Situs DTC vs marketplace di agentic commerce
Panduan praktis memakai marketplace sambil membangun kanal DTC dengan data produk, relasi pelanggan, konten, dan pengukuran.
Baca selengkapnya
Empat arsitektur Agent, dari fixed workflows sampai katalog bahasa ringan. Setiap 'optimasi' sebenarnya adalah kami mengerjakan tugas model untuknya. Arsitektur yang menang adalah yang berhenti mencoba menjadi pintar.
Ada satu momen absurd dari proses membangun Foundax Agent yang terus saya ingat.
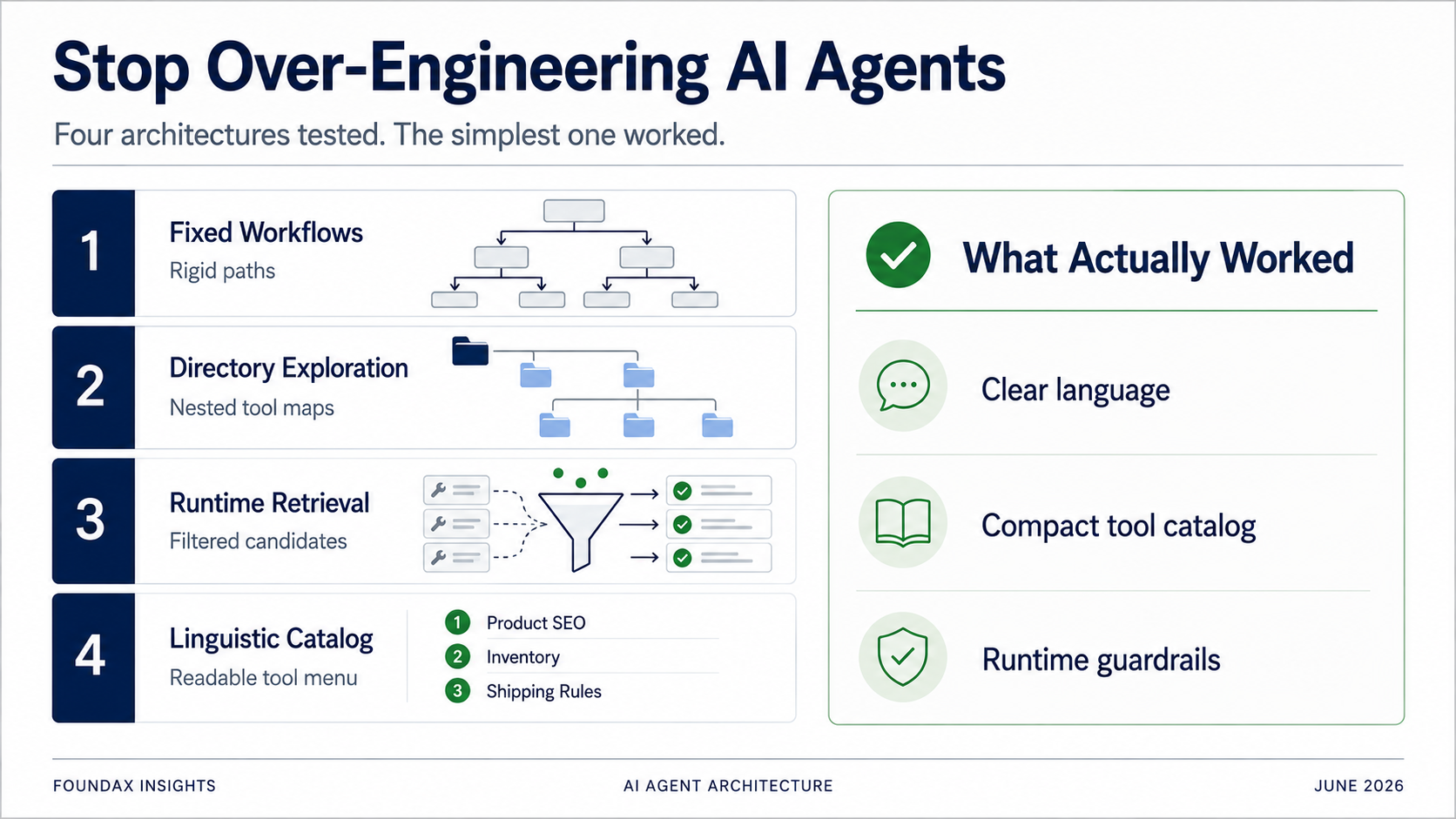
Kami mencoba banyak arsitektur. Fixed workflows. Directory-based tool exploration. Skill-based tool recommendation. Runtime retrieval. Regex matching. Structured plans. Multi-round ReAct loops. Pada satu titik, kami bahkan serius mempertimbangkan embedding-based retrieval.
Setiap versi masuk akal di atas kertas.
Terlalu banyak tools, jadi kita perlu filter. Model melewatkan sesuatu, jadi kita perlu constrain. Context terlalu panjang, jadi kita perlu retrieve. Eksekusi harus aman, jadi kita perlu proceduralize. Bisnis butuh presisi, bottom-layer tools harus atomic.
Dilihat satu per satu, tidak ada penilaian ini yang salah.
Tapi kemudian kami menjalankan tes paling sederhana — hampir kasar: kompres semua tools menjadi katalog bahasa yang ringan, lemparkan ke model, dan biarkan model membaca dan memilih sendiri.
Hasilnya mengejutkan.
Saya benar-benar terdiam.
Karena itu berarti sebagian besar desain kompleks kami tidak membuka kemampuan model. Mereka hanya mengasumsikan model akan gagal, lalu membungkusnya dengan lapisan arsitektur untuk mengompensasi.
Artikel ini bukan bilang "expose semua tools adalah best practice."
Yang benar-benar ingin saya katakan adalah: bahaya terbesar dalam membangun business Agent bukanlah model yang kurang pintar — melainkan Anda mulai mendesain sangkar untuknya sebelum Anda menguji apa yang bisa dilakukannya di domain Anda.
Foundax adalah platform ecommerce SaaS.
Jadi Foundax Agent tidak berurusan dengan chat santai atau Q&A pengetahuan umum. Ia berurusan dengan masalah operasional nyata yang dihadapi merchant di backend mereka.
Merchant tidak bilang:
"Tolong panggil product variant read API."
Mereka bilang:
"Kenapa produk ini gak laku?"
"Halaman bahasa Spanyol saya sudah jadi belum?"
"Produk ini bisa jalan di Google Shopping gak?"
"Kenapa banyak yang masukin keranjang tapi gak bayar?"
"Lengkapi SEO saya yang kurang."
Pertanyaan-pertanyaan ini terdengar seperti natural language, tapi di balik setiap pertanyaan ada seluruh sistem bisnis. Produk, SKU, inventori, harga, SEO, terjemahan, promosi, pengiriman, pembayaran, checkout, pesanan, refund, GMC feed, status tampilan storefront — salah satu dari ini bisa memengaruhi hasil.
Jadi tujuan Foundax Agent bukanlah "terdengar seperti manusia."
Yang benar-benar perlu dilakukan adalah: memahami maksud asli merchant, menemukan fakta yang sesuai di sistem, memilih tools yang tepat, menyiapkan write saat diperlukan, dan mengeksekusi di bawah batasan runtime — dengan permissions, confirmation, dan readback.
Input pengguna boleh kabur. Tapi eksekusi sistem harus presisi.
Ketegangan itulah titik awal dari setiap dilema arsitektur setelahnya.
Saya orang yang perfeksionis dalam engineering.
Jadi saat mulai mendesain Foundax Agent, secara naluri saya menolak tools yang terlalu kasar.
Tool bernama analyzeProductReadiness terdengar praktis. Tapi field apa yang dibacanya secara internal? Kriteria apa yang diterapkan? Di mana batas permission-nya? Setelah write, bisa readback gak? Semua jadi buram.
Foundax bukan demo. Saat merchant minta Anda perbaiki SEO, Anda gak bisa pakai tool black-box yang diam-diam mengubah banyak hal.
Jadi saya bersikeras pada atomic bottom-layer tools:
Baca product base fields. Baca product variants. Baca inventori dan harga. Baca product SEO. Baca product translations. Baca shipping configuration. Baca payment configuration. Write field tertentu. Write konten untuk locale tertentu. Generate modification draft. Readback setelah write.
Setiap tool satu tujuan, bersih, tidak tumpang tindih. Eksekusi presisi, permissions jelas, mudah dites.
Saya masih merasa penilaian ini benar.
Masalah sebenarnya adalah hal lain: semakin atomic bottom-layer tools Anda, semakin banyak tools yang Anda punya. Semakin banyak tools, semakin sulit model memahami dan memilihnya dalam context.
Itulah paradoks pertama.
Semakin cocok sebuah bottom-layer tool untuk eksekusi sistem, semakin tidak cocok ia sebagai cognitive interface model.
Atomicity bukan kesalahannya. Kesalahannya adalah menumpuk setumpuk atomic tools langsung di depan model dan berharap model konsisten memilih yang benar.
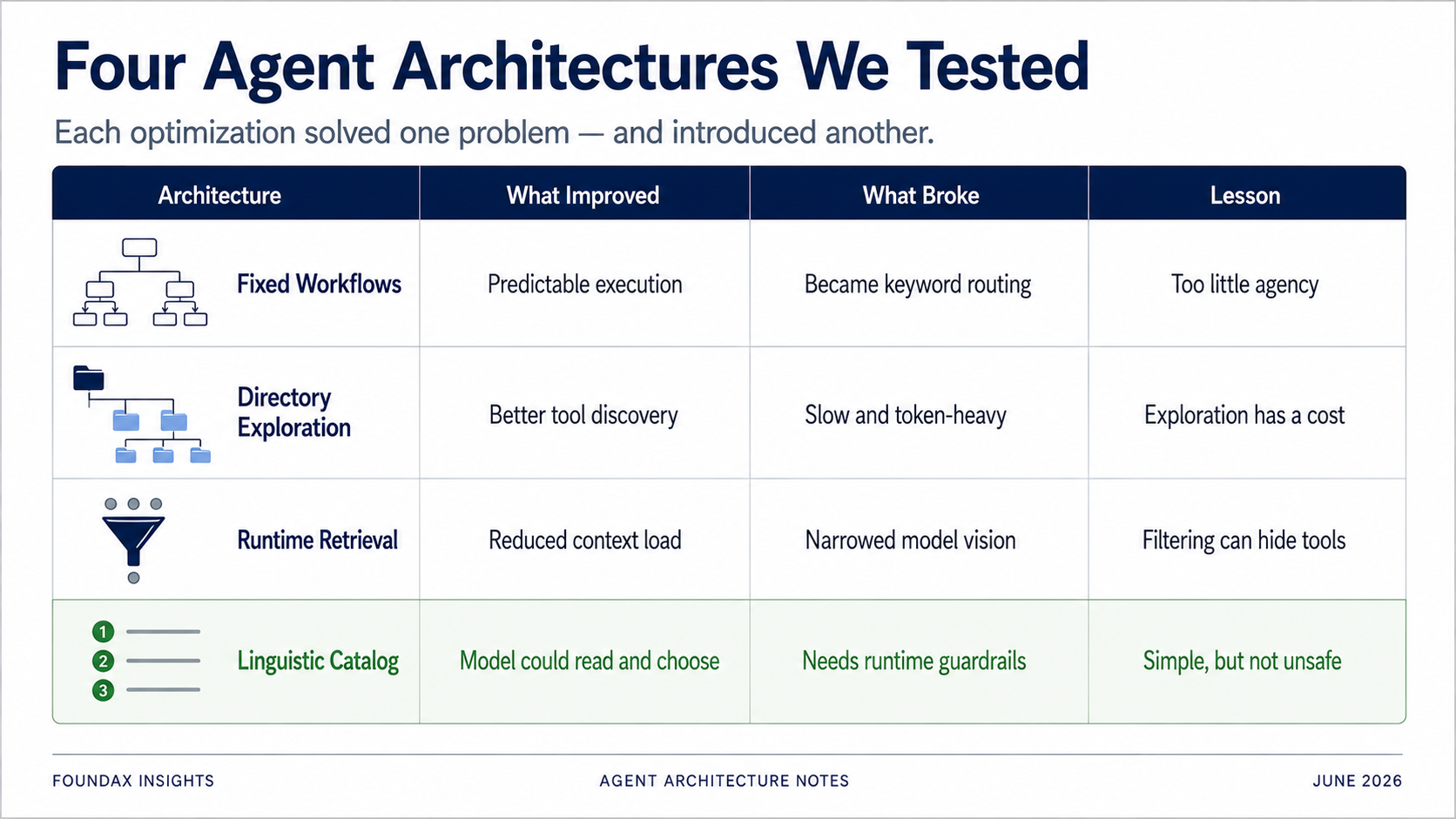
Untuk menyelesaikan masalah pemilihan tool, upaya pertama kami adalah fixed workflows.
Ini naluri yang wajar. Kalau task frekuensi tinggi merchant terbatas, script saja dari awal.
Product SEO check. Translation coverage check. Product launch launch check. Low conversion diagnosis. GMC preflight check.
Tugas model adalah mengidentifikasi intent pengguna, memetakan ke workflow, lalu menyerahkan ke runtime untuk eksekusi tetap.
Solusi ini terlihat aman. Terlihat engineered.
Tapi dalam pengujian, ia cepat merosot menjadi sistem keyword yang bodoh.
Ekspresi pengguna terlalu beragam. Satu orang bilang "SEO saya sudah lengkap?" Yang lain bilang "apa Google bisa index halaman ini?" Yang lain bilang "judul produk saya salah ya?" Yang lain bilang "kenapa feed saya error terus pas jalanin iklan?"
Untuk membuat setiap variasi mengenai sebuah task, Anda terus menambahkan keywords, aliases, rules. Akhirnya sistem tidak akurat, dan lebih sulit di-maintain dari sebelumnya.
Lebih penting lagi, model hampir tidak punya ruang untuk beroperasi. Ia hanya intent classifier. Jalur analisis sebenarnya, pemilihan tool, urutan pengumpulan bukti — semuanya sudah ditentukan sebelumnya oleh kami.
Saat itulah saya tersadar:
Kalau setiap task sudah di-script ke dalam workflow, benda itu bukan Agent lagi — ia workflow tool yang pakai kostum AI.
Fixed workflows, pada intinya, menggantikan reasoning model dengan enumerasi bisnis manusia. Mereka membuat sistem lebih terkontrol, tapi mencabut Agency dari Agent.
Berikutnya, kami berputar arah.
Alih-alih menuangkan semua tools sekaligus, kami mengorganisirnya ke dalam directory. Model memilih business domain dulu, lalu memperluas subdirectory, lalu memilih tool spesifik.
Produk. Pesanan. Pembayaran. Pengiriman. Promosi. Analytics. GMC.
Di bawah "Produk": info dasar, SKU, inventori, harga, SEO, terjemahan.
Ini jauh lebih akurat daripada fixed workflows. Model tidak mencocokkan keywords ke jalur yang sudah ditentukan — ia menjelajahi peta tool terstruktur. Ia benar-benar menemukan tools yang tepat lebih sering.
Tapi masalahnya jelas: kecepatan.
Setiap task butuh directory traversal. Pertanyaan sederhana pun tetap melalui exploration chain. Konsumsi token tinggi. Latency tinggi.
Merchant tanya "SEO produk ini sudah lengkap?" dan Agent bertingkah seperti sedang membuka-buka manual backend yang tebal.
Directory exploration tidak salah arah. Masalahnya adalah ia mengubah "memahami sistem tool" menjadi biaya per invocation. Model harus menjelajahi ulang sistem dari nol setiap kali, yang sulit diterima sebagai pengalaman produk.
Berikutnya, kami membangun sesuatu yang lebih canggih.
Model pertama-tama menghasilkan pemahaman terstruktur dari prompt pengguna: intent decomposition, keywords, business domain yang terlibat, dan apakah task bersifat read, write, mixed, atau unknown.
Lalu plan ini pergi ke runtime. Runtime menggunakan skills, regex matching, dan tool metadata untuk me-retrieve candidate tools. Model memilih dari kandidat. Setelah membaca fakta, model bisa memutuskan apakah akan melanjutkan eksplorasi di ronde lain.
Versi ini terlihat seperti Agent Runtime yang matang. Dan memang menghasilkan beberapa kemajuan nyata.
Misalnya, kami menemukan bahwa structured fields bisa memperbaiki perilaku model. Untuk mencegah model langsung mengambil tool pertama yang terlihat relevan tanpa membaca seluruh candidate list, kami mendesain field hasreadalltools — meminta model secara eksplisit menyatakan sudah selesai membaca semua kandidat sebelum melakukan tool call. Itu benar-benar membantu.
Tapi yang lebih menarik: belakangan kami menemukan bahwa satu instruksi natural language yang ditulis dengan baik bisa lebih efektif daripada structured field yang kompleks.
Sebelum model memilih tools, kami menambahkan:
"Berdasarkan tujuan bisnis pengguna, pilih semua analysis dan write tools yang diperlukan. Jangan hanya ambil tool pertama yang terlihat relevan."
Sebelum model bersiap memberikan jawaban, kami menambahkan:
"Jangan buru-buru menjawab. Pertama-tama tentukan apakah fakta yang dibutuhkan sudah lengkap. Kalau belum, lanjutkan memilih tools."
Prompt sederhana ini secara signifikan meningkatkan kedalaman reasoning model.
Ini adalah peringatan besar:
LLM bukan program tradisional. Structured protocols berguna, tapi model selalu membaca bahasa dan meniru reasoning. Seringkali, satu instruksi natural language yang presisi, langsung, dan rendah ambiguitas bekerja lebih baik daripada structured field yang kompleks.
Tapi arsitektur ini juga mengekspos masalah yang lebih dalam.
Runtime tool retrieval dirancang untuk mengatasi context overload dan pemilihan tool yang tidak akurat. Tapi runtime, pada dasarnya, adalah sistem rule.
Entah itu regex, skills, keywords, atau domain filtering — ia bisa memfilter tools yang benar-benar dibutuhkan model, di putaran pertama.
Bayangkan merchant bertanya: "Kenapa produk ini gak laku?"
Pertanyaan itu mungkin melibatkan analytics. Mungkin juga melibatkan konten produk, harga, inventori, promosi, pengiriman, pembayaran, checkout, sumber traffic, geografi, perangkat, SEO, keaslian copy halaman.
Kalau runtime terlalu cepat memasukkannya ke satu domain, bidang pandang model dibatasi.
Itulah paradoks ketiga:
Runtime tool retrieval menghemat context — tapi ia juga bisa menjadi langit-langit bidang pandang model.
Kami bermaksud mengurangi beban model, dan akhirnya berpotensi membatasi penilaian model.
Saat jumlah tools bertambah, saya serius mempertimbangkan embedding-based retrieval.
Idenya alami. User prompt → vector. Tool descriptions → vectors. Similarity score. Top-k ke model.
Terdengar standar. Terdengar "AI-native."
Tapi semakin saya pikirkan, semakin terasa salah.
Untuk ad retrieval, content recommendation, atau pencarian dokumen masif, embeddings masuk akal. Kumpulan kandidat sangat besar, dan sistem tradisional benar-benar tidak bisa memahami bahasa. Anda perlu mengompres semantik menjadi vectors untuk approximate matching.
Tapi tools Foundax bukan jutaan dokumen tak dikenal di dunia terbuka. Mereka adalah business capabilities yang terbatas, bisa dihitung, bisa dideskripsikan, bisa dikompres dalam sistem kami sendiri.
Dan kekuatan terbesar LLM justru membaca bahasa, memahami bahasa, membandingkan semantik, dan menilai maksud.
Jadi kenapa mengonversi deskripsi tool menjadi vectors, lalu menggunakan similarity score untuk memutuskan — atas nama model — apa yang boleh dilihatnya?
Ini seperti punya buku dengan daftar isi yang bisa dibaca dengan jelas. Alih-alih membacanya, Anda encode daftar isi menjadi angka dan memaksa pembaca menebak bab mana yang harus dibaca berdasarkan jarak numerik.
Itu masuk akal di sistem pencarian tradisional. Di Agent LLM-native, saya semakin yakin itu adalah jalan buntu.
Untuk business Agent seperti Foundax, prioritasnya bukan vector retrieval. Melainkan language compression — mengompres tools, dokumen, kapabilitas, dan batasan menjadi konteks linguistik yang jelas, akurat, dan padat yang bisa dibaca model secara langsung.
Kami juga menemui masalah klasik lain: tool exposure terlalu berat.
Awalnya, setiap tool mengekspos informasi yang sangat lengkap ke model: function name, long description, fact scope, answer boundary, excluded sources, field enums, detail level enums, argument descriptions, observation return format.
Terlihat rigorous.
Tapi akhirnya saya sadar: model tidak perlu tahu sebagian besar ini.
Kalau query execution, field validation, permission checking, owner executor boundaries, confirmation flows, dan readback yang sebenarnya semuanya ditangani oleh runtime, maka model tidak punya urusan membaca full API schema setiap kali.
Yang benar-benar perlu diketahui model:
Contohnya:
Itu sudah cukup.
Prefix "Read / Write / Search" di candidate list sudah cukup bagi model untuk membedakan jenis tindakan. Permission read/write sebenarnya, confirmation flows, owner executor boundaries — semua itu harus tetap di dalam runtime, ditegakkan saat eksekusi. Jangan bakar token untuk membuat model membacanya. Dan sama sekali jangan mengandalkan model untuk patuh secara sukarela.
Kesimpulannya di sini:
Schema untuk runtime, bukan untuk model. Model seharusnya melihat linguistic capability catalog, bukan API dictionary.
Akhirnya, kami menjalankan tes paling sederhana.
Ekspos semua tools ke model sebagai deskripsi bahasa yang sangat terkompres. Biarkan model membaca. Biarkan model memilih.
Hasilnya mengejutkan.
Jujur, hasil ini seperti tamparan. Karena setiap arsitektur kompleks yang kami bangun sebelumnya berlabuh pada satu asumsi: model tidak bisa menangani melihat terlalu banyak tools, jadi runtime harus memfilter untuknya.
Tapi tes menunjukkan bahwa asumsi itu — setidaknya dalam konteks Foundax saat ini — tidak sepenuhnya benar.
Pertanyaannya bukan "apakah semua tools bisa diekspos?" Pertanyaannya adalah "apa sebenarnya yang Anda ekspos ke model?"
Kalau Anda mengekspos dinding API schema lengkap — long descriptions, field enums, parameter specs — Anda pasti akan menenggelamkan model. Tapi kalau Anda mengekspos linguistic capability catalog yang ringan, jelas, model bisa membaca dan memilih sendiri — dan mungkin melakukannya lebih baik daripada pre-filtering runtime.
Ini bukan kembali ke ekspos kasar di awal.
Awal adalah: menuangkan API dictionary penuh ke model.
Akhir adalah: memberikan model compressed operations manual — menu kapabilitas linguistik yang ringan, bernomor.
Dua hal ini benar-benar berbeda. Yang pertama adalah lautan tools. Yang kedua adalah peta yang bisa dibaca.
Biar saya konkret. Sistem kami punya puluhan read tools dan write commands — total lebih dari seratus canonical tools. Setiap task mengekspos paling banyak sekitar selusin tools ke model, dikendalikan oleh exposure budget. Fase toolselection punya context budget puluhan ribu karakter. Deskripsi schema setiap tool sekitar seribu sekian karakter (beberapa ratus token). Mengekspos selusin tools berarti sekitar sepuluh hingga dua puluh ribu karakter — sekitar empat sampai lima ribu token. Sangat mudah dikelola.
Tapi kalau kami mengekspos semua tools dengan full schema? Itu hampir dua ratus ribu karakter — sekitar lima puluh ribu token. Benar-benar tidak muat.
Key insight: runtime menyediakan compact, numbered tool signatures dari canonical registry. Model membaca index card, bukan entri ensiklopedia.
Akan mudah salah paham soal ini.
Apakah "biarkan model membaca dan memilih" berarti runtime tidak penting?
Justru sebaliknya.
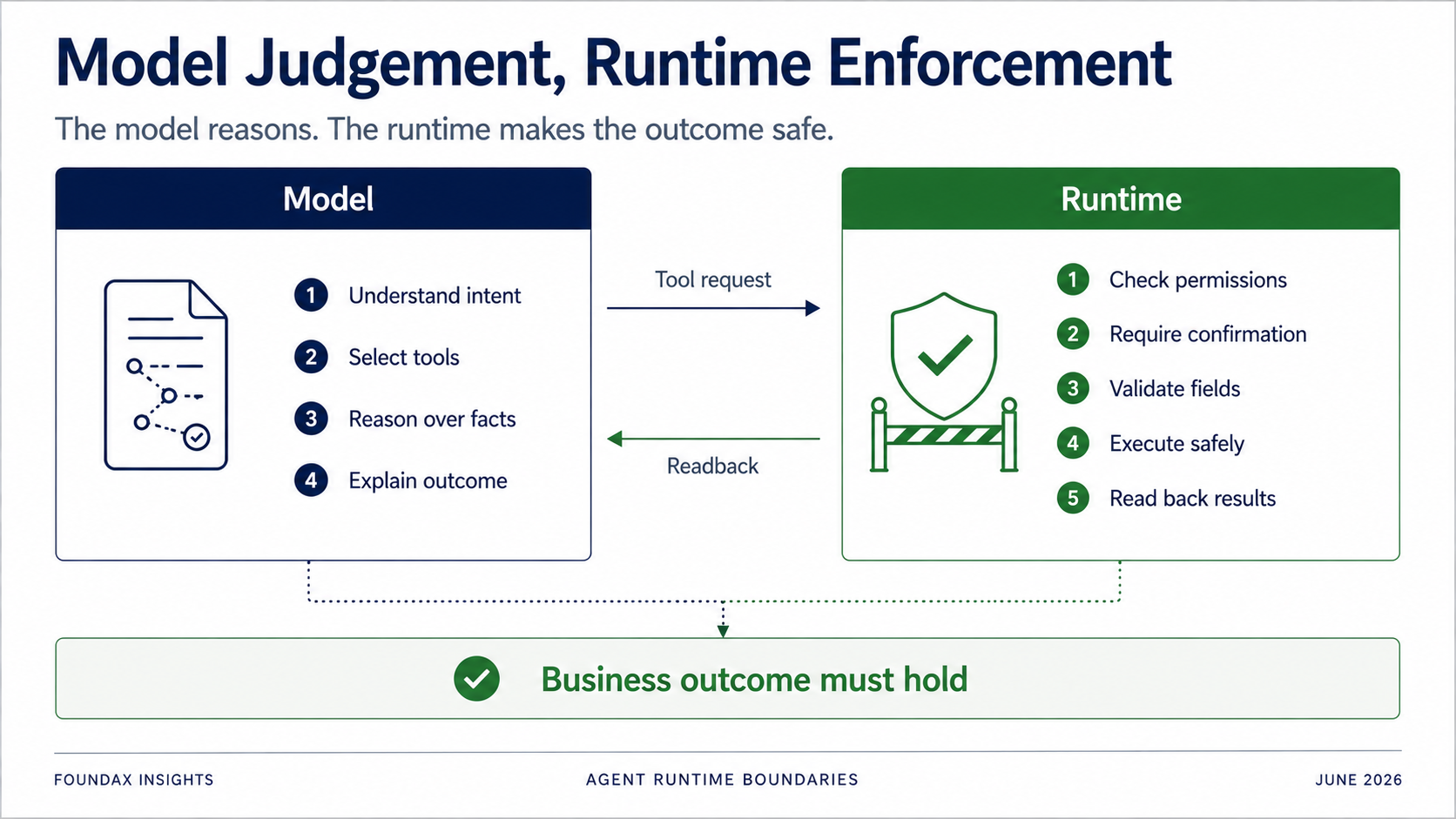
Runtime tetap kritis — ia hanya tidak boleh mencoba berpikir untuk model terlalu dini.
Model bertanggung jawab atas: understanding, judgment, selection, dan explanation.
Runtime bertanggung jawab atas: permissions, confirmation, field validation, owner executor boundaries, eksekusi aktual, dan readback.
Khususnya untuk write operations: Anda sama sekali tidak boleh mengandalkan model untuk patuh pada aturan secara sukarela.
Model bisa bilang "saya ingin update SEO produk ini."
Tapi runtime harus menentukan: Apakah pengguna saat ini punya permission? Apakah tindakan ini butuh confirmation? Haruskah hanya generate draft dulu? Apakah field ada di allowlist? Apakah objek milik merchant saat ini? Apakah write benar-benar berhasil? Setelah readback, apakah business state benar-benar sesuai target?
Tujuan Agent bukan membuktikan tool call berhasil. Tapi membuktikan business outcome tercapai.
Batasan ini esensial. Tidak semua hal ke model, dan tidak semua hal ke runtime. Pertanyaan sebenarnya adalah pembagian kerja.
Pelajaran terbesar dari perjalanan ini bukan bahwa 4.0 adalah arsitektur terbaik.
Tapi bahwa membangun Agent membuat Anda sangat mudah terbawa oleh rantai kekhawatiran engineering yang nyata.
Khawatir task frekuensi tinggi tidak stabil saat model improvise setiap kali? → Bangun fixed workflows.
Khawatir context terlalu panjang dan model mengalami attention dilution? → Bangun directory exploration.
Khawatir pertumbuhan jumlah tools membuat token meledak? → Bangun runtime retrieval.
Khawatir keyword-based retrieval terlalu rapuh untuk tugas multi-bahasa dan cross-domain? → Pertimbangkan embeddings, scoring, reranking.
Khawatir model memilih tools tanpa membaca seluruh list, atau memberikan jawaban sebelum fakta lengkap? → Tambahkan structured constraint fields.
Kekhawatiran ini bukan khayalan. Semuanya sesuai dengan masalah nyata.
Kami hanya menemukan — dengan cara yang sulit — bahwa banyak solusi menyelesaikan satu masalah sambil menciptakan masalah lain.
Fixed workflows menambah stabilitas tapi membatasi reasoning model. Directory exploration akurat tapi lambat dan boros token. Runtime retrieval menghemat context tapi bisa memblokir tools yang dibutuhkan model. Embeddings terlihat pintar tapi untuk LLM-native tool selection, mungkin jalan buntu. Structured fields bisa meng-constrain model, tapi kadang prompt natural language bekerja lebih baik.
Dan kesadaran yang lebih kritis:
Masalah-masalah ini nyata, tapi belum tentu sama parahnya di proyek Anda.
Apakah context panjang benar-benar menyebabkan attention dilution di use case Anda? Tes. Apakah jumlah tools benar-benar membuat biaya token tidak bisa diterima? Tes. Apakah full tool exposure benar-benar membuat model malas, tergantung jalur, atau rawan error? Tes. Apakah runtime retrieval benar-benar memblokir tools yang dibutuhkan model? Tes juga.
Kesalahan termudah dalam Agent architecture adalah memperlakukan "masalah yang benar-benar ada di proyek orang lain" sebagai "masalah yang pasti ada di proyek Anda."
Jadi langkah pertama membangun Agent bukanlah mendesain arsitektur kompleks untuk mengantisipasi setiap kemungkinan masalah. Melainkan mengetes:
Apa yang benar-benar bisa dipahami model di domain Anda? Bisakah ia membaca deskripsi tool Anda? Bisakah ia memilih tools sendiri? Di mana ia melewatkan fakta? Keputusan mana yang bisa Anda serahkan padanya? Mana yang harus ditegakkan runtime? Tindakan mana yang butuh konfirmasi pengguna? Hasil mana yang harus di-readback?
Jawaban atas pertanyaan-pertanyaan ini — bukan reference architecture dari blog post — yang seharusnya menentukan desain Agent Anda.
Untuk Foundax, sekarang kami punya kejelasan: operasi ecommerce adalah domain yang dikenal baik oleh model. Conversion funnels, product pages, pricing, shipping, promotions, payment, traffic quality, SEO — kerangka analitis ini muncul berkali-kali dalam training data. Model tidak kekurangan insting analisis bisnis. Yang tidak dimilikinya adalah pengetahuan tentang sistem spesifik Foundax: fakta apa yang bisa dibacanya, write apa yang bisa disiapkannya, tindakan mana yang harus dimiliki runtime, hasil mana yang harus di-readback.
Jadi Foundax Agent bukan tentang mengajari model cara menganalisis ecommerce. Melainkan tentang memberikan business capabilities Foundax kepada model dalam bahasa yang bisa dibacanya.
Langkah pertama membangun business Agent bukan mendesain arsitektur yang sempurna. Melainkan mengetes seberapa besar Anda benar-benar bisa memercayai model.
Kami bukan satu-satunya yang sampai pada kesimpulan ini.
Pada Desember 2024, Anthropic menerbitkan panduan "Building Effective Agents". Pesan intinya: kesederhanaan yang menang. Mulailah dengan solusi paling sederhana. Sebuah augmented LLM dengan akses tool mungkin sudah cukup. Saat membacanya waktu itu, saya mengangguk. Setelah menjalani semua yang saya deskripsikan di atas, saya memahaminya secara mendalam.
Lalu pada Mei 2026, LangChain mengadakan konferensi Interrupt dengan pivot yang mencolok: tema bergeser dari 'bisakah agents naik production' menjadi 'enterprise scale dan production operations.' Bottleneck sebenarnya, seperti yang ditekankan materi mereka, bukan menulis agents — tapi mengelolanya di production dalam skala besar.
Semakin banyak riset yang memperkuat arah ini. Karya Google DeepMind tahun 2025 tentang keterbatasan embedding menunjukkan secara matematis bahwa fixed-size vector embeddings kehilangan informasi struktural dan relasional pada skala besar — relevan langsung bagi siapa pun yang mempertimbangkan embedding-based tool retrieval. Konsep "context engineering" dari Neo4j berargumen bahwa AI yang andal datang dari architecture, bukan clever prompt phrasing.
Pengalaman kami selaras dengan arah yang kami lihat di seluruh industri: simple/composable patterns dari Anthropic, penekanan LangChain pada production operations dibanding framework abstractions. Lebih sedikit scaffolding siap pakai, lebih banyak kemampuan model langsung — tapi selalu divalidasi dengan penggunaan nyata, bukan diadopsi sebagai doktrin. Lebih sedikit pre-filtering, lebih banyak model judgment. Pertanyaannya bukan "bagaimana kita membangun arsitektur sempurna di sekitar model?" Tapi "bagaimana kita memberi model apa yang benar-benar dibutuhkannya dan menyingkir dari jalannya?"
Ini tidak membuat kesimpulan Foundax bersifat universal. Bisnis berbeda, model berbeda, tool surfaces berbeda akan sampai pada jawaban berbeda. Yang universal adalah metodenya: tes dulu, desain kemudian.
Q: Apakah ini berarti saya harus selalu mengekspos semua tools ke model?
Tidak. Tergantung jumlah tools Anda, model Anda, context budget Anda, dan domain Anda. Intinya bukan "selalu ekspos semuanya." Intinya: tes sebelum memfilter. Jangan berasumsi model tidak bisa menanganinya — verifikasi. Dalam kasus kami, sekitar selusin compressed tool signatures per task bisa dikelola dan efektif. Angka Anda mungkin berbeda.
Q: Kapan saya sebaiknya menggunakan fixed workflows?
Saat task benar-benar deterministik, risiko kesalahan sangat besar, dan pengetahuan latar model di domain itu lemah. Workflows tidak salah — mereka salah saat menggantikan reasoning yang sebenarnya bisa dilakukan model. Gunakan untuk safety guardrails dan deterministic post-processing, bukan sebagai pengganti model judgment.
Q: Apa bedanya linguistic catalog dan API schema?
Linguistic catalog memberi tahu model apa yang bisa dilakukan sebuah tool, dalam natural language yang terkompres — misalnya: "Read: [12] Product Variants — SKU / harga / inventori / status ketersediaan." API schema memberi tahu model cara memanggil tool, dengan parameter specs, enums, dan constraints lengkap. Model butuh capabilities menu. Runtime butuh technical manual. Mencampur keduanya adalah salah satu kesalahan termahal yang bisa Anda buat.
Q: Bagaimana cara memutuskan apa yang ke model vs. runtime?
Heuristik yang baik: model menangani understanding, judgment, selection, dan explanation. Runtime menangani permission, execution, confirmation, validation, dan readback. Kalau Anda meminta model untuk enforce rules, Anda ada di sisi yang salah. Model menyarankan; runtime memutuskan dan mengeksekusi.
Q: Bagaimana dengan biaya? Bukankah mengekspos lebih banyak tools meningkatkan token usage?
Dalam kasus kami, compressed linguistic catalog justru lebih murah dibandingkan multi-round directory exploration atau retrieval chains. Setiap entri tool sekitar seribu sekian karakter. Dengan sekitar selusin tools diekspos per task, total sekitar sepuluh hingga dua puluh ribu karakter — sekitar empat sampai lima ribu token. Bandingkan dengan beberapa ronde intent decomposition, retrieval, candidate review, dan re-selection. Pendekatan yang lebih sederhana seringkali lebih efisien token, bukan sebaliknya.
Q: Apa insight paling penting dari proses ini?
Bahwa "membantu model" dan "meng-constrain model" bisa terlihat identik dari sudut pandang desainer, tapi punya efek berlawanan pada sistem. Setiap arsitektur yang kami bangun dimaksudkan untuk membantu. Sebagian besar akhirnya meng-constrain. Perbedaannya hanya menjadi jelas melalui testing. Kalau Anda mengambil satu hal dari artikel ini, biarlah ini: tes apa yang benar-benar bisa dilakukan model Anda sebelum mulai mendesain arsitektur untuk mengompensasi apa yang Anda asumsikan tidak bisa dilakukannya.