن يقرأ ويختار بنفسه — وقد يقوم بعمل أفضل من تصفية runtime المسبقة.
هذا ليس عودة إلى التعريض الكامل البدائي للبداية.
البداية كانت: إلقاء قاموس API الكامل على النموذج.
النهاية كانت: تسليم النموذج دليل عمليات مضغوط — قائمة قدرات لغوية خفيفة ومرقمة.
هذان شيئان مختلفان تماماً. الأول محيط من الأدوات. الثاني خريطة قابلة للقراءة.
لأكون محدداً. نظامنا لديه عشرات أدوات القراءة وأوامر الكتابة — أكثر من مائة أداة رسمية إجمالاً. كل مهمة تعرض على الأكثر حوالي اثنتي عشرة أداة للنموذج، متحكماً فيها بميزانية تعريض. مرحلة toolselection لها ميزانية سياق تبلغ عشرات الآلاف من الأحرف. وصف مخطّط كل أداة حوالي ألف ونيّف من الأحرف (بضع مئات من tokens). تعريض اثنتي عشرة أداة يعني حوالي عشرة إلى عشرين ألف حرف — حوالي أربعة إلى خمسة آلاف token. يمكن إدارته تماماً.
لكن إذا عرضنا كل الأدوات بمخططاتها الكاملة؟ ذلك يقارب مئتي ألف حرف — حوالي خمسين ألف token. هذا حقاً لا يتسع.
الرؤية الأساسية: runtime يزود توقيعات أدوات مضغوطة ومرقمة من السجل الرسمي. النموذج يقرأ بطاقة فهرس، وليس مدخلاً موسوعياً.
سيكون من السهل إساءة فهم هذا.
هل "دع النموذج يقرأ ويختار" يعني أن runtime غير مهم؟
العكس تماماً.
Runtime لا يزال حرجاً — لكن لا يجب أن يحاول التفكير نيابة عن النموذج قبل الأوان.
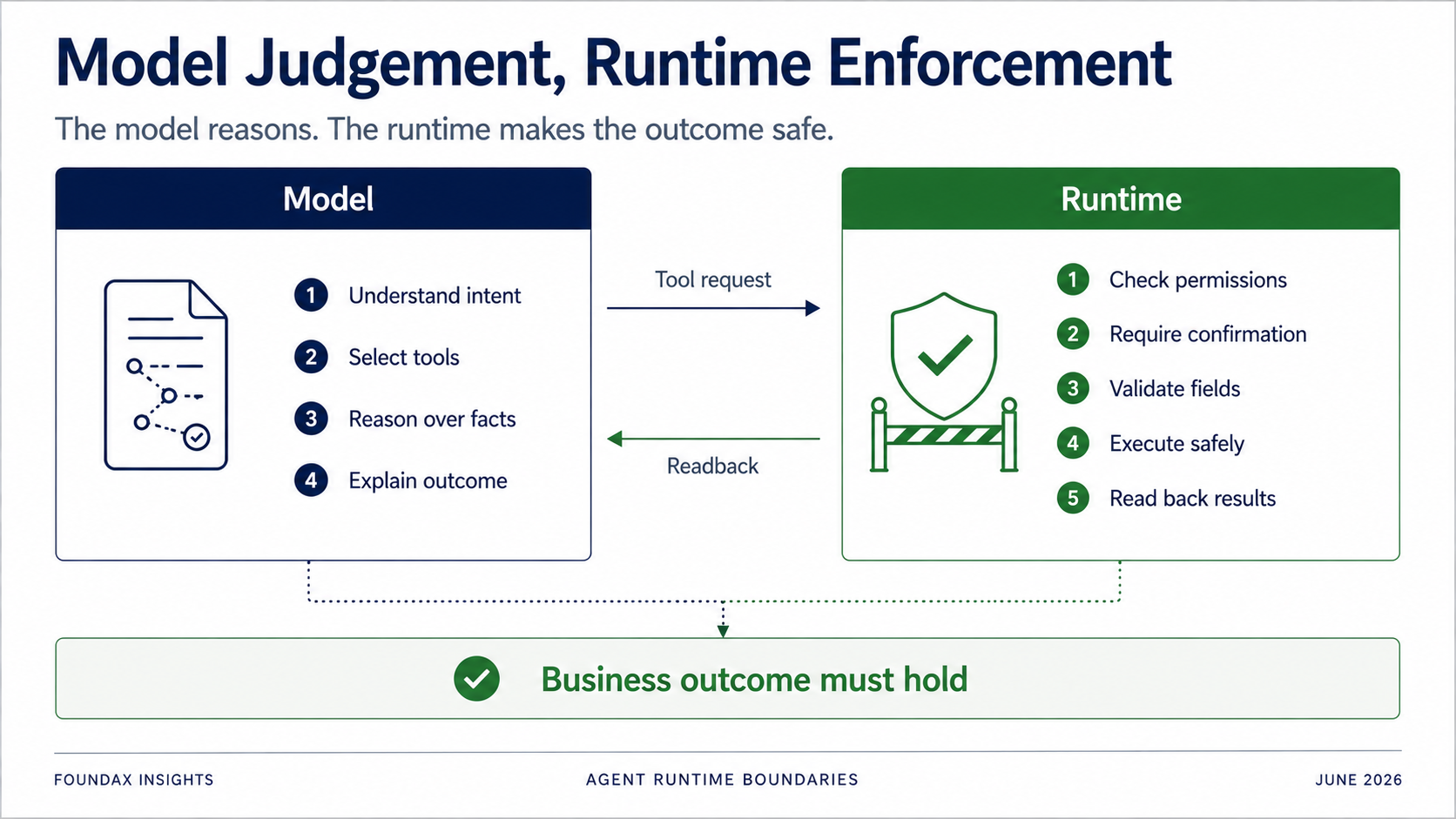
النموذج مسؤول عن الفهم، الحكم، الاختيار، والتفسير.
Runtime مسؤول عن الصلاحيات، التأكيد، التحقق من الحقول، حدود المنفذ المالك، التنفيذ الفعلي، و readback.
خاصة لعمليات الكتابة: لا يمكنك مطلقاً الاعتماد على النموذج لاتباع القواعد طواعية.
يمكن للنموذج أن يقول "أريد تحديث SEO هذا المنتج."
لكن Runtime يجب أن يحدد: هل يمتلك المستخدم الحالي الصلاحية؟ هل يتطلب هذا الإجراء تأكيداً؟ هل يجب أن يولد مسودة أولاً؟ هل الحقل في القائمة المسموحة؟ هل الكائن ينتمي للتاجر الحالي؟ هل نجحت الكتابة فعلاً؟ بعد readback، هل حالة العمل تطابق الهدف حقاً؟
هدف Agent ليس إثبات نجاح استدعاء أداة. إنه إثبات أن نتيجة العمل صامدة.
هذه الحدود جوهرية. ليس كل شيء يذهب للنموذج، وليس كل شيء يذهب لـ runtime. السؤال الحقيقي هو تقسيم العمل.
الدرس الأكبر من هذه الرحلة ليس أن 4.0 هي المعمارية الأفضل قطعياً.
إنه أن بناء Agent يجعلك تنجرف بسهولة خطيرة وراء سلسلة من الاهتمامات الهندسية الحقيقية.
قلق من أن المهام عالية التكرار ليست مستقرة عندما يرتجل النموذج كل مرة؟ → ابنِ workflows ثابتة.
قلق من أن السياق طويل جداً ويعاني النموذج من تشتت الانتباه؟ → ابنِ استكشاف الدليل.
قلق من أن نمو عدد الأدوات يجعل tokens تنفجر؟ → ابنِ استرجاع runtime.
قلق من أن الاسترجاع القائم على الكلمات المفتاحية هش جداً للمهام متعددة اللغات وعبر المجالات؟ → فكر في embeddings، التسجيل، إعادة الترتيب.
قلق من أن النموذج يختار أدوات دون قراءة القائمة الكاملة، أو يخرج إجابات قبل اكتمال الحقائق؟ → أضف حقول تقييد منظمة.
لا شيء من هذه المخاوف وهمي. كلها تقابل مشكلات حقيقية.
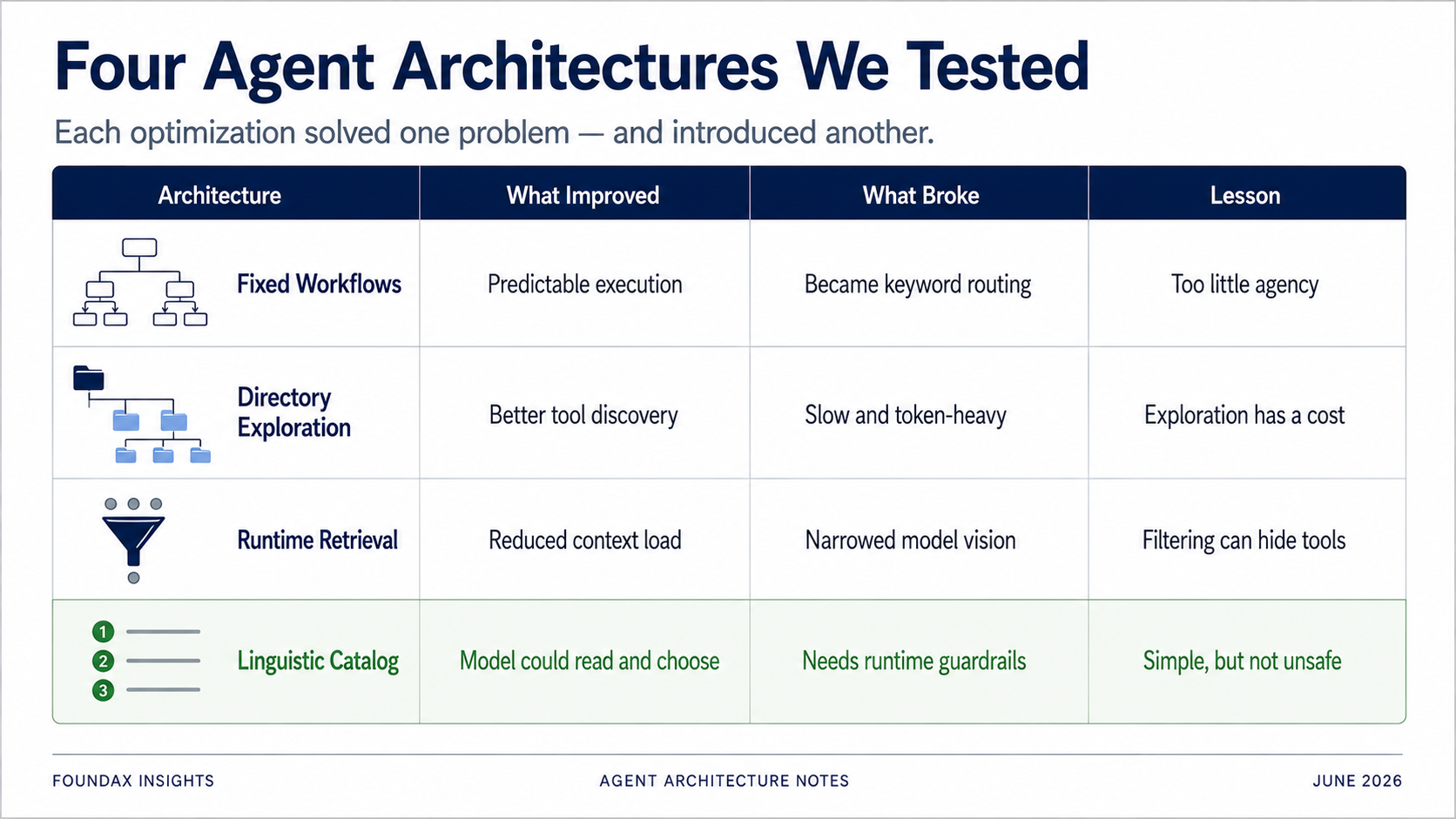
لكننا وجدنا — بالطريقة الصعبة — أن الكثير من الحلول عالجت مشكلة واحدة وأدخلت أخرى.
Workflows الثابتة أضافت استقراراً لكنها حدت من استدلال النموذج. استكشاف الدليل كان دقيقاً لكنه بطيء ومكثف tokens. استرجاع Runtime وفر السياق لكنه قد يحجب أدوات يحتاجها النموذج. Embeddings بدت ذكية لكنها، لاختيار أدوات أصيل LLM، كانت على الأرجح منعطفاً خاطئاً. الحقول المنظمة يمكنها تقييد النموذج، لكن أحياناً تعليمة بلغة طبيعية كانت تعمل بشكل أفضل.
والإدراك الأكثر أهمية:
هذه المشكلات حقيقية، لكنها ليست بالضرورة بنفس الشدة في مشروعك.
هل السياق الطويل يسبب فعلاً تشتت انتباه في حالة استخدامك؟ اختبره. هل عدد أدواتك يجعل تكاليف tokens غير مقبولة فعلاً؟ اختبره. هل التعريض الكامل للأدوات يجعل نموذجك كسولاً، معتمداً على المسار، أو عرضة للخطأ؟ اختبره. هل استرجاع Runtime يحجب فعلاً أدوات يحتاجها نموذجك؟ اختبره أيضاً.
أسهل خطأ في معمارية Agent هو معاملة "المشكلات الموجودة حقاً في مشروع شخص آخر" كـ "مشكلات موجودة قطعياً في مشروعك."
لذا فإن الخطوة الأولى في بناء Agent ليست تصميم معمارية معقدة لاستباق كل مشكلة محتملة. إنها الاختبار:
ما الذي يمكن للنموذج فهمه فعلاً في مجالك؟ هل يمكنه قراءة أوصاف أدواتك؟ هل يمكنه اختيار الأدوات بنفسه؟ أين يفوّت الحقائق؟ أي القرارات يمكنك تسليمها له؟ أيها يجب أن يفرضها runtime؟ أي الإجراءات تتطلب تأكيد المستخدم؟ أي النتائج يجب readback؟
الإجابات على هذه الأسئلة — وليس معمارية مرجعية من تدوينة — هي التي يجب أن تحدد تصميم Agent الخاص بك.
بالنسبة لـ Foundax، لدينا الآن وضوح: عمليات التجارة الإلكترونية مجال يعرفه النموذج جيداً. مسارات التحويل، صفحات المنتج، التسعير، الشحن، العروض الترويجية، الدفع، جودة الزيارات، SEO — هذه الأطر التحليلية تظهر مرات لا تحصى في بيانات التدريب. النموذج لا يفتقر إلى غرائز تحليل الأعمال. ما يفتقر إليه هو معرفة نظام Foundax المحدد: ما الحقائق التي يمكنه قراءتها، ما الكتابات التي يمكنه تحضيرها، أي الإجراءات يجب أن يمتلكها runtime، أي النتائج يجب readback.
لذا فإن Foundax Agent ليس عن تعليم النموذج كيفية تحليل التجارة الإلكترونية. إنه عن تسليم النموذج قدرات أعمال Foundax بلغة يمكنه قراءتها.
الخطوة الأولى في بناء Agent أعمال ليست تصميم معمارية مثالية. إنها اختبار كم يمكنك الوثوق فعلاً بالنموذج.
لسنا الوحيدين الذين يصلون إلى هذه الاستنتاجات.
في ديسمبر 2024، نشرت Anthropic دليلها "Building Effective Agents". رسالتها الأساسية: البساطة تفوز. ابدأ بأبسط حل ممكن. LLM معزز بإمكانية الوصول إلى الأدوات قد يكون كل ما تحتاجه. عندما قرأته حينها، أومأت برأسي. بعد أن عشت ما وصفته أعلاه، أفهمه عميقاً في أحشائي.
ثم في مايو 2026، عقدت LangChain مؤتمر Interrupt بتحول ملحوظ: تحول الموضوع من 'هل يمكن لـ agents الذهاب إلى الإنتاج' إلى 'النطاق المؤسسي وعمليات الإنتاج.' العنق الزجاجة الحقيقي، كما أكدت موادهم، ليس كتابة agents — إنه إدارتها في الإنتاج على نطاق واسع.
مجموعة متنامية من الأبحاث تعزز هذا الاتجاه. عمل Google DeepMind في 2025 حول قيود embeddings أظهر رياضياً أن المتجهات ذات الحجم الثابت تفقد المعلومات الهيكلية والعلائقية على النطاق الواسع — ذو صلة مباشرة بأي شخص يفكر في استرجاع الأدوات القائم على embedding. مفهوم Neo4j لـ "context engineering" يجادل بأن الذكاء الاصطناعي الموثوق يأتي من المعمارية، وليس من صياغة prompts ذكية.
تتماشى تجربتنا مع اتجاه نراه عبر الصناعة: أنماط Anthropic البسيطة/القابلة للتركيب، تركيز LangChain على عمليات الإنتاج بدلاً من تجريدات الأطر. بناء مسبق أقل، قدرة نموذج مباشرة أكثر — لكن دائماً متحقق منها مقابل الاستخدام الحقيقي، وليس متبناة كعقيدة. تصفية مسبقة أقل، حكم نموذج أكثر. السؤال ليس "كيف نبني معمارية مثالية حول النموذج؟" بل "كيف نعطي النموذج ما يحتاجه فعلاً ونبتعد عن طريقه؟"
هذا لا يجعل استنتاجات Foundax عالمية. أعمال مختلفة، نماذج مختلفة، أسطح أدوات مختلفة ستصل إلى إجابات مختلفة. ما هو عالمي هو المنهج: اختبر أولاً، صمم ثانياً.
س: هل يعني هذا أن عليّ دائماً تعريض كل الأدوات للنموذج؟
لا. يعتمد على عدد أدواتك، نموذجك، ميزانية السياق لديك، ومجالك. النقطة ليست "اعرض كل شيء دائماً." النقطة هي: اختبر قبل أن تصفي. لا تفترض أن النموذج لا يمكنه التعامل معها — تحقق. في حالتنا، حوالي اثنتي عشرة توقيع أداة مضغوطة لكل مهمة كانت قابلة للإدارة وفعالة. أرقامك قد تختلف.
س: متى يجب أن أستخدم workflows ثابتة بدلاً من ذلك؟
عندما تكون المهمة حتمية حقاً، وخطر الخطأ كارثياً، ومعرفة النموذج الخلفية في ذلك المجال ضعيفة. Workflows ليست خاطئة — إنها خاطئة عندما تستبدل استدلالاً كان يمكن للنموذج القيام به. استخدمها لدواعي السلامة والمعالجة اللاحقة الحتمية، وليس كبديل عن حكم النموذج.
س: ما الفرق بين الكتالوج اللغوي ومخطط API؟
الكتالوج اللغوي يخبر النموذج ما يمكن للأداة فعله، بلغة طبيعية مضغوطة — مثلاً: "قراءة: [12] Product Variants — SKU / السعر / المخزون / حالة التوفر." مخطط API يخبر النموذج كيف يستدعي الأداة، بمواصفات معاملات كاملة، تعدادات، وقيود. النموذج يحتاج إلى قائمة القدرات. runtime يحتاج إلى الدليل التقني. خلط هذين هو أحد أغلى الأخطاء التي يمكنك ارتكابها.
س: كيف تقرر ما يذهب للنموذج مقابل runtime؟
قاعدة إرشادية جيدة: النموذج يتولى الفهم، الحكم، الاختيار، والتفسير. Runtime يتولى الصلاحية، التنفيذ، التأكيد، التحقق، و readback. إذا كنت تطلب من النموذج فرض قواعد، فأنت على الجانب الخطأ من الخط. النموذج يقترح؛ Runtime يقرر وينفذ.
س: ماذا عن التكلفة؟ ألا يزيد تعريض أدوات أكثر من استخدام tokens؟
في حالتنا، كان الكتالوج اللغوي المضغوط فعلياً أرخص من استكشاف الدليل متعدد الجولات أو سلاسل الاسترجاع. كل إدخال أداة حوالي ألف ونيّف من الأحرف. مع حوالي اثنتي عشرة أداة معروضة لكل مهمة، المجموع حوالي عشرة إلى عشرين ألف حرف — حوالي أربعة إلى خمسة آلاف token. قارن ذلك بجولات متعددة من تفكيك النية، الاسترجاع، مراجعة المرشحين، وإعادة الاختيار. النهج الأبسط كان غالباً أكثر كفاءة في tokens، وليس أقل.
س: ما هي الرؤية الوحيدة الأكثر أهمية من هذه العملية؟
أن "مساعدة النموذج" و"تقييد النموذج" يمكن أن يبدوا متطابقين من منظور المصمم، لكن لهما تأثيرات متعاكسة على النظام. كل معمارية بنيناها كانت تهدف إلى المساعدة. معظمها انتهى بالتقييد. الفرق لم يتضح إلا من خلال الاختبار. إذا أخذت شيئاً واحداً من هذا المقال، فليكن هذا: اختبر ما يمكن لنموذجك فعله فعلاً قبل أن تبدأ في تصميم معمارية للتعويض عما تفترض أنه لا يمكنه فعله.