Siti DTC vs marketplace nell’agentic commerce
Guida pratica per usare i marketplace mentre si costruisce un canale DTC con dati prodotto, relazione cliente, contenuti e misurazione.
Leggi di più
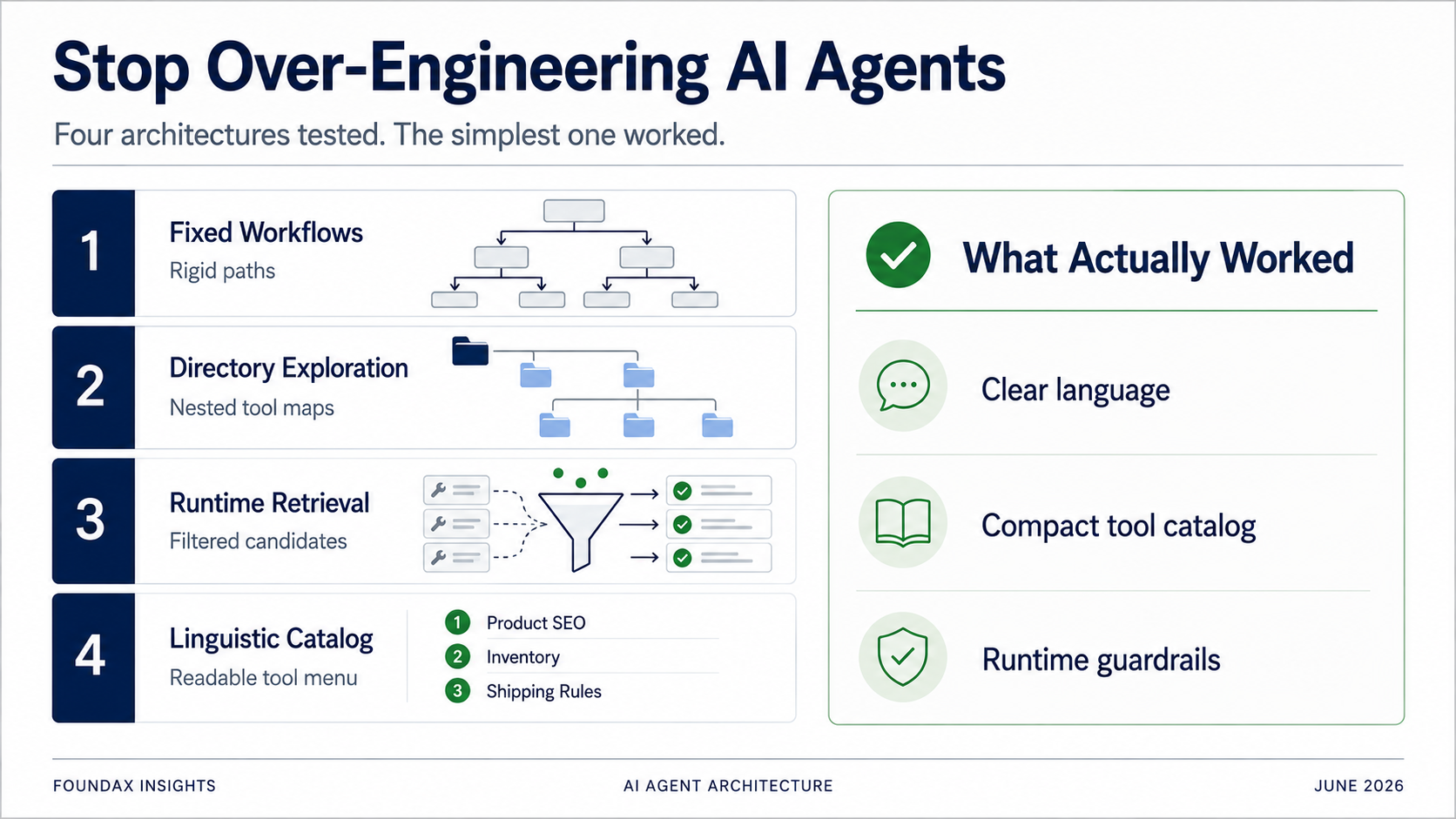
Quattro architetture Agent, dai workflow fissi a un catalogo linguistico essenziale. Ogni «ottimizzazione» eravamo noi a fare il lavoro del modello al posto suo. L'architettura vincente è stata quella che ha smesso di provare a essere più furba del modello.
C'è un momento assurdo nella costruzione del Foundax Agent a cui continuo a tornare.
Abbiamo provato un sacco di architetture. Workflow fissi. Esplorazione degli strumenti per directory. Raccomandazione di strumenti basata su skill. Runtime retrieval. Matching con regex. Piani strutturati. Cicli ReAct multi-round. A un certo punto abbiamo persino considerato seriamente il retrieval basato su embedding.
Ogni versione aveva senso sulla carta.
Troppi strumenti, quindi dobbiamo filtrare. Il modello si perde dei pezzi, quindi dobbiamo vincolare. Il contesto è troppo lungo, quindi dobbiamo retrieven. L'esecuzione deve essere sicura, quindi dobbiamo proceduralizzare. La precisione di business richiede strumenti atomici di basso livello.
Presi singolarmente, nessuno di questi giudizi era sbagliato.
Poi abbiamo fatto il test più semplice — quasi brutale: comprimere tutti gli strumenti in un catalogo linguistico leggero, buttarlo al modello e lasciare che leggesse e scegliesse da solo.
Il risultato è stato sorprendentemente buono.
Sono rimasto letteralmente senza parole.
Perché significava che la maggior parte dei nostri design complessi non stava sbloccando le capacità del modello. Stava assumendo che il modello avrebbe fallito, per poi avvolgerlo in strati di architettura per compensare.
Questo articolo non sta dicendo che «esporre tutti gli strumenti sia la best practice».
Quello che voglio davvero dire è questo: il più grande pericolo nel costruire un Agent di business non è che il modello non sia abbastanza intelligente — è che tu inizi a progettargli una gabbia prima ancora di aver testato cosa può fare nel tuo dominio.
Foundax è una piattaforma SaaS per l'ecommerce.
Quindi il Foundax Agent non ha a che fare con chiacchiere o domande di cultura generale. Affronta i veri problemi operativi che i merchant incontrano nel loro backend.
I merchant non dicono:
«Per favore, chiama l'API di lettura delle varianti prodotto.»
Dicono:
«Perché questo prodotto non vende?»
«La mia pagina in spagnolo è già pronta?»
«Questo prodotto può andare su Google Shopping?»
«Perché la gente aggiunge al carrello ma non paga?»
«Completa il SEO che mi manca.»
Queste domande sembrano linguaggio naturale, ma dietro ognuna c'è un intero sistema di business. Prodotti, SKU, inventario, prezzi, SEO, traduzioni, promozioni, spedizioni, pagamenti, checkout, ordini, rimborsi, feed GMC, stato di visualizzazione in vetrina — ognuno di questi può influenzare il risultato.
Quindi l'obiettivo del Foundax Agent non è «sembrare umano».
Quello che deve davvero fare è: capire l'intenzione reale del merchant, trovare i fatti corrispondenti nel sistema, selezionare gli strumenti giusti, preparare scritture quando necessario ed eseguire sotto i vincoli del runtime — con permessi, conferma e readback al loro posto.
L'input dell'utente può essere sfocato. L'esecuzione del sistema deve essere precisa.
Questa tensione è il punto di partenza di ogni dilemma architetturale che segue.
Ho una vena da perfezionista dell'ingegneria.
Così, quando ho iniziato a progettare il Foundax Agent, ho istintivamente rifiutato gli strumenti a grana grossa.
Uno strumento chiamato analyzeProductReadiness suona comodo. Ma quali campi sta leggendo internamente? Quali criteri sta applicando? Dove sono i confini dei permessi? Si può fare readback dopo una scrittura? Tutto diventa opaco.
Foundax non è una demo. Quando un merchant ti chiede di sistemare la SEO, non puoi avere uno strumento a scatola nera che modifica cose in silenzio sullo sfondo.
Così ho insistito su strumenti atomici di basso livello:
Leggere i campi base del prodotto. Leggere le varianti prodotto. Leggere inventario e prezzi. Leggere la SEO del prodotto. Leggere le traduzioni del prodotto. Leggere la configurazione di spedizione. Leggere la configurazione di pagamento. Scrivere un campo specifico. Scrivere contenuti per una locale specifica. Generare una bozza di modifica. Readback dopo scrittura.
Ogni strumento a funzione unica, pulito, non sovrapposto. Esecuzione precisa, permessi chiari, facile da testare.
Continuo a pensare che questo giudizio fosse giusto.
Il vero problema era un altro: più i tuoi strumenti di basso livello sono atomici, più strumenti hai. Più strumenti hai, più è difficile per il modello capirli e selezionarli nel contesto.
Questo è stato il primo paradosso.
Più uno strumento di basso livello si adatta all'esecuzione di sistema, meno si adatta all'interfaccia cognitiva del modello.
L'atomicità non era l'errore. L'errore era scaricare un mucchio di strumenti atomici direttamente davanti al modello aspettandosi che scegliesse coerentemente quelli giusti.
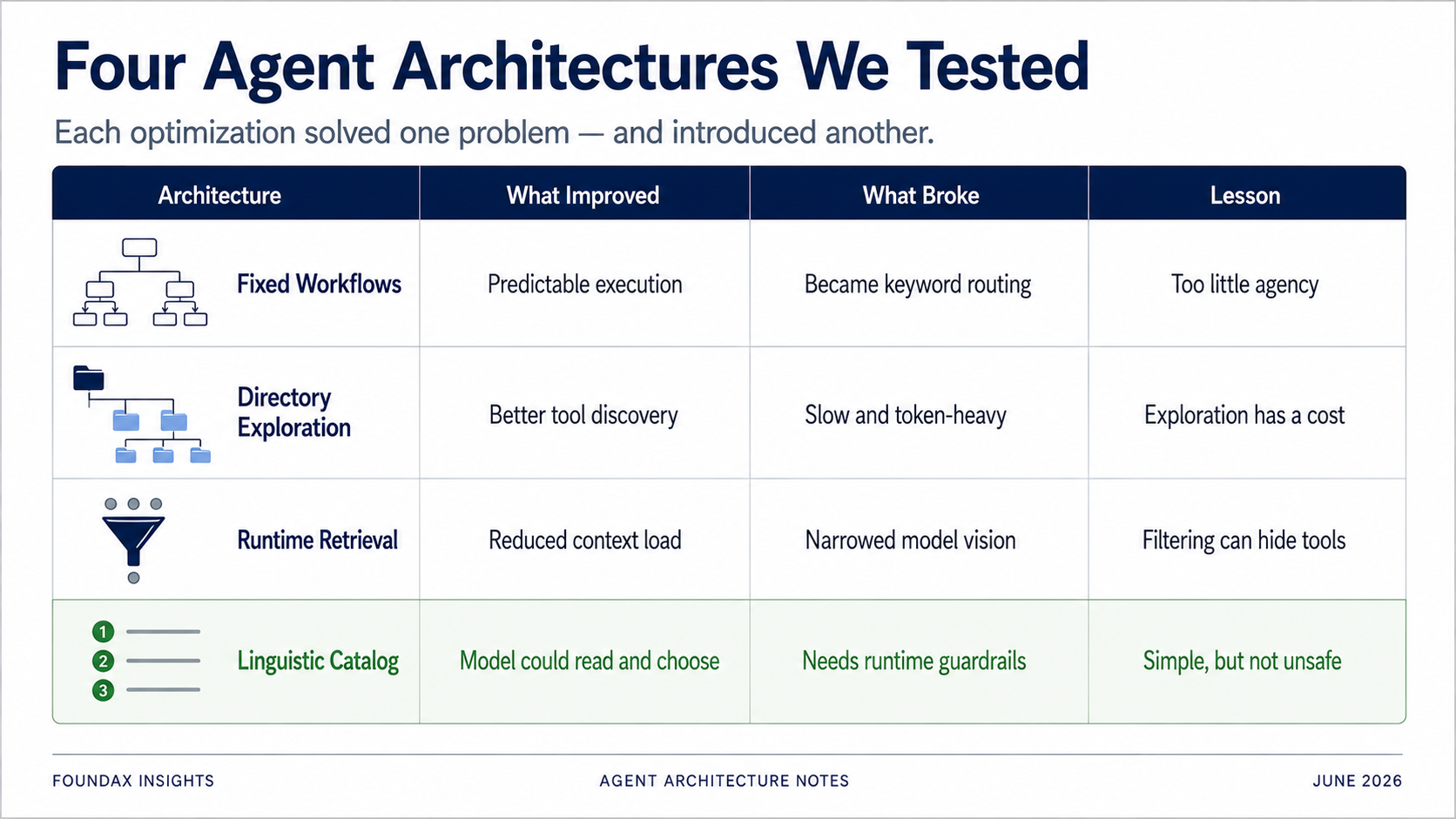
Per risolvere il problema della selezione degli strumenti, il nostro primo tentativo sono stati i workflow fissi.
Un istinto naturale. Se i task ad alta frequenza dei merchant sono finiti, pre-scritturali.
Controllo SEO prodotto. Controllo copertura traduzioni. Controllo prontezza lancio prodotto. Diagnosi bassa conversione. Controllo prontezza GMC.
Il compito del modello: identificare l'intento dell'utente, mapparlo a un workflow e passare la mano al runtime per l'esecuzione fissa.
Sembrava sicuro. Sembrava ben ingegnerizzato.
Ma nei test, è degenerato rapidamente in uno stupido sistema a parole chiave.
L'espressione degli utenti è troppo varia. Uno dice «la mia SEO è completa?» Un altro dice «Google può indicizzare questa pagina?» Un altro dice «ho sbagliato il titolo del prodotto?» Un altro dice «perché il mio feed continua a dare errore quando metto gli annunci?»
Per far sì che ogni variante intercetti un task, continui ad aggiungere parole chiave, alias, regole. Alla fine il sistema non è preciso ed è più difficile da mantenere che mai.
Ancora più importante: il modello non aveva quasi spazio per operare. Era solo un classificatore di intenti. Il vero percorso di analisi, la selezione degli strumenti, la sequenza di raccolta delle prove — tutto predeterminato da noi.
È lì che mi è arrivata la rivelazione:
Se ogni task è pre-scritto in un workflow, la cosa non è più un Agent — è uno strumento di workflow travestito da AI.
I workflow fissi, al cuore, sostituiscono il ragionamento del modello con l'enumerazione umana del business. Rendono il sistema più controllabile, ma spogliano l'Agent della sua Agency.
Allora abbiamo cambiato rotta.
Invece di scaricare tutti gli strumenti in una volta, organizzarli in una directory. Il modello sceglie prima un dominio di business, poi espande le sottodirectory, poi seleziona strumenti specifici.
Prodotti. Ordini. Pagamenti. Spedizioni. Promozioni. Analytics. GMC.
Sotto «Prodotti»: informazioni di base, SKU, inventario, prezzi, SEO, traduzioni.
Questo era molto più preciso dei workflow fissi. Il modello non stava abbinando parole chiave a percorsi predefiniti — stava esplorando una mappa strutturata di strumenti. Trovava davvero gli strumenti giusti più spesso.
Ma il problema era ovvio: velocità.
Ogni task richiedeva l'attraversamento della directory. Anche le domande semplici passavano attraverso l'intera catena di esplorazione. Consumo di token alto. Latenza alta.
Un merchant chiede «la SEO di questo prodotto è completa?» e l'Agent si comporta come se stesse sfogliando un grosso manuale tecnico.
L'esplorazione per directory non era sbagliata come direzione. Il problema è che trasformava «capire il sistema di strumenti» in un costo per ogni invocazione. Il modello doveva ri-esplorare il sistema da zero ogni singola volta, cosa difficile da accettare come esperienza di prodotto.
Poi abbiamo costruito qualcosa di più sofisticato.
Il modello produce prima una comprensione strutturata del prompt utente: scomposizione dell'intento, parole chiave, domini di business coinvolti e se il task è read, write, mixed o unknown.
Poi questo piano va al runtime. Il runtime usa skill, matching con regex e metadati degli strumenti per retrieven gli strumenti candidati. Il modello seleziona tra i candidati. Dopo aver letto i fatti, il modello può decidere se continuare a esplorare in un altro round.
Questa versione sembrava un Agent Runtime maturo. E ha portato dei veri progressi.
Per esempio, abbiamo scoperto che i campi strutturati possono migliorare il comportamento del modello. Per evitare che il modello afferrasse il primo strumento che sembrava rilevante senza leggere l'intera lista dei candidati, abbiamo progettato un campo come hasreadalltools — chiedendo al modello di dichiarare esplicitamente se aveva finito di leggere tutti i candidati prima di fare un tool call. Questo ha davvero aiutato.
Ma la cosa più interessante è stata che dopo abbiamo scoperto che una singola istruzione in linguaggio naturale, ben scritta, poteva essere più efficace di un campo strutturato complesso.
Prima che il modello selezionasse gli strumenti, abbiamo aggiunto:
«In base all'obiettivo di business dell'utente, seleziona tutti gli strumenti di analisi e scrittura necessari. Non limitarti a prendere il primo strumento che sembra rilevante.»
Prima che il modello si preparasse a dare una risposta, abbiamo aggiunto:
«Non avere fretta di rispondere. Prima determina se i fatti necessari sono completi. Se non lo sono, continua a selezionare strumenti.»
Questi semplici prompt hanno migliorato significativamente la profondità di ragionamento del modello.
Questo è stato un campanello d'allarme importante:
Un LLM non è un programma tradizionale. I protocolli strutturati sono utili, ma il modello legge sempre linguaggio e imita il ragionamento. Il più delle volte, un'istruzione in linguaggio naturale precisa, diretta e a bassa ambiguità funziona meglio di un campo strutturato complesso.
Ma questa architettura ha anche esposto un problema più profondo.
Il runtime tool retrieval era stato progettato per risolvere il sovraccarico di contesto e la selezione imprecisa degli strumenti. Ma un runtime è, fondamentalmente, un sistema di regole.
Che si tratti di regex, skill, parole chiave o filtraggio per dominio — può filtrare via strumenti di cui il modello ha realmente bisogno, già al primo passaggio.
Pensa a un merchant che chiede: «Perché questo prodotto non vende?»
Questa domanda potrebbe riguardare l'analytics. Potrebbe anche riguardare il contenuto del prodotto, i prezzi, l'inventario, le promozioni, la spedizione, il pagamento, il checkout, le fonti di traffico, la geografia, il dispositivo, la SEO, l'autenticità della copy della pagina.
Se il runtime la incasella troppo frettolosamente in un singolo dominio, il campo visivo del modello viene ristretto.
Questo è il terzo paradosso:
Il runtime tool retrieval risparmia contesto — ma può anche diventare il soffitto del campo visivo del modello.
Volevamo ridurre il carico del modello e abbiamo finito per potenzialmente restringere il suo giudizio.
Man mano che il numero di strumenti cresceva, ho seriamente considerato il retrieval basato su embedding.
L'idea è naturale. Prompt utente → vettore. Descrizioni degli strumenti → vettori. Punteggio di similarità. Top-k al modello.
Sembra standard. Sembra «AI-native».
Ma più ci pensavo, più mi sembrava sbagliato.
Per il retrieval pubblicitario, la raccomandazione di contenuti o la ricerca massiva di documenti, gli embedding hanno senso. L'insieme dei candidati è enorme e i sistemi tradizionali davvero non capiscono il linguaggio. Devi comprimere la semantica in vettori per un matching approssimativo.
Ma gli strumenti di Foundax non sono milioni di documenti sconosciuti in un mondo aperto. Sono capacità di business finite, enumerabili, descrivibili, comprimibili all'interno del nostro stesso sistema.
E la più grande forza dell'LLM è proprio leggere il linguaggio, capire il linguaggio, confrontare la semantica e giudicare l'intento.
Quindi perché convertire le descrizioni degli strumenti in vettori per poi usare un punteggio di similarità per decidere — al posto del modello — cosa può vedere?
È come avere un libro con un indice perfettamente leggibile. Invece di leggerlo, codifichi l'indice in numeri e fai giudicare al lettore quale capitolo leggere in base alla distanza numerica.
Questo ha senso nei sistemi di ricerca tradizionali. In un Agent nativo LLM, credo sempre più che sia una deviazione.
Per un Agent di business come Foundax, la priorità non è il retrieval vettoriale. È la compressione linguistica — comprimere strumenti, documenti, capacità e confini in un contesto linguistico chiaro, preciso e ad alta densità che il modello possa leggere direttamente.
Abbiamo anche incontrato un altro problema classico: l'esposizione degli strumenti era troppo pesante.
All'inizio, ogni strumento esponeva informazioni molto complete al modello: nome della funzione, descrizione lunga, ambito dei fatti, confine della risposta, fonti escluse, enumerazioni di campi, enumerazioni del livello di dettaglio, descrizioni degli argomenti, formato di ritorno dell'osservazione.
Sembra rigoroso.
Ma alla fine ho capito: il modello non ha bisogno di sapere la maggior parte di queste cose.
Se l'esecuzione effettiva della query, la validazione dei campi, la verifica dei permessi, i confini owner-executor, i flussi di conferma e il readback sono tutti gestiti dal runtime, allora il modello non ha alcun motivo di leggere lo schema API completo ogni volta.
Quello che il modello ha realmente bisogno di sapere:
Per esempio:
Questo basta.
I prefissi «Read / Write / Search» nella lista dei candidati sono già sufficienti perché il modello distingua i tipi di azione. I veri permessi di lettura/scrittura, i flussi di conferma, i confini owner-executor — quelli devono rimanere dentro il runtime, applicati all'esecuzione. Non bruciare token facendoli leggere al modello. E soprattutto, non fare affidamento sul modello perché li rispetti volontariamente.
La conclusione qui:
Lo schema è per il runtime, non per il modello. Il modello dovrebbe vedere un catalogo di capacità linguistiche, non un dizionario di API.
Alla fine abbiamo fatto il test più semplice.
Esporre tutti gli strumenti al modello come descrizioni linguistiche estremamente compresse. Lasciare che il modello legga. Lasciare che il modello scelga.
Il risultato è stato sorprendentemente buono.
Onestamente, questo risultato è stato un piccolo schiaffo. Perché ogni architettura complessa che avevamo costruito prima era ancorata a un presupposto: il modello non può gestire di vedere troppi strumenti, quindi il runtime deve filtrare per lui.
Ma il test ha mostrato che questo presupposto — almeno nel contesto attuale di Foundax — non regge completamente.
La domanda non è «si possono esporre tutti gli strumenti?» La domanda è «cosa stai esattamente esponendo al modello?»
Se stai esponendo un muro di schemi API completi — descrizioni lunghe, enumerazioni di campi, specifiche di parametri — annegherai sicuramente il modello. Ma se stai esponendo un catalogo di capacità linguistiche leggero e chiaro, il modello può leggere e scegliere da solo — e potrebbe persino fare un lavoro migliore del pre-filtraggio del runtime.
Non è un ritorno all'esposizione grezza dell'inizio.
L'inizio era: scaricare il dizionario API completo sul modello.
La fine era: consegnare al modello un manuale operativo compresso — un menu di capacità linguistiche leggero, numerato.
Sono cose completamente diverse. Il primo è un oceano di strumenti. Il secondo è una mappa leggibile.
Siamo concreti. Il nostro sistema ha decine di strumenti di lettura e comandi di scrittura — oltre un centinaio di strumenti canonici in totale. Ogni task espone al massimo una dozzina di strumenti al modello, controllato da un budget di esposizione. La fase di toolselection ha un budget di contesto di decine di migliaia di caratteri. La descrizione dello schema di ogni strumento è di circa un migliaio di caratteri (qualche centinaio di token). Esporre una dozzina di strumenti significa circa dieci-ventimila caratteri — circa quattro-cinquemila token. Molto gestibile.
Ma se esponessimo tutti gli strumenti con i loro schemi completi? Sarebbero quasi duecentomila caratteri — circa cinquantamila token. Questo davvero non ci starebbe.
L'insight chiave: il runtime fornisce firme di strumenti compatte e numerate dal registro canonico. Il modello legge una scheda, non una voce di enciclopedia.
Sarebbe facile fraintendere questo punto.
«Lasciare che il modello legga e scelga» significa che il runtime non è importante?
Tutto il contrario.
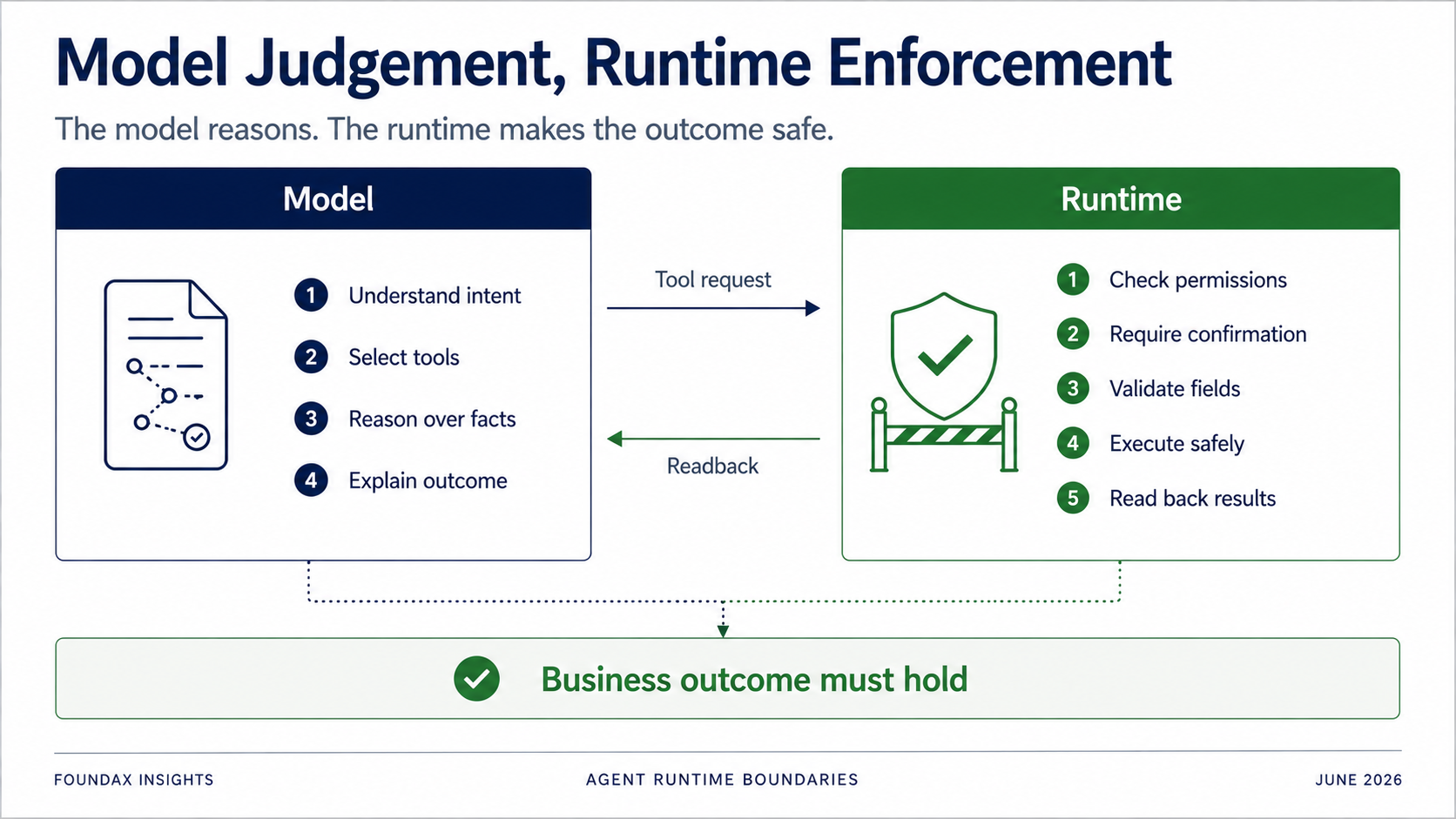
Il runtime rimane critico — semplicemente non deve cercare di pensare al posto del modello prematuramente.
Il modello è responsabile di capire, giudicare, selezionare e spiegare.
Il runtime è responsabile di permessi, conferma, validazione dei campi, confini owner-executor, esecuzione effettiva e readback.
Specialmente per le operazioni di scrittura: non puoi assolutamente fare affidamento sul modello perché segua volontariamente le regole.
Il modello può dire «voglio aggiornare la SEO di questo prodotto».
Ma il runtime deve determinare: l'utente corrente ha il permesso? Questa azione richiede conferma? Dovrebbe prima generare solo una bozza? Il campo è nella allowlist? L'oggetto appartiene al merchant corrente? La scrittura è effettivamente riuscita? Dopo il readback, lo stato di business corrisponde davvero all'obiettivo?
L'obiettivo dell'Agent non è dimostrare che un tool call è riuscito. È dimostrare che il risultato di business regge.
Questo confine è essenziale. Non tutto va al modello e non tutto va al runtime. La vera questione è la divisione del lavoro.
L'insegnamento principale di questo viaggio non è che la 4.0 sia definitivamente l'architettura migliore.
È che costruire un Agent rende pericolosamente facile farsi trascinare da una catena di preoccupazioni ingegneristiche reali.
Preoccupato che i task ad alta frequenza non siano stabili quando il modello improvvisa ogni volta? → Costruisci workflow fissi.
Preoccupato che il contesto sia troppo lungo e il modello soffra di diluizione dell'attenzione? → Costruisci esplorazione per directory.
Preoccupato che la crescita del numero di strumenti faccia esplodere i token? → Costruisci runtime retrieval.
Preoccupato che il retrieval basato su parole chiave sia troppo fragile per task multilingue e cross-dominio? → Considera embedding, scoring, reranking.
Preoccupato che il modello scelga strumenti senza leggere la lista completa o produca risposte prima che i fatti siano completi? → Aggiungi campi strutturati di vincolo.
Nessuna di queste preoccupazioni è immaginaria. Corrispondono tutte a problemi reali.
Abbiamo solo constatato — a caro prezzo — che molte soluzioni risolvevano un problema mentre ne introducevano un altro.
I workflow fissi aggiungevano stabilità ma limitavano il ragionamento del modello. L'esplorazione per directory era precisa ma lenta e costosa in token. Il runtime retrieval risparmiava contesto ma poteva bloccare strumenti di cui il modello aveva bisogno. Gli embedding sembravano intelligenti ma, per la selezione di strumenti nativa LLM, erano probabilmente una deviazione. I campi strutturati potevano vincolare il modello, ma a volte un semplice prompt in linguaggio naturale funzionava meglio.
E la consapevolezza più critica:
Questi problemi sono reali, ma non sono necessariamente ugualmente gravi nel tuo progetto.
Il contesto lungo causa davvero diluizione dell'attenzione nel tuo caso d'uso? Testalo. Il tuo numero di strumenti rende davvero i costi dei token inaccettabili? Testalo. L'esposizione completa degli strumenti rende davvero il tuo modello pigro, dipendente dal percorso o incline all'errore? Testalo. Il runtime retrieval blocca davvero strumenti di cui il tuo modello ha bisogno? Testa anche questo.
L'errore più facile nell'architettura Agent è trattare «problemi che esistono realmente nel progetto di qualcun altro» come «problemi che esistono sicuramente nel tuo».
Quindi il primo passo per costruire un Agent non è progettare un'architettura complessa per prevenire ogni possibile problema. Il primo passo è testare:
Cosa può effettivamente capire il modello nel tuo dominio? Può leggere le descrizioni dei tuoi strumenti? Può selezionare strumenti da solo? Dove si perde i fatti? Quali decisioni puoi delegargli? Quali deve imporre il runtime? Quali azioni richiedono la conferma dell'utente? Quali risultati devono essere verificati con readback?
Le risposte a queste domande — non un'architettura di riferimento da un blog post — devono determinare il design del tuo Agent.
Per Foundax, ora abbiamo chiarezza: le operazioni ecommerce sono un dominio che il modello conosce bene. Imbuti di conversione, pagine prodotto, prezzi, spedizioni, promozioni, pagamenti, qualità del traffico, SEO — questi framework analitici appaiono innumerevoli volte nei dati di addestramento. Al modello non manca l'istinto di analisi di business. Quello che gli manca è la conoscenza del sistema specifico di Foundax: quali fatti può leggere, quali scritture può preparare, quali azioni il runtime deve possedere, quali risultati devono essere verificati con readback.
Quindi il Foundax Agent non consiste nell'insegnare al modello come fare analisi ecommerce. Consiste nel consegnare al modello le capacità di business di Foundax in un linguaggio che possa leggere.
Il primo passo per costruire un Agent di business non è progettare un'architettura perfetta. È testare fino a che punto puoi davvero fidarti del modello.
Non siamo gli unici ad arrivare a queste conclusioni.
A dicembre 2024, Anthropic ha pubblicato la sua guida "Building Effective Agents". Il suo messaggio centrale: la semplicità vince. Inizia con la soluzione più semplice possibile. Un LLM aumentato con accesso agli strumenti può essere tutto ciò di cui hai bisogno. Quando lo lessi all'epoca, annuii. Dopo aver vissuto ciò che ho descritto sopra, lo capisco visceralmente.
Poi, a maggio 2026, LangChain ha tenuto la sua conferenza Interrupt con un pivot notevole: il tema è passato da «gli agenti possono andare in produzione?» a «scala enterprise e operazioni di produzione». Il vero collo di bottiglia, come hanno sottolineato i loro materiali, non è scrivere agenti — è gestirli in produzione su larga scala.
Un crescente corpo di ricerca rafforza questa direzione. Il lavoro di Google DeepMind del 2025 sulle limitazioni degli embedding ha mostrato matematicamente che gli embedding vettoriali a dimensione fissa perdono informazioni strutturali e relazionali su scala — direttamente rilevante per chiunque stia considerando il retrieval di strumenti basato su embedding. Il concetto di Neo4j di "context engineering" sostiene che un'AI affidabile viene dall'architettura, non da formulazioni astute dei prompt.
La nostra esperienza si allinea con una direzione che vediamo in tutto il settore: i pattern semplici/componibili di Anthropic, l'enfasi di LangChain sulle operazioni di produzione rispetto alle astrazioni dei framework. Meno scaffolding prefabbricato, più capacità diretta del modello — ma sempre validato contro l'uso reale, non adottato come dottrina. Meno pre-filtraggio, più giudizio del modello. La domanda non è «come costruiamo un'architettura perfetta attorno al modello?» È «come diamo al modello ciò di cui ha realmente bisogno e ci togliamo di mezzo?»
Questo non rende universali le conclusioni di Foundax. Business diversi, modelli diversi, superfici di strumenti diverse arriveranno a risposte diverse. Ciò che è universale è il metodo: testare prima, progettare dopo.
D: Questo significa che dovrei sempre esporre tutti gli strumenti al modello?
No. Dipende dal tuo numero di strumenti, dal tuo modello, dal tuo budget di contesto e dal tuo dominio. Il punto non è «esponi sempre tutto». Il punto è: testa prima di filtrare. Non dare per scontato che il modello non possa gestirlo — verificalo. Nel nostro caso, circa una dozzina di firme di strumenti compresse per task era gestibile ed efficace. I tuoi numeri potrebbero essere diversi.
D: Quando dovrei usare invece i workflow fissi?
Quando il task è genuinamente deterministico, il rischio di errore è catastrofico e la conoscenza di background del modello in quel dominio è debole. I workflow non sono sbagliati — sono sbagliati quando sostituiscono il ragionamento che il modello avrebbe potuto fare. Usali per barriere di sicurezza e post-elaborazione deterministica, non come sostituto del giudizio del modello.
D: Qual è la differenza tra un catalogo linguistico e uno schema API?
Un catalogo linguistico dice al modello cosa può fare uno strumento, in linguaggio naturale compresso — ad esempio «Read: [12] Product Variants — SKU / prezzo / inventario / stato di disponibilità». Uno schema API dice al modello come chiamare lo strumento, con specifiche complete di parametri, enumerazioni e vincoli. Il modello ha bisogno del menu delle capacità. Il runtime ha bisogno del manuale tecnico. Mescolare queste due cose è uno degli errori più costosi che puoi fare.
D: Come decido cosa va al modello e cosa al runtime?
Una buona euristica: il modello gestisce comprensione, giudizio, selezione e spiegazione. Il runtime gestisce permessi, esecuzione, conferma, validazione e readback. Se stai chiedendo al modello di far rispettare le regole, sei dalla parte sbagliata della linea. Il modello suggerisce; il runtime decide ed esegue.
D: E i costi? Esporre più strumenti non aumenta il consumo di token?
Nel nostro caso, un catalogo linguistico compresso era in realtà più economico dell'esplorazione per directory multi-round o delle catene di retrieval. Ogni voce di strumento occupa circa un migliaio di caratteri. Con una dozzina di strumenti esposti per task, il totale è di circa dieci-ventimila caratteri — circa quattro-cinquemila token. Confrontalo con più round di scomposizione dell'intento, retrieval, revisione dei candidati e ri-selezione. L'approccio più semplice era spesso più efficiente in token, non meno.
D: Qual è stata l'intuizione più importante di questo processo?
Che «aiutare il modello» e «vincolare il modello» possono sembrare identici dalla prospettiva del progettista, ma hanno effetti opposti sul sistema. Ogni architettura che abbiamo costruito doveva aiutare. La maggior parte ha finito per vincolare. La differenza è diventata chiara solo attraverso i test. Se porti via una sola cosa da questo articolo, che sia questa: testa ciò che il tuo modello può effettivamente fare prima di iniziare a progettare architettura per compensare ciò che presumi non possa fare.