Site DTC và marketplace trong agentic commerce
Hướng dẫn thực tế để dùng marketplace trong khi xây dựng kênh DTC với dữ liệu sản phẩm, quan hệ khách hàng, nội dung và đo lường.
Đọc thêm
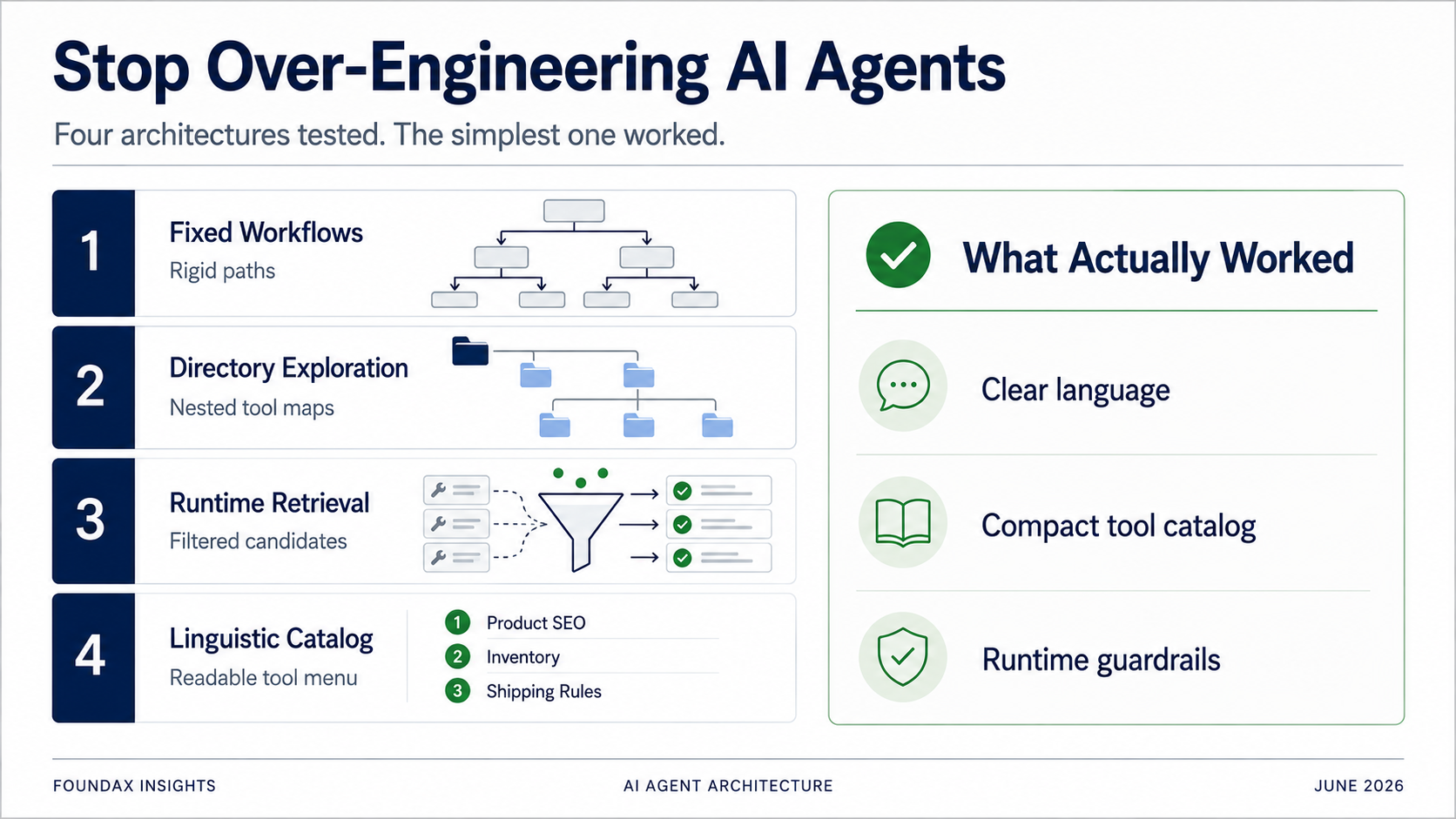
Bốn kiến trúc Agent, từ fixed workflows đến một linguistic catalog nhẹ. Mọi 'tối ưu hóa' thực ra là chúng tôi đang làm thay việc của model. Kiến trúc chiến thắng là kiến trúc ngừng cố tỏ ra thông minh.
Có một khoảnh khắc vô lý trong quá trình xây dựng Foundax Agent mà tôi cứ nghĩ mãi.
Chúng tôi đã thử rất nhiều kiến trúc. Fixed workflows. Directory-based tool exploration. Skill-based tool recommendation. Runtime retrieval. Regex matching. Structured plans. Multi-round ReAct loops. Có lúc, chúng tôi thậm chí đã cân nhắc nghiêm túc embedding-based retrieval.
Phiên bản nào trên giấy cũng hợp lý.
Quá nhiều tools, phải filter. Model bỏ sót thông tin, phải constrain. Context quá dài, phải retrieve. Execution phải an toàn, phải proceduralize. Business đòi độ chính xác, bottom-layer tools phải atomic.
Xét riêng từng cái, không cái nào sai.
Nhưng rồi chúng tôi chạy bài test đơn giản nhất — gần như thô sơ: nén tất cả tools thành một catalog ngôn ngữ nhẹ, quăng cho model, và để nó tự đọc, tự chọn.
Kết quả tốt bất ngờ.
Tôi thực sự không nói nên lời.
Bởi vì điều đó có nghĩa là hầu hết các thiết kế phức tạp của chúng tôi không hề mở khóa năng lực của model. Chúng chỉ đang giả định model sẽ thất bại, rồi bọc nó trong từng lớp kiến trúc để bù đắp.
Bài viết này không nói "expose hết tools là best practice."
Điều tôi thực sự muốn nói là: mối nguy lớn nhất khi xây dựng business Agent không phải là model chưa đủ thông minh — mà là bạn bắt đầu thiết kế cái lồng cho nó trước khi bạn thậm chí còn chưa test xem nó làm được gì trong domain của bạn.
Foundax là một nền tảng ecommerce SaaS.
Vì vậy Foundax Agent không xử lý chat thông thường hay Q&A kiến thức chung. Nó xử lý các vấn đề vận hành thực tế mà merchant gặp trong backend.
Merchant không nói:
"Vui lòng gọi product variant read API."
Họ nói:
"Sao sản phẩm này không bán được?"
"Trang tiếng Tây Ban Nha của tôi xong chưa?"
"Sản phẩm này chạy Google Shopping được không?"
"Sao nhiều người thêm giỏ hàng mà không thanh toán?"
"Điền SEO còn thiếu cho tôi."
Những câu hỏi này nghe như natural language, nhưng đằng sau mỗi câu là cả một hệ thống kinh doanh. Sản phẩm, SKU, tồn kho, giá, SEO, bản dịch, khuyến mãi, vận chuyển, thanh toán, checkout, đơn hàng, hoàn tiền, GMC feed, trạng thái hiển thị storefront — bất kỳ thứ gì trong số này đều có thể ảnh hưởng đến kết quả.
Vì vậy mục tiêu của Foundax Agent không phải là "trả lời giống người."
Điều nó thực sự cần làm là: hiểu ý định thực của merchant, tìm facts tương ứng trong hệ thống, chọn đúng tools, chuẩn bị write khi cần, và thực thi dưới các ràng buộc của runtime — với permissions, confirmation, và readback đầy đủ.
Input từ người dùng có thể mơ hồ. Nhưng execution của hệ thống phải chính xác.
Sự căng thẳng đó là điểm khởi đầu cho mọi vấn đề kiến trúc phía sau.
Tôi là người có tính cầu toàn kỹ thuật.
Vì vậy khi bắt đầu thiết kế Foundax Agent, tôi theo bản năng từ chối những công cụ thô.
Một công cụ tên analyzeProductReadiness nghe tiện. Nhưng bên trong nó đọc những field nào? Dùng tiêu chí gì? Ranh giới permission ở đâu? Write xong có readback được không? Tất cả đều trở nên mờ đục.
Foundax không phải là demo. Khi merchant yêu cầu bạn sửa SEO, bạn không thể dùng một công cụ black-box âm thầm thay đổi mọi thứ.
Vì vậy tôi khăng khăng dùng atomic bottom-layer tools:
Đọc product base fields. Đọc product variants. Đọc inventory và pricing. Đọc product SEO. Đọc product translations. Đọc shipping configuration. Đọc payment configuration. Write một field cụ thể. Write content cho một locale cụ thể. Tạo modification draft. Readback sau write.
Mỗi tool đơn mục đích, rõ ràng, không chồng lấn. Execution chính xác, permissions rõ ràng, dễ test.
Tôi vẫn nghĩ phán đoán này là đúng.
Vấn đề thực sự là thứ khác: bottom-layer tools càng atomic, số lượng tools càng nhiều. Tools càng nhiều, model càng khó hiểu và chọn trong context.
Đó là nghịch lý đầu tiên.
Bottom-layer tool càng phù hợp cho system execution, nó càng không phù hợp làm cognitive interface cho model.
Atomicity không phải là sai lầm. Sai lầm là đổ một đống atomic tools thẳng trước mặt model và mong nó luôn chọn đúng.
Để giải quyết vấn đề chọn tool, nỗ lực đầu tiên của chúng tôi là fixed workflows.
Đây là bản năng tự nhiên. Nếu các task tần suất cao của merchant là hữu hạn, hãy script sẵn chúng.
Product SEO check. Translation coverage check. Product launch launch check. Low conversion diagnosis. GMC preflight check.
Việc của model là nhận diện ý định người dùng, map vào một workflow, rồi giao cho runtime thực thi cố định.
Giải pháp này trông an toàn. Trông có vẻ engineered.
Nhưng khi test, nó nhanh chóng thoái hóa thành một hệ thống keyword ngớ ngẩn.
Cách người dùng diễn đạt quá đa dạng. Một người nói "SEO của tôi đầy đủ chưa?" Người khác nói "Google index được trang này không?" Người khác nữa nói "tiêu đề sản phẩm tôi sai à?" Người khác nói "sao feed cứ báo lỗi khi tôi chạy quảng cáo?"
Để mọi biến thể đều trúng một task, bạn liên tục thêm keywords, aliases, rules. Cuối cùng hệ thống không chính xác, và còn khó bảo trì hơn bao giờ hết.
Quan trọng hơn, model gần như không có không gian để hoạt động. Nó chỉ là một intent classifier. Đường phân tích thực tế, việc chọn tool, trình tự thu thập bằng chứng — tất cả đều do chúng tôi định sẵn.
Đó là lúc tôi nhận ra:
Nếu mọi task đều được script sẵn trong workflow, thứ đó không còn là Agent nữa — nó là một workflow tool mặc áo AI.
Fixed workflows, về cốt lõi, thay thế reasoning của model bằng sự liệt kê business của con người. Chúng làm hệ thống dễ kiểm soát hơn, nhưng tước đi Agency của Agent.
Tiếp theo, chúng tôi xoay trục.
Thay vì đổ tất cả tools cùng lúc, tổ chức chúng thành directory. Model chọn business domain trước, rồi mở rộng subdirectory, rồi chọn tool cụ thể.
Sản phẩm. Đơn hàng. Thanh toán. Vận chuyển. Khuyến mãi. Analytics. GMC.
Dưới "Sản phẩm": thông tin cơ bản, SKU, tồn kho, giá, SEO, bản dịch.
Cách này chính xác hơn fixed workflows rất nhiều. Model không match keywords vào một đường dẫn định sẵn — nó đang khám phá một bản đồ tool có cấu trúc. Nó thực sự tìm đúng tools thường xuyên hơn.
Nhưng vấn đề rõ ràng: tốc độ.
Mỗi task đều cần directory traversal. Những câu hỏi đơn giản vẫn đi qua exploration chain. Token consumption cao. Latency cao.
Merchant hỏi "SEO sản phẩm này đầy đủ chưa?" và Agent hành xử như đang lật từng trang một cuốn cẩm nang backend dày cộp.
Directory exploration không sai hướng. Vấn đề là nó biến "hiểu hệ thống tool" thành chi phí cho mỗi lần invocation. Model phải khám phá lại hệ thống từ đầu mỗi lần, điều này khó chấp nhận với tư cách trải nghiệm sản phẩm.
Tiếp theo, chúng tôi xây dựng thứ gì đó tinh vi hơn.
Model đầu tiên tạo ra hiểu biết có cấu trúc về prompt của người dùng: intent decomposition, keywords, business domain liên quan, và task là read, write, mixed, hay unknown.
Sau đó plan này đến runtime. Runtime dùng skills, regex matching, và tool metadata để retrieve candidate tools. Model chọn từ các candidates. Sau khi đọc facts, model có thể quyết định tiếp tục khám phá ở vòng khác.
Phiên bản này trông giống một Agent Runtime trưởng thành. Và nó thực sự mang lại một số tiến bộ.
Ví dụ, chúng tôi phát hiện structured fields có thể cải thiện hành vi model. Để ngăn model vớ ngay tool đầu tiên trông có vẻ liên quan mà không đọc hết candidate list, chúng tôi thiết kế field hasreadalltools — yêu cầu model tuyên bố rõ ràng đã đọc hết candidates trước khi gọi tool. Điều đó thực sự hiệu quả.
Nhưng thú vị hơn: sau đó chúng tôi phát hiện một instruction natural language được viết tốt có thể hiệu quả hơn một structured field phức tạp.
Trước khi model chọn tools, chúng tôi thêm:
"Dựa trên mục tiêu business của người dùng, chọn tất cả analysis và write tools cần thiết. Đừng chỉ chọn tool đầu tiên trông có vẻ liên quan."
Trước khi model chuẩn bị output câu trả lời, chúng tôi thêm:
"Đừng vội trả lời. Trước tiên xác định xem facts cần thiết đã đầy đủ chưa. Nếu chưa, tiếp tục chọn tools."
Những prompt đơn giản này cải thiện đáng kể độ sâu reasoning của model.
Đây là một hồi chuông cảnh tỉnh lớn:
LLM không phải là chương trình truyền thống. Structured protocols hữu ích, nhưng model luôn đọc ngôn ngữ và bắt chước reasoning. Thường thì một instruction natural language chính xác, trực tiếp, ít mơ hồ hoạt động tốt hơn một structured field phức tạp.
Nhưng kiến trúc này cũng phơi bày một vấn đề sâu hơn.
Runtime tool retrieval được thiết kế để giải quyết context overload và chọn tool không chính xác. Nhưng runtime, về bản chất, là một hệ thống rule.
Dù là regex, skills, keywords, hay domain filtering — nó có thể lọc ra những tools model thực sự cần, ngay từ lượt đầu tiên.
Hãy xét một merchant hỏi: "Sao sản phẩm này không bán được?"
Câu hỏi đó có thể liên quan đến analytics. Nó cũng có thể liên quan đến nội dung sản phẩm, giá, tồn kho, khuyến mãi, vận chuyển, thanh toán, checkout, nguồn traffic, địa lý, thiết bị, SEO, tính xác thực của page copy.
Nếu runtime quá vội vàng xếp nó vào một domain duy nhất, tầm nhìn của model bị hạn chế.
Đó là nghịch lý thứ ba:
Runtime tool retrieval tiết kiệm context — nhưng nó cũng có thể trở thành trần tầm nhìn của model.
Chúng tôi khởi đầu với ý định giảm gánh nặng cho model, và kết thúc bằng việc có khả năng hạn chế phán đoán của model.
Khi số lượng tools tăng lên, tôi đã nghiêm túc cân nhắc embedding-based retrieval.
Ý tưởng rất tự nhiên. User prompt → vector. Tool descriptions → vectors. Similarity score. Top-k cho model.
Nghe chuẩn. Nghe "AI-native."
Nhưng càng nghĩ, tôi càng thấy nó sai.
Với ad retrieval, content recommendation, hay tìm kiếm tài liệu khổng lồ, embeddings có lý. Tập candidate cực lớn, và hệ thống truyền thống thực sự không hiểu ngôn ngữ. Bạn cần nén semantics thành vectors để approximate matching.
Nhưng tools của Foundax không phải là hàng triệu tài liệu không xác định trong thế giới mở. Chúng là các business capabilities hữu hạn, đếm được, mô tả được, nén được trong chính hệ thống của chúng tôi.
Và sức mạnh lớn nhất của LLM chính là đọc ngôn ngữ, hiểu ngôn ngữ, so sánh semantics, và phán đoán ý định.
Vậy tại sao phải chuyển tool descriptions thành vectors, rồi dùng similarity score để quyết định — thay mặt model — nó được thấy gì?
Nó giống như có một cuốn sách với mục lục hoàn toàn đọc được. Thay vì đọc nó, bạn encode mục lục thành các con số và bắt người đọc phán đoán nên đọc chương nào dựa trên khoảng cách số học.
Điều đó có lý trong các hệ thống tìm kiếm truyền thống. Trong một Agent LLM-native, tôi ngày càng tin đó là một ngã rẽ sai.
Với một business Agent như Foundax, ưu tiên không phải là vector retrieval. Mà là language compression — nén tools, tài liệu, capabilities, và boundaries thành linguistic context rõ ràng, chính xác, mật độ cao mà model có thể đọc trực tiếp.
Chúng tôi cũng gặp một vấn đề kinh điển khác: tool exposure quá nặng.
Thời gian đầu, mỗi tool tiết lộ thông tin rất đầy đủ cho model: function name, long description, fact scope, answer boundary, excluded sources, field enums, detail level enums, argument descriptions, observation return format.
Trông có vẻ rigorous.
Nhưng cuối cùng tôi nhận ra: model không cần biết hầu hết những thứ này.
Nếu query execution, field validation, permission checking, owner executor boundaries, confirmation flows, và readback thực tế đều được xử lý bởi runtime, thì model không có việc gì phải đọc full API schema mỗi lần.
Những gì model thực sự cần biết:
Ví dụ:
Thế là đủ.
Prefix "Read / Write / Search" trong candidate list đã đủ để model phân biệt loại hành động. Permissions thực cho read/write, confirmation flows, owner executor boundaries — những thứ đó phải nằm trong runtime, được thực thi lúc execution. Đừng đốt tokens để model đọc chúng. Và tuyệt đối đừng dựa vào model tự nguyện tuân thủ.
Kết luận ở đây:
Schema dành cho runtime, không dành cho model. Model nên thấy một linguistic capability catalog, không phải một API dictionary.
Cuối cùng, chúng tôi chạy bài test đơn giản nhất.
Expose tất cả tools cho model dưới dạng mô tả ngôn ngữ cực kỳ nén. Để model đọc. Để model chọn.
Kết quả tốt bất ngờ.
Thành thật mà nói, kết quả này hơi tát vào mặt chúng tôi. Bởi vì mọi kiến trúc phức tạp chúng tôi xây trước đó đều neo vào một giả định: model không thể xử lý việc thấy quá nhiều tools, vì vậy runtime phải filter cho nó.
Nhưng bài test cho thấy giả định đó — ít nhất là trong context hiện tại của Foundax — không hoàn toàn đúng.
Câu hỏi không phải là "có thể expose tất cả tools không?" Câu hỏi là "bạn đang expose chính xác cái gì cho model?"
Nếu bạn expose một bức tường API schema đầy đủ — long descriptions, field enums, parameter specs — bạn chắc chắn sẽ nhấn chìm model. Nhưng nếu bạn expose một linguistic capability catalog nhẹ, rõ ràng, model có thể tự đọc và tự chọn — và có thể làm tốt hơn cả pre-filtering của runtime.
Đây không phải là quay lại cách expose thô sơ lúc ban đầu.
Lúc ban đầu là: đổ nguyên API dictionary lên model.
Lúc cuối là: đưa cho model một cuốn operations manual nén — một menu năng lực ngôn ngữ nhẹ, được đánh số.
Hai thứ này hoàn toàn khác nhau. Cái trước là biển tools. Cái sau là bản đồ đọc được.
Để tôi nói cụ thể. Hệ thống của chúng tôi có hàng chục read tools và write commands — tổng cộng hơn một trăm canonical tools. Mỗi task expose tối đa khoảng hơn chục tools cho model, được kiểm soát bởi exposure budget. Phase toolselection có context budget hàng chục nghìn ký tự. Mô tả schema của mỗi tool khoảng hơn một nghìn ký tự (vài trăm tokens). Expose hơn chục tools nghĩa là khoảng mười đến hai mươi nghìn ký tự — khoảng bốn đến năm nghìn tokens. Rất dễ quản lý.
Nhưng nếu chúng tôi expose tất cả tools với full schema? Đó là gần hai trăm nghìn ký tự — khoảng năm mươi nghìn tokens. Thực sự không vừa.
Key insight: runtime cung cấp compact, numbered tool signatures từ canonical registry. Model đọc một index card, không phải một encyclopedia entry.
Sẽ dễ hiểu lầm điều này.
"Để model tự đọc và chọn" có nghĩa là runtime không quan trọng?
Hoàn toàn ngược lại.
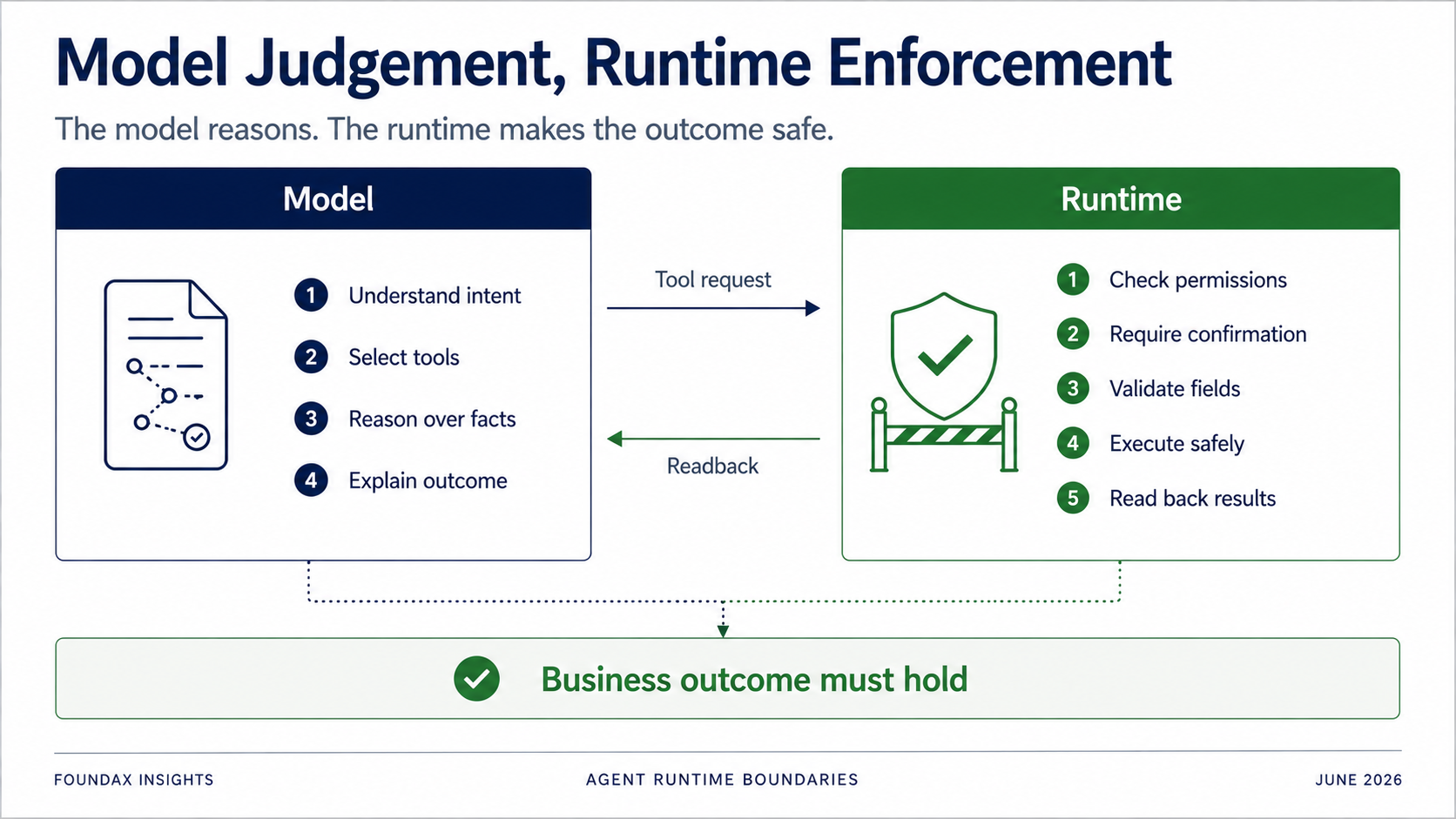
Runtime vẫn cực kỳ quan trọng — nó chỉ không nên cố gắng nghĩ thay model quá sớm.
Model chịu trách nhiệm: understanding, judgment, selection, và explanation.
Runtime chịu trách nhiệm: permissions, confirmation, field validation, owner executor boundaries, execution thực tế, và readback.
Đặc biệt với write operations: bạn tuyệt đối không được dựa vào model tự nguyện tuân theo rules.
Model có thể nói "tôi muốn cập nhật SEO của sản phẩm này."
Nhưng runtime phải xác định: Người dùng hiện tại có permission không? Hành động này có cần confirmation không? Có nên chỉ tạo draft trước không? Field có trong allowlist không? Object có thuộc về merchant hiện tại không? Write có thực sự thành công không? Sau readback, business state có thực sự khớp với mục tiêu không?
Mục tiêu của Agent không phải là chứng minh một tool call thành công. Mà là chứng minh business outcome được đảm bảo.
Ranh giới này là thiết yếu. Không phải mọi thứ đều đến model, và không phải mọi thứ đều đến runtime. Câu hỏi thực sự là phân công lao động.
Bài học lớn nhất từ hành trình này không phải là 4.0 là kiến trúc tốt nhất.
Mà là việc xây dựng Agent khiến bạn dễ dàng bị cuốn theo một chuỗi các mối lo ngại kỹ thuật thực sự.
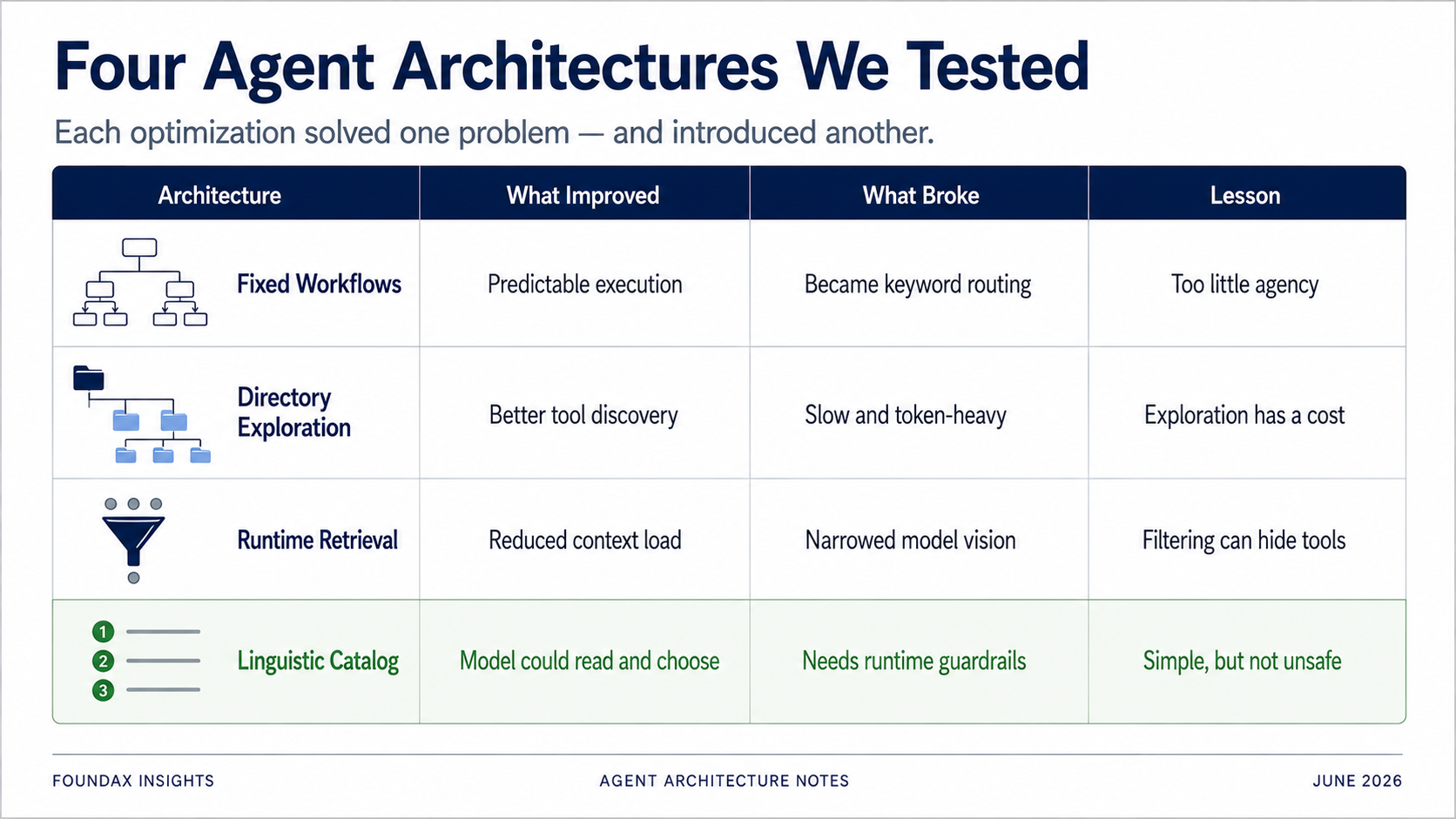
Lo rằng high-frequency tasks không ổn định khi model improvise mỗi lần? → Xây fixed workflows.
Lo rằng context quá dài và model bị attention dilution? → Xây directory exploration.
Lo rằng số lượng tools tăng khiến tokens bùng nổ? → Xây runtime retrieval.
Lo rằng keyword-based retrieval quá mong manh cho tác vụ đa ngôn ngữ và cross-domain? → Cân nhắc embeddings, scoring, reranking.
Lo rằng model chọn tools mà không đọc hết list, hoặc output câu trả lời trước khi facts đầy đủ? → Thêm structured constraint fields.
Những mối lo này không phải tưởng tượng. Chúng đều tương ứng với các vấn đề thực.
Chỉ là chúng tôi phát hiện ra — một cách đau đớn — rằng nhiều giải pháp giải quyết một vấn đề trong khi tạo ra một vấn đề khác.
Fixed workflows thêm ổn định nhưng chặn reasoning của model. Directory exploration chính xác nhưng chậm và tốn token. Runtime retrieval tiết kiệm context nhưng có thể chặn tools model cần. Embeddings trông thông minh nhưng với LLM-native tool selection, có lẽ là ngã rẽ sai. Structured fields có thể constrain model, nhưng đôi khi một prompt natural language hoạt động tốt hơn.
Và nhận thức quan trọng hơn:
Những vấn đề này là thực, nhưng chúng không nhất thiết nghiêm trọng như nhau trong dự án của bạn.
Context dài có thực sự gây attention dilution cho use case của bạn không? Test đi. Số lượng tools có thực sự làm chi phí token không chấp nhận được không? Test đi. Full tool exposure có thực sự làm model lười, phụ thuộc đường dẫn, hoặc dễ lỗi không? Test đi. Runtime retrieval có thực sự chặn tools model cần không? Cũng test đi.
Sai lầm dễ mắc nhất trong Agent architecture là coi "vấn đề thực sự tồn tại trong dự án của người khác" như "vấn đề chắc chắn tồn tại trong dự án của bạn."
Vì vậy bước đầu tiên khi xây dựng Agent không phải là thiết kế một kiến trúc phức tạp để phòng ngừa mọi vấn đề có thể. Mà là test:
Model thực sự hiểu được gì trong domain của bạn? Nó có đọc được tool descriptions của bạn không? Nó có tự chọn tools được không? Nó bỏ sót facts ở đâu? Những quyết định nào bạn có thể giao cho nó? Những gì runtime phải enforce? Hành động nào cần user confirmation? Kết quả nào phải readback?
Câu trả lời cho những câu hỏi này — không phải reference architecture từ một blog post — mới nên quyết định thiết kế Agent của bạn.
Với Foundax, giờ chúng tôi đã rõ: vận hành ecommerce là domain model biết rất rõ. Conversion funnels, product pages, pricing, shipping, promotions, payment, traffic quality, SEO — những khung phân tích này xuất hiện vô số lần trong training data. Model không thiếu bản năng phân tích business. Điều nó thiếu là kiến thức về hệ thống cụ thể của Foundax: nó có thể đọc những facts nào, có thể chuẩn bị những write nào, những hành động nào runtime phải sở hữu, những kết quả nào phải readback.
Vì vậy Foundax Agent không phải là dạy model cách phân tích ecommerce. Mà là trao cho model business capabilities của Foundax bằng ngôn ngữ nó đọc được.
Bước đầu tiên của việc xây dựng business Agent không phải là thiết kế một kiến trúc hoàn hảo. Mà là test xem bạn thực sự có thể tin tưởng model đến đâu.
Chúng tôi không phải là những người duy nhất đi đến những kết luận này.
Tháng 12 năm 2024, Anthropic công bố hướng dẫn "Building Effective Agents". Thông điệp cốt lõi: sự đơn giản chiến thắng. Bắt đầu với giải pháp đơn giản nhất có thể. Một augmented LLM với tool access có thể là tất cả những gì bạn cần. Khi đọc lúc đó, tôi gật đầu. Sau khi sống qua những gì tôi mô tả ở trên, tôi hiểu nó một cách thấm thía.
Rồi tháng 5 năm 2026, LangChain tổ chức hội nghị Interrupt với một cú xoay trục đáng chú ý: chủ đề chuyển từ 'agents có lên production được không' sang 'enterprise scale và production operations.' Nút thắt thực sự, như tài liệu của họ nhấn mạnh, không phải là viết agents — mà là quản lý chúng trong production ở quy mô lớn.
Ngày càng nhiều nghiên cứu củng cố hướng đi này. Công trình năm 2025 của Google DeepMind về giới hạn của embedding cho thấy về mặt toán học rằng fixed-size vector embeddings mất thông tin cấu trúc và quan hệ khi scale lớn — liên quan trực tiếp đến bất kỳ ai đang cân nhắc embedding-based tool retrieval. Khái niệm "context engineering" của Neo4j lập luận rằng AI đáng tin cậy đến từ architecture, không phải từ clever prompt phrasing.
Trải nghiệm của chúng tôi phù hợp với hướng đi chúng tôi thấy trong toàn ngành: simple/composable patterns của Anthropic, sự nhấn mạnh của LangChain vào production operations hơn là framework abstractions. Ít scaffolding đóng sẵn hơn, nhiều năng lực model trực tiếp hơn — nhưng luôn được validate với usage thực tế, không áp dụng như giáo điều. Ít pre-filtering hơn, nhiều model judgment hơn. Câu hỏi không phải là "làm sao để xây một kiến trúc hoàn hảo quanh model?" Mà là "làm sao để đưa cho model những gì nó thực sự cần và tránh đường cho nó?"
Điều này không làm cho kết luận của Foundax trở thành universal. Doanh nghiệp khác, model khác, tool surfaces khác sẽ đi đến những câu trả lời khác. Điều universal là phương pháp: test trước, thiết kế sau.
Q: Điều này có nghĩa là tôi nên luôn expose tất cả tools cho model không?
Không. Nó phụ thuộc vào số lượng tools của bạn, model của bạn, context budget của bạn, và domain của bạn. Ý chính không phải là "luôn expose mọi thứ." Ý chính là: test trước khi filter. Đừng giả định model không xử lý được — hãy kiểm chứng. Trong trường hợp của chúng tôi, khoảng hơn chục compressed tool signatures mỗi task là khả thi và hiệu quả. Con số của bạn có thể khác.
Q: Khi nào tôi nên dùng fixed workflows thay thế?
Khi task thực sự deterministic, rủi ro sai sót là thảm khốc, và kiến thức nền của model trong domain đó yếu. Workflows không sai — chúng sai khi thay thế reasoning mà model có thể tự làm. Dùng chúng cho safety guardrails và deterministic post-processing, không phải để thay thế model judgment.
Q: Sự khác biệt giữa linguistic catalog và API schema là gì?
Linguistic catalog nói cho model biết tool có thể làm gì, bằng natural language nén — ví dụ: "Read: [12] Product Variants — SKU / giá / tồn kho / trạng thái khả dụng." API schema nói cho model cách gọi tool, với đầy đủ parameter specs, enums, và constraints. Model cần capabilities menu. Runtime cần technical manual. Trộn lẫn hai thứ này là một trong những sai lầm đắt giá nhất bạn có thể mắc phải.
Q: Làm sao để quyết định cái gì cho model vs. runtime?
Một heuristic tốt: model xử lý understanding, judgment, selection, và explanation. Runtime xử lý permission, execution, confirmation, validation, và readback. Nếu bạn đang yêu cầu model enforce rules, bạn đang ở sai phía của ranh giới. Model đề xuất; runtime quyết định và thực thi.
Q: Còn về chi phí thì sao? Expose nhiều tools hơn không làm tăng token usage à?
Trong trường hợp của chúng tôi, compressed linguistic catalog thực sự rẻ hơn so với multi-round directory exploration hoặc retrieval chains. Mỗi mục tool khoảng hơn một nghìn ký tự. Với khoảng hơn chục tools được expose mỗi task, tổng khoảng mười đến hai mươi nghìn ký tự — khoảng bốn đến năm nghìn tokens. So sánh với nhiều vòng intent decomposition, retrieval, candidate review, và re-selection. Cách đơn giản hơn thường hiệu quả hơn về token, không phải kém hơn.
Q: Insight quan trọng nhất từ quá trình này là gì?
Đó là "giúp model" và "constrain model" có thể trông giống hệt nhau từ góc nhìn của người thiết kế, nhưng có tác động trái ngược lên hệ thống. Mọi kiến trúc chúng tôi xây dựng đều có ý định giúp đỡ. Hầu hết kết thúc bằng việc constrain. Sự khác biệt chỉ trở nên rõ ràng qua testing. Nếu bạn lấy một điều từ bài viết này, hãy để nó là điều này: test xem model của bạn thực sự làm được gì trước khi bắt đầu thiết kế kiến trúc để bù đắp cho những gì bạn giả định nó không làm được.