DTC 站點 vs 电商平台:agentic commerce 时代怎么分工
agentic commerce 会增强平台分发能力,但 DTC 站點仍然是品牌掌控商品事实、信任、客戶數據和测量的核心位置。
閱讀全文
Foundax 的 AI Agent 經歷了四代架構迭代——從固定 workflow 到目錄式探索,再到 runtime 檢索,最後回歸到一個輕量的語言化能力目錄。每一次「優化」,本質上都是在替模型做模型本可以自己做的決定。這是我們交過的所有學費。
我做 Foundax Agent 的過程中,有一個很荒謬的時刻。
我們前前後後試了很多架構:固定 workflow、目錄式工具探索、skills 推薦工具組合、runtime 召回、regex 匹配、結構化 plan、多輪 ReAct,甚至中間一度認真考慮過 embedding。
每一版看起來都有道理。
工具太多,所以要篩選。模型容易漏看,所以要約束。上下文太長,所以要召回。執行要安全,所以要流程化。業務要精準,所以底層工具必須原子化。
這些判斷單獨看都沒錯。
但最後我們做了一個最簡單、甚至有點粗暴的測試:把所有工具壓縮成一份輕量的語言化目錄,直接丟給模型,讓它自己讀、自己選。
結果效果出奇地好。
那一刻我真的有點無語。
因為這意味著,前面很多複雜設計,並不是在釋放模型能力,而是在提前假設模型不行,然後用架構把它層層包起來。
這篇文章不是想說「全量暴露工具就是最佳實踐」。
我真正想說的是:做業務型 Agent,最危險的不是模型不夠聰明,而是你還沒測試模型在你這個業務裏的能力邊界,就已經開始替它設計籠子。
Foundax 是一個電商 SaaS 平台。
所以 Foundax Agent 面對的,不是普通聊天,也不是單純的知識問答,而是商家在後台裏真實會遇到的經營問題。
商家不會說:
「請調用某個接口讀取 product variant 欄位。」
他們只會說:
「為甚麼這個商品賣不動?」
「我的西語頁面是不是還沒弄好?」
「這個商品能不能投 Google Shopping?」
「為甚麼很多人加購了,但是沒有付款?」
「幫我把缺失的 SEO 補上。」
這些問題聽起來都是自然語言,但背後牽涉的不是一句自然語言回答,而是一整套業務系統。
商品、SKU、庫存、價格、SEO、翻譯、促銷、運費、支付、checkout、訂單、退款、GMC feed、前台展示狀態——任何一個地方都可能影響最終結果。
所以 Foundax Agent 的目標不是「回答得像人」。
它真正要做的是:理解商家的真實意圖,找到系統裏對應的事實,選擇正確工具,必要時準備寫入,並且在 runtime 的約束下按權限、確認、readback 的規範執行。
用戶輸入可以是模糊的。但系統執行必須是精準的。
這就是後面所有架構糾結的起點。
我是一個有工程潔癖的人。
所以一開始設計 Foundax Agent 的時候,我天然不接受那種很粗的工具。
比如一個工具叫 analyzeProductReadiness,聽起來很方便,但它內部到底讀了甚麼欄位、用了甚麼判斷標準、有沒有權限邊界、寫入後能不能 readback,其實都會變得很模糊。
Foundax 不是一個 demo。商家讓你改 SEO,你不能拿一個黑盒工具在裏面亂改一通。
所以我一開始堅持底層工具原子化:
讀商品基礎欄位。讀商品 variants。讀庫存和價格。讀商品 SEO。讀商品翻譯。讀物流配置。讀支付配置。寫某個欄位。寫某個 locale 的內容。生成修改草稿。寫入後 readback。
每個工具盡量單一、清楚、互相不重疊。這樣執行精準,權限清晰,測試也容易。
這個判斷到現在我仍然覺得是對的。
真正的問題是另一個:底層工具越原子化,工具數量就越多;工具數量越多,模型就越難在上下文裏理解和選擇。
這是我遇到的第一個悖論。
底層工具越適合系統執行,就越不適合作為模型的認知介面。
原子化不是錯。錯的是把一堆原子工具直接丟給模型,然後期待模型每次都能穩定選對。
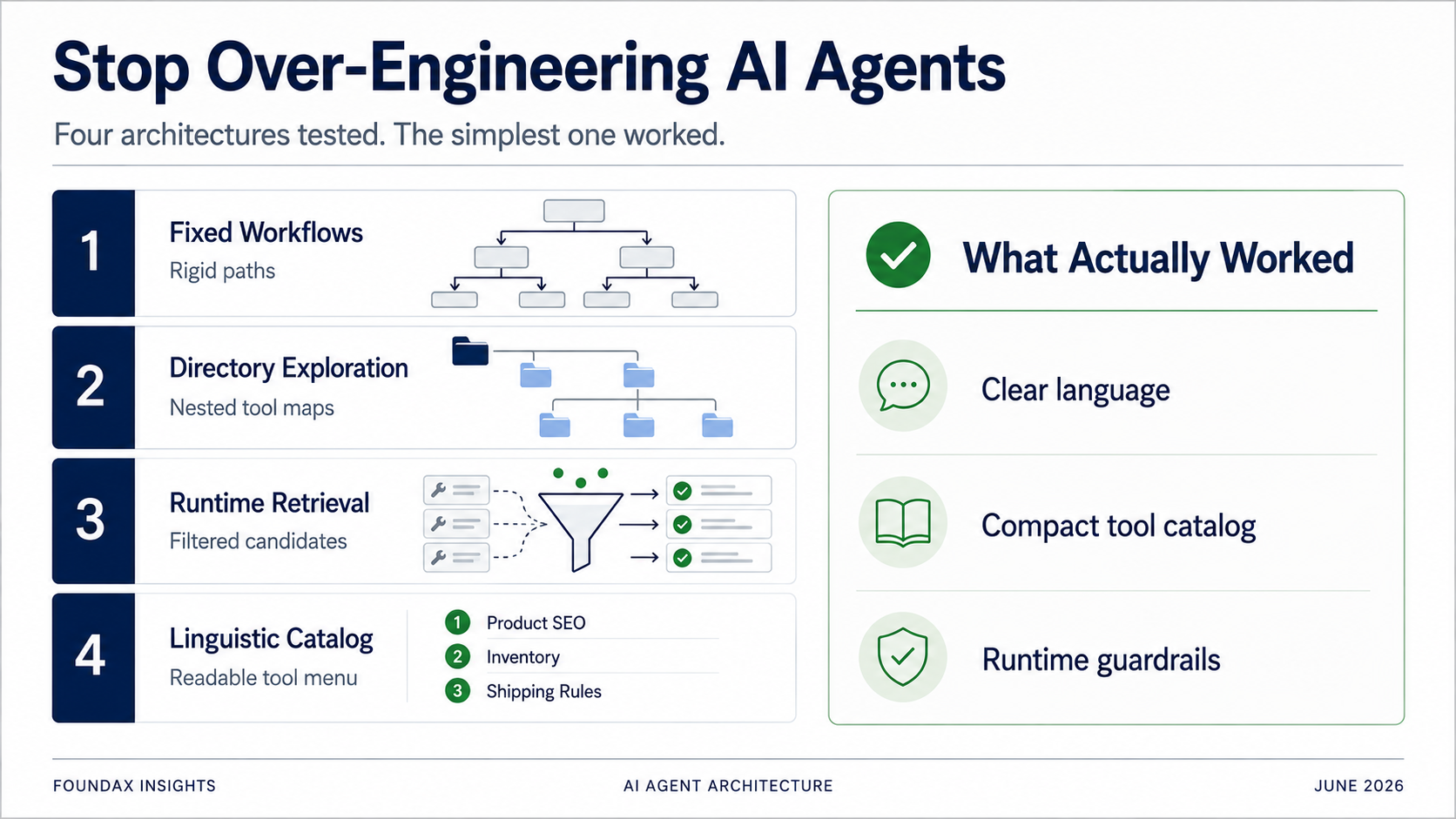
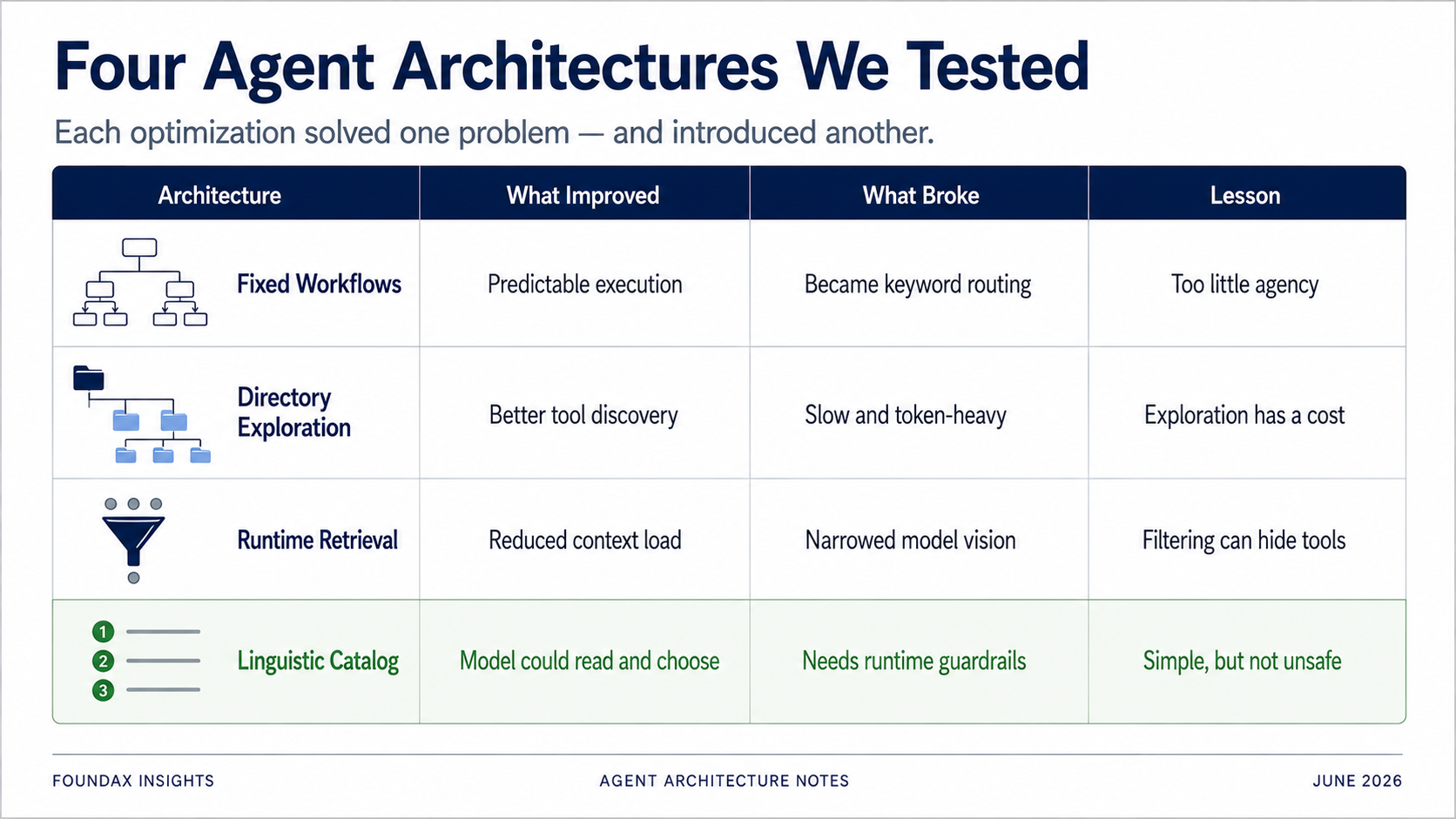
為了解決工具選擇問題,我們最早嘗試的是固定 workflow。
這個思路很自然。既然商家高頻任務有限,那就把常見任務提前編排好。
比如:商品 SEO 檢查。翻譯覆蓋檢查。商品上線預檢 檢查。轉化率低診斷。GMC 預檢 檢查。
模型只負責識別用戶意圖,然後命中某個 workflow,後面交給 runtime 固定執行。
這個方案看起來很安全,也很工程化。
但測試下來,很快發現它會退化成一個很蠢的 keyword 系統。
因為用戶表達太多樣了。同樣是想檢查商品 SEO,有人會說「SEO 全了嗎」,有人會說「這個頁面能不能被 Google 收錄」,有人會說「商品標題是不是沒寫好」,有人會說「為甚麼投廣告的時候 feed 一直報錯」。
為了讓各種說法都能命中任務,只能不斷堆關鍵詞、堆 alias、堆規則。最後系統不但不準,還越來越難維護。
更重要的是,模型在這個架構裏幾乎沒有發揮空間。它只是一個意圖分類器。真正的分析路徑、工具選擇、取證順序,全都由我們提前寫死。
這時我開始意識到一個問題:
如果所有任務都被提前編排成 workflow,那這個東西本質上就不是 Agent,而是一個披著 AI 外衣的流程工具。
固定 workflow 的本質,是用人的業務枚舉替代模型推理。它能讓系統更可控,但也會讓 Agent 失去 Agent 性。
後來我們換了一個方向。
既然全量工具太多,那就做成目錄。模型先選擇業務域,再展開子目錄,再選擇具體工具。
比如:商品。訂單。支付。物流。促銷。數據分析。GMC。
商品下面再有商品基礎資訊、SKU、庫存、價格、SEO、翻譯等工具。
這個方案比固定 workflow 準很多。因為模型不是靠關鍵詞命中某個流程,而是在一個結構化的工具地圖裏探索。它確實更容易找到正確工具。
但問題也很明顯:慢。
每次任務都要展開目錄。簡單問題也要走探索鏈路。token 消耗很大,延遲也高。
用戶只是問一句「這個商品 SEO 全了嗎」,Agent 卻像在翻一本很厚的後台說明書。
目錄式探索的問題不是方向錯,而是它把「理解工具系統」變成了每次運行時的成本。模型每次都要重新探索一遍系統,這在產品體驗上很難接受。
再後來,我們做了一個更複雜的方案。
模型先對用戶 prompt 做結構化理解:intent decomposition、關鍵詞、涉及的業務 domain、任務是 read、write、mix 還是 unknown。
然後把這個 plan 交給 runtime。runtime 根據 skills、regex、tool meta 去召回候選工具,再讓模型從候選工具裏選擇。模型讀完 facts 後,可以繼續決定要不要進入下一輪探索。
這一版看起來已經很像一個成熟的 Agent Runtime。它也確實帶來了一些階段性成果。
比如,我們發現結構化欄位可以改善模型行為。為了防止模型沒看全工具就直接選第一個看起來相關的工具,我們設計過類似 hasreadalltools 的欄位,讓模型在 tool call 時顯式聲明自己是否已經讀完候選工具。這個確實有幫助。
但更有意思的是,後來我們發現,一句簡單的自然語言提示,有時候比複雜結構化欄位更有效。
比如在模型選工具前,加一句:
「請結合用戶的業務目標,選擇所有必要的分析和寫入工具,不要只選擇第一個看起來相關的工具。」
在模型準備輸出答案前,再加一句:
「不要急著回答,先判斷需要的事實是否已經完整;如果不完整,可以繼續選擇工具。」
這樣反而明顯提升了模型的深度思考能力。
這件事給了我一個很大的提醒:
LLM 不是傳統程式。結構化協議有用,但模型始終是在讀語言、模仿推理。很多時候,一句準確、直接、低歧義的自然語言提示,比一個複雜欄位更有效。
但這一版架構也暴露了更深的問題。
runtime 召回工具,本來是為了解決上下文太長、模型選工具不準的問題。但 runtime 本質上還是規則系統。無論是 regex、skills、關鍵詞還是 domain 過濾,它都有可能在第一步就篩掉模型真正需要的工具。
比如用戶問:「為甚麼這個商品賣不動?」
這個問題可能涉及 analytics,也可能涉及商品內容、價格、庫存、促銷、運費、支付、checkout、流量來源、地域、裝置、SEO、頁面文案真實性。
如果 runtime 太早把它歸到某個 domain,模型的視野就被限制了。
這就是第三個悖論:
runtime 召回工具可以節省上下文,但也可能成為模型視野的天花板。
我們本來是想幫模型減少負擔,結果可能反過來限制了模型的判斷。
在工具愈來愈多之後,我中間一度真的認真考慮過 embedding。
這個想法很自然。用戶 prompt 轉成向量。tool description 轉成向量。算相似度。top-k 交給模型。
聽起來很標準,也很「AI」。
但我愈想愈覺得不對。
如果是廣告召回、內容推薦、海量文件檢索,embedding 很合理,因為候選集巨大,傳統系統確實不認識語言,需要把語義壓成向量,再做近似匹配。
但 Foundax 的工具不是開放世界裏的幾百萬個未知文件。它們是我們自己系統裏有限、可枚舉、可描述、可壓縮的業務能力。
而 LLM 本來最擅長的事情就是讀語言、理解語言、比較語義、判斷意圖。
那為甚麼還要先把工具說明轉成向量,再用一個相似度分數替 LLM 決定它能看到甚麼?
這就像一本書本來有目錄。目錄應該直接寫清楚每一章大概講甚麼。結果你把目錄變成一串數字編碼,再讓讀者透過數字距離判斷自己該讀哪一章。
這件事在傳統搜尋系統裏可以理解。但在 LLM-native 的 Agent 裏,我愈來愈覺得它是繞路。
對 Foundax 這種業務型 Agent 來說,優先級不是 vector retrieval,而是 language compression。也就是,把工具、文件、能力、邊界,壓縮成清楚、準確、高密度的語言上下文,讓模型直接讀。
我們還遇到過另一個典型問題:tool exposure 太重。
早期每個 tool 暴露給模型的資訊非常完整:function name、長 description、fact scope、answer boundary、excluded sources、fields enum、detailLevel enum、args 描述、observation 返回說明。
看起來很嚴謹。
但後來我發現,這裏面很多東西模型根本沒必要知道。
如果真正的查詢、寫入、欄位校驗、權限校驗、owner executor、confirmation、readback 都由 runtime 執行,那模型每次沒有必要讀完整 API schema。
模型真正需要知道的是:這個工具大概能查甚麼、對應哪個業務事實、甚麼時候可能相關、選擇它應該用哪個 id。
比如:
這就夠了。
甚至 can read / can write 也不需要每個工具重複暴露。候選短語裏的前綴「讀 / 寫 / 搜」已經足夠讓模型區分動作類型。真正的 read/write 權限、confirmation、owner executor 邊界,必須留在 runtime 內部強制校驗。不能浪費 token 讓模型讀,更不能倚賴模型自覺遵守。
這裏我們得到的結論是:
schema 是給 runtime 的,不是給模型的。模型應該看到語言化能力目錄,而不是 API 字典。
最後,我們做了一個最樸素的測試。
把所有 tools 以極簡語言化描述暴露給模型,讓模型自己看,自己選。
結果出奇地好。
說實話,這個結果有點打臉。因為我們之前所有複雜架構,幾乎都是圍繞一個假設:模型看不了太多工具,所以 runtime 必須幫它篩選。
但測試結果說明,這個假設至少在 Foundax 當前的場景裏,並不完全成立。
問題不是「工具能不能全部暴露」。問題是「你暴露給模型的到底是甚麼」。
如果暴露的是一堆完整 API schema、長 description、欄位 enum、參數說明,那確實會把模型淹沒。但如果暴露的是一份輕量、清楚、語言化的能力目錄,模型其實可以自己讀、自己選,而且效果可能比 runtime 先篩一輪更好。
這不是回到最開始的粗暴全量暴露。
最開始是:全量 API 字典丟給模型。
最後是:全量輕量能力菜單交給模型。
這兩件事完全不同。前者是工具海。後者是給模型一本壓縮過的操作手冊。
拿具體數字來說:我們的系統有 數十個讀工具和寫命令——共一百多個 canonical tools。每次任務暴露給模型的工具數受 exposure budget 控制,最多十幾個。toolselection 階段的上下文預算為 幾萬字符。每個工具的 schema 描述估約 一千多字符(約幾百 tokens)。十幾個工具暴露給模型的 schema 總量約 一兩萬字符 ≈ 四五千 tokens——完全在可控範圍內。
但如果全量暴露所有工具的完整 schema?約 近二十萬字符 ≈ 約五萬 tokens——確實放不下。
關鍵就在於:runtime 以極簡語言化描述暴露 compact numbered tool signatures,模型讀到的是一張索引卡,而不是百科全書的條目。
這裏很容易產生一個誤解:既然我們最後選擇讓模型自己看工具、自己選工具,是不是 runtime 就不重要了?
恰恰相反。
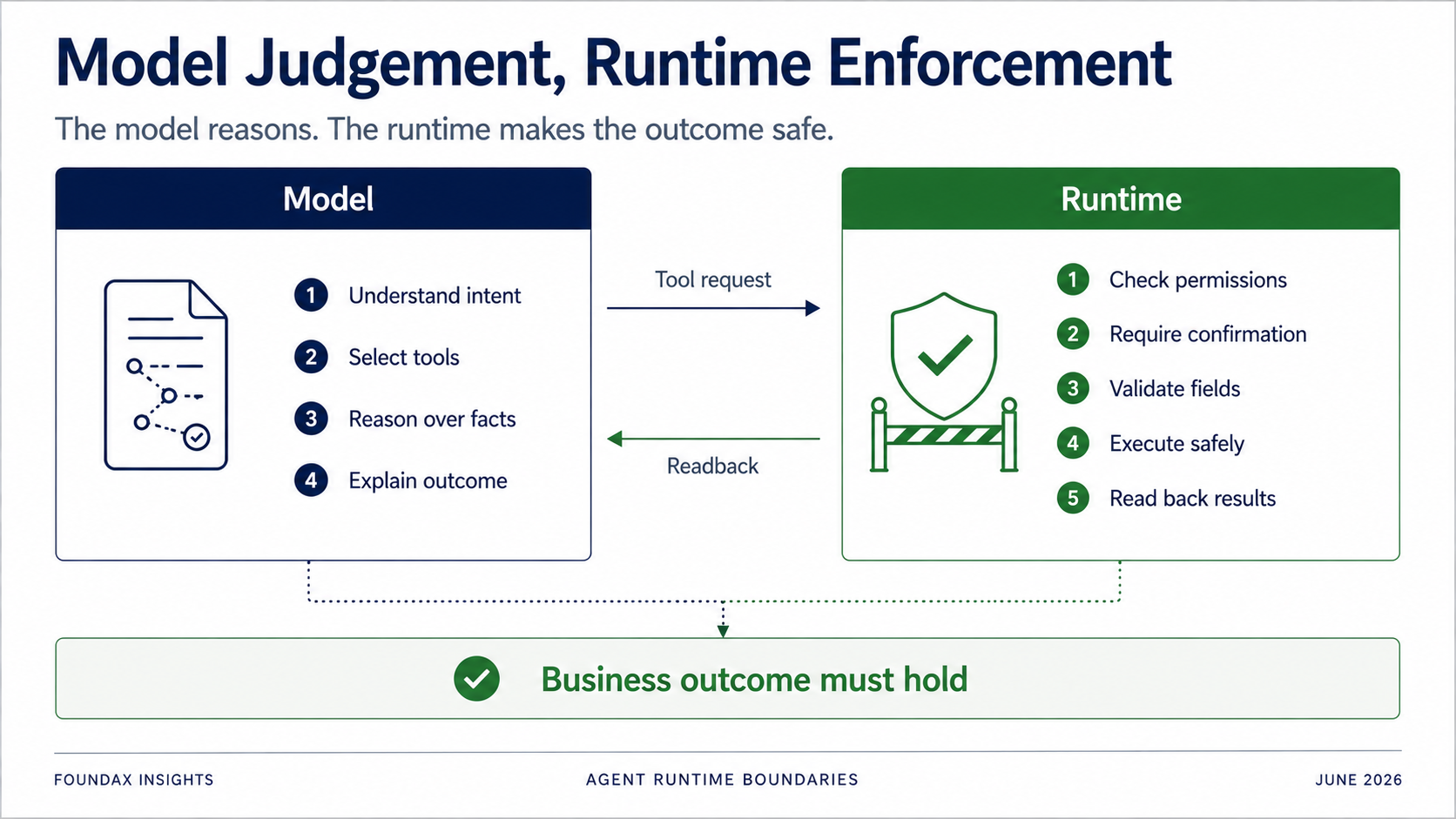
runtime 仍然非常重要,只是它不應該過早替模型思考。
模型可以負責理解、判斷、選擇、解釋。但 runtime 必須負責權限、確認、欄位校驗、owner executor 邊界、實際執行和 readback。
尤其是寫入場景,絕對不能倚賴模型自覺遵守規則。
模型可以說「我想更新這個商品的 SEO」。但 runtime 必須判斷:當前用戶有沒有權限、這個動作是否需要確認、它是不是只能先生成草稿、欄位是否在白名單裏、對象是否屬於當前 merchant、寫入後是否成功、readback 後業務狀態是否真的符合目標。
Agent 的目標不是證明 tool call 成功。而是證明業務結果成立。
這個邊界非常重要。不是所有東西都交給模型,也不是所有東西都交給 runtime。真正的問題是分工。
這輪探索最大的收穫,不是 4.0 一定最好。
而是我意識到,做 Agent 很容易被一連串真實工程問題推著走。
因為擔心高頻任務每次都靠模型臨場推理不夠穩定,所以想把部分業務場景做成固定 workflow。因為擔心上下文太長,模型出現 attention dilution,看不全工具說明,所以想做目錄式展開。因為擔心工具數量膨脹導致 token 爆炸,推高調用成本和回應延遲,所以想讓 runtime 先召回候選工具。因為擔心 runtime 靠關鍵詞召回太脆弱,遇到多語言、模糊表達、跨 domain 任務時匹配不準,所以一度想研究 embedding。因為擔心模型沒讀完工具就選擇,或者 facts 不完整就急著輸出答案,所以想加結構化欄位約束它。
這些擔心都不是空穴來風。它們都對應著真實問題。
只是後來我們發現,很多方案雖然解決了一個問題,卻又引入了另一個問題。
固定 workflow 穩定,但限制了模型推理。目錄式探索準確,但速度慢、token 浪費。runtime 召回省 context,但可能擋住模型真正需要的工具。embedding 看起來智能,但對 LLM-native 的工具選擇來說,可能是繞路。結構化欄位能約束模型,但有時一句自然語言提示效果更好。
更關鍵的是:
這些問題真實存在,但不一定在你的項目裏同樣嚴重。
上下文太長會不會導致 attention dilution?要測。工具數量多會不會導致 token 成本不可接受?要測。全量工具暴露會不會讓模型偷懶、路徑依賴、選錯工具?要測。runtime 召回會不會反而擋住模型需要的工具?也要測。
Agent 架構最容易犯的錯,就是把「別人項目裏真實存在的問題」,提前當成「自己項目裏一定存在的問題」。
所以做 Agent 的第一步,不是先設計一套複雜架構去預防所有可能的問題,而是先測試:
模型在你的業務裏到底能理解到甚麼程度?它能不能讀你的工具說明?它能不能自己選工具?它會在哪些場景漏事實?哪些環節可以交給它判斷?哪些環節必須由 runtime 強制兜底?哪些動作必須用戶確認?哪些結果必須 readback?
這些問題的答案,才應該決定你的 Agent 架構。
對 Foundax 來說,我們現在更清楚了:電商經營是模型非常熟悉的領域。轉化率、funnel、商品頁、價格、運費、促銷、支付、流量質素、SEO——這些分析框架在訓練語料裏出現過無數次。模型並不缺這類商業分析思路。它真正缺的是:在 Foundax 這個系統裏,它可以讀取哪些事實,可以準備哪些寫入,哪些動作必須由 runtime 接管,哪些結果必須 readback。
所以 Foundax Agent 不是要教模型怎麼做電商分析。而是要把 Foundax 的業務能力,用模型能讀懂的方式交給它。
做業務型 Agent,第一步不是設計完美架構,而是測試你到底能多大程度相信模型。
我們並不是唯一得出這些結論的人。
2024 年 12 月,Anthropic 發表了那篇後來被反覆引用的 《Building Effective Agents》。核心觀點:簡單就是好。從最簡單的方案開始。一個帶工具調用的增強型 LLM 可能就是你需要的全部。我當時讀到的時候點了點頭。等到親身經歷了上面這一切之後,我才真正從骨子裏理解了這句話。
然後,緊接著,2026 年 5 月,LangChain 在 Interrupt 大會上發佈了一個值得關注的轉向:大會主題從「Agent 能不能進生產環境」變成了「企業級規模與生產化營運」。他們強調的真正瓶頸不是寫 Agent,而是在規模化的生產環境中營運 Agent。
愈來愈多的研究也在佐證這個方向。Google DeepMind 2025 年關於 embedding 局限性的工作,從數學上證明了固定維度向量嵌入在大規模場景下會丟失結構性和關係性資訊——這對任何考慮用 embedding 做工具檢索的人來說,都是直接相關的警示。Neo4j 提出的「上下文工程」概念則強調:可靠的 AI 來自架構設計,而非聰明的話術。
我們的經驗與行業中正在浮現的方向一致:Anthropic 的 simple/composable 模式、LangChain 從框架抽象轉向生產營運的強調。更少的預製腳手架,更直接的模型能力——但始終要經過實際場景驗證,而不是當成教條照搬。少預篩選,多讓模型判斷。真正的問題不是「如何圍繞模型設計一套完美架構」,而是「如何把模型真正需要的東西用它能讀懂的方式交給它,然後讓開」。
這不意味著 Foundax 的結論放諸四海皆準。不同的業務、不同的模型、不同的工具面,會有不同的答案。放諸四海皆準的是方法:先測試,再設計。
Q:這意味著我應該始終把所有工具暴露給模型嗎?
不是。這取決於你的工具數量、使用的模型、上下文預算和業務領域。關鍵不是「始終暴露一切」,而是「先測試,再篩選」。不要假設模型處理不了——去驗證。在我們的場景中,每次任務暴露十幾個壓縮後的工具簽名是可控且有效的。你的數字可能不同。
Q:甚麼時候應該用固定 workflow?
當任務確實具有高度確定性、錯誤代價極高、且模型在該領域的背景知識薄弱時。workflow 本身沒有錯——錯的是用它來替代模型本可以完成的推理。把它用在安全兜底和確定性後處理上,不要用它替代模型判斷。
Q:語言化目錄和 API schema 的區別到底是甚麼?
語言化目錄告訴模型一個工具「能做甚麼」,用壓縮的自然語言——比如「讀:[12] 商品變體 — SKU / 價格 / 庫存 / 可售狀態」。API schema 告訴模型「怎麼調用」,包含完整參數規格、枚舉值、約束條件。模型需要的是能力菜單。runtime 需要的是技術手冊。把這兩者混淆,是你能犯的最昂貴的錯誤之一。
Q:如何判斷甚麼交給模型、甚麼交給 runtime?
一個實用的啟發式:模型負責理解、判斷、選擇、解釋。runtime 負責權限、執行、確認、校驗、readback。如果你讓模型去執行規則,你就站錯了邊。模型建議,runtime 決策並執行。
Q:成本呢?暴露更多工具不會增加 token 消耗嗎?
在我們的實際對比中,壓縮後的語言化目錄反而比多輪目錄探索或檢索鏈路更省錢。每個工具條目約一千多字符,每次暴露十幾個工具,總計約一兩萬字符——約四五千 tokens。相比之下,多輪 intent decomposition、檢索、候選審查、再選擇,往往消耗更多。簡單方案在 token 效率上經常勝出。
Q:整個過程中最重要的洞察是甚麼?
「幫助模型」和「限制模型」在設計師眼中可能看起來一模一樣,但對系統的影響截然相反。我們設計的每一層架構,初衷都是幫助模型。但大多數最終都在限制它。這個區別只有透過測試才能看清。如果你只能從這篇文章帶走一句話,那就是:在開始設計架構來彌補你假設模型做不到的事情之前,先測它到底能不能做到。