Sitios DTC vs marketplaces en agentic commerce
Guía práctica para usar marketplaces mientras se construye un canal DTC con datos de producto, relación con clientes, contenido y medición.
Leer más
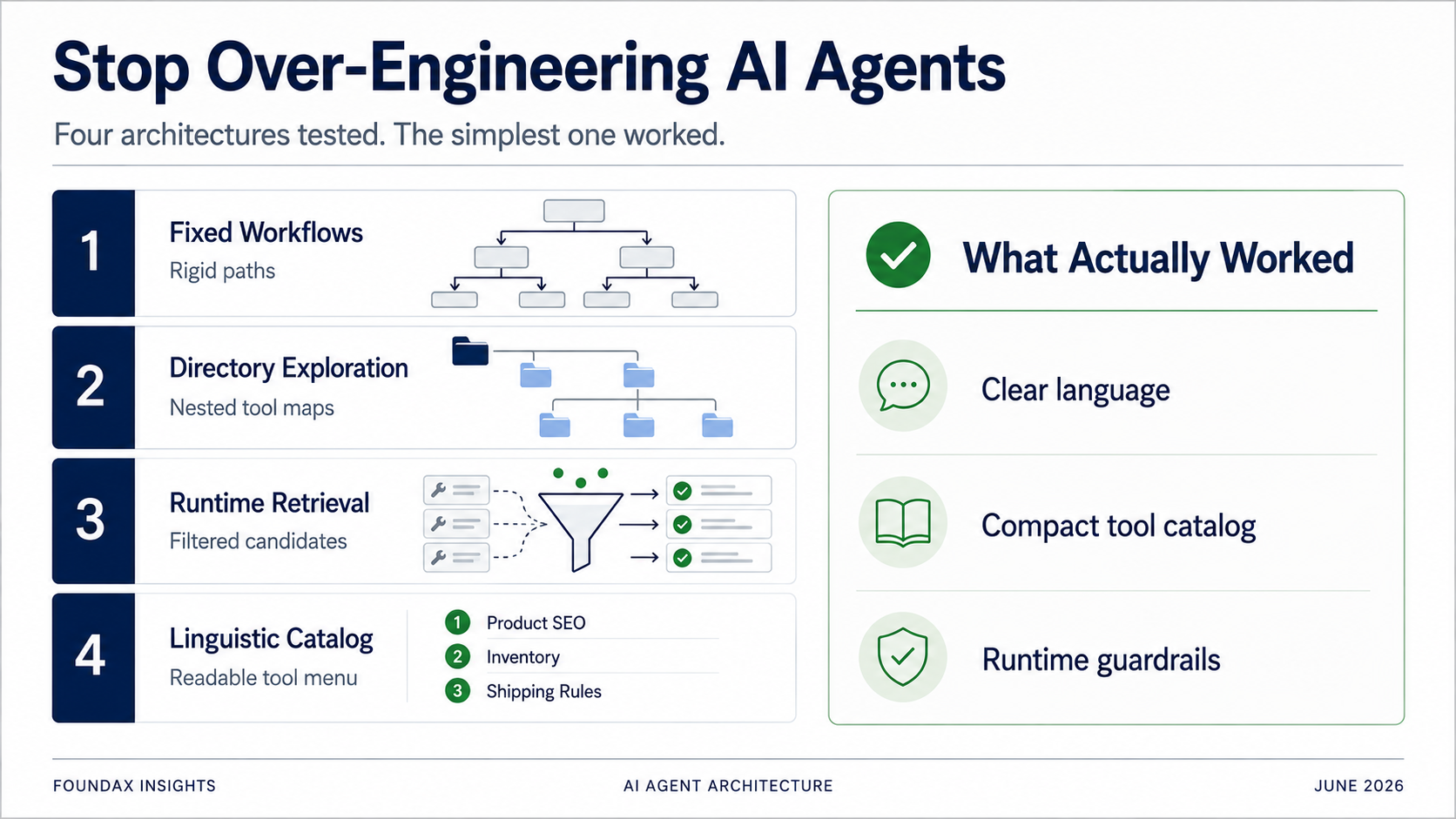
Cuatro arquitecturas Agent: de workflows fijos a un catálogo lingüístico ligero. Cada «optimización» era en realidad nosotros haciendo el trabajo del modelo por él. La arquitectura ganadora fue la que dejó de intentar ser más lista que el modelo.
Hay un momento absurdo de cuando construíamos el Foundax Agent al que vuelvo una y otra vez.
Probamos un montón de arquitecturas. Workflows fijos. Exploración de herramientas por directorio. Recomendación de herramientas basada en skills. Runtime retrieval. Matching por regex. Planes estructurados. Bucles ReAct de múltiples rondas. En un momento, hasta consideramos seriamente retrieval basado en embeddings.
Cada versión tenía sentido sobre el papel.
Demasiadas herramientas: hay que filtrar. El modelo se salta cosas: hay que restringir. El contexto es muy largo: hay que retrieven. La ejecución debe ser segura: hay que procedimentalizar. La precisión de negocio exige herramientas atómicas de capa inferior.
Por separado, ninguna de estas decisiones era incorrecta.
Pero entonces hicimos la prueba más simple — casi burda: comprimir todas las herramientas en un catálogo lingüístico ligero, lanzárselo al modelo y dejar que leyera y eligiera por sí mismo.
El resultado fue sorprendentemente bueno.
Me quedé sin palabras, de verdad.
Porque significaba que la mayoría de nuestros diseños complejos no estaban desbloqueando las capacidades del modelo. Estaban asumiendo que el modelo iba a fallar, y luego envolviéndolo en capas de arquitectura para compensarlo.
Este artículo no dice que «exponer todas las herramientas sea la mejor práctica».
Lo que realmente quiero decir es esto: el mayor peligro al construir un Agent de negocio no es que el modelo no sea suficientemente inteligente — es que empieces a diseñarle una jaula antes siquiera de haber probado lo que puede hacer en tu dominio.
Foundax es una plataforma SaaS de ecommerce.
Así que el Foundax Agent no lidia con charla casual ni preguntas de conocimiento general. Enfrenta los problemas operativos reales que los comerciantes encuentran en su backend.
Los comerciantes no dicen:
«Por favor, llama a la API de lectura de variantes de producto.»
Dicen:
«¿Por qué no se vende este producto?»
«¿Ya está lista mi página en español?»
«¿Este producto puede funcionar en Google Shopping?»
«¿Por qué la gente añade al carrito pero no paga?»
«Completa el SEO que me falta.»
Estas preguntas suenan a lenguaje natural, pero detrás de cada una hay un sistema de negocio completo. Productos, SKUs, inventario, precios, SEO, traducciones, promociones, envíos, pagos, checkout, pedidos, reembolsos, feeds de GMC, estado de visualización en la tienda — cualquiera de estos puede afectar el resultado.
Así que el objetivo del Foundax Agent no es «sonar humano».
Lo que realmente necesita hacer es: entender la intención real del comerciante, encontrar los hechos correspondientes en el sistema, seleccionar las herramientas correctas, preparar escrituras cuando sea necesario y ejecutar bajo las restricciones del runtime — con permisos, confirmación y readback en su lugar.
La entrada del usuario puede ser difusa. La ejecución del sistema debe ser precisa.
Esa tensión es el punto de partida de cada dilema arquitectónico que sigue.
Tengo vena de perfeccionista de la ingeniería.
Así que cuando empecé a diseñar el Foundax Agent, rechacé instintivamente las herramientas de grano grueso.
Una herramienta llamada analyzeProductReadiness suena práctica. ¿Pero qué campos está leyendo internamente? ¿Qué criterios está aplicando? ¿Dónde están los límites de permisos? ¿Se puede hacer readback después de una escritura? Todo eso se vuelve opaco.
Foundax no es una demo. Cuando un comerciante te pide que arregles su SEO, no puedes tener una herramienta de caja negra cambiando cosas silenciosamente en segundo plano.
Así que insistí en herramientas atómicas de capa inferior:
Leer campos base del producto. Leer variantes del producto. Leer inventario y precios. Leer SEO del producto. Leer traducciones del producto. Leer configuración de envío. Leer configuración de pago. Escribir un campo específico. Escribir contenido para una locale específica. Generar un borrador de modificación. Readback después de escritura.
Cada herramienta con un solo propósito, limpia, sin solapamientos. Ejecución precisa, permisos claros, fácil de probar.
Sigo pensando que esta decisión fue correcta.
El verdadero problema era otro: cuanto más atómicas son tus herramientas de capa inferior, más herramientas tienes. Cuantas más herramientas tienes, más difícil es para el modelo entenderlas y seleccionarlas en contexto.
Esa fue la primera paradoja.
Cuanto más se adapta una herramienta de capa inferior a la ejecución del sistema, menos se adapta a la interfaz cognitiva del modelo.
La atomicidad no fue el error. El error fue soltar un montón de herramientas atómicas directamente delante del modelo y esperar que eligiera consistentemente las correctas.
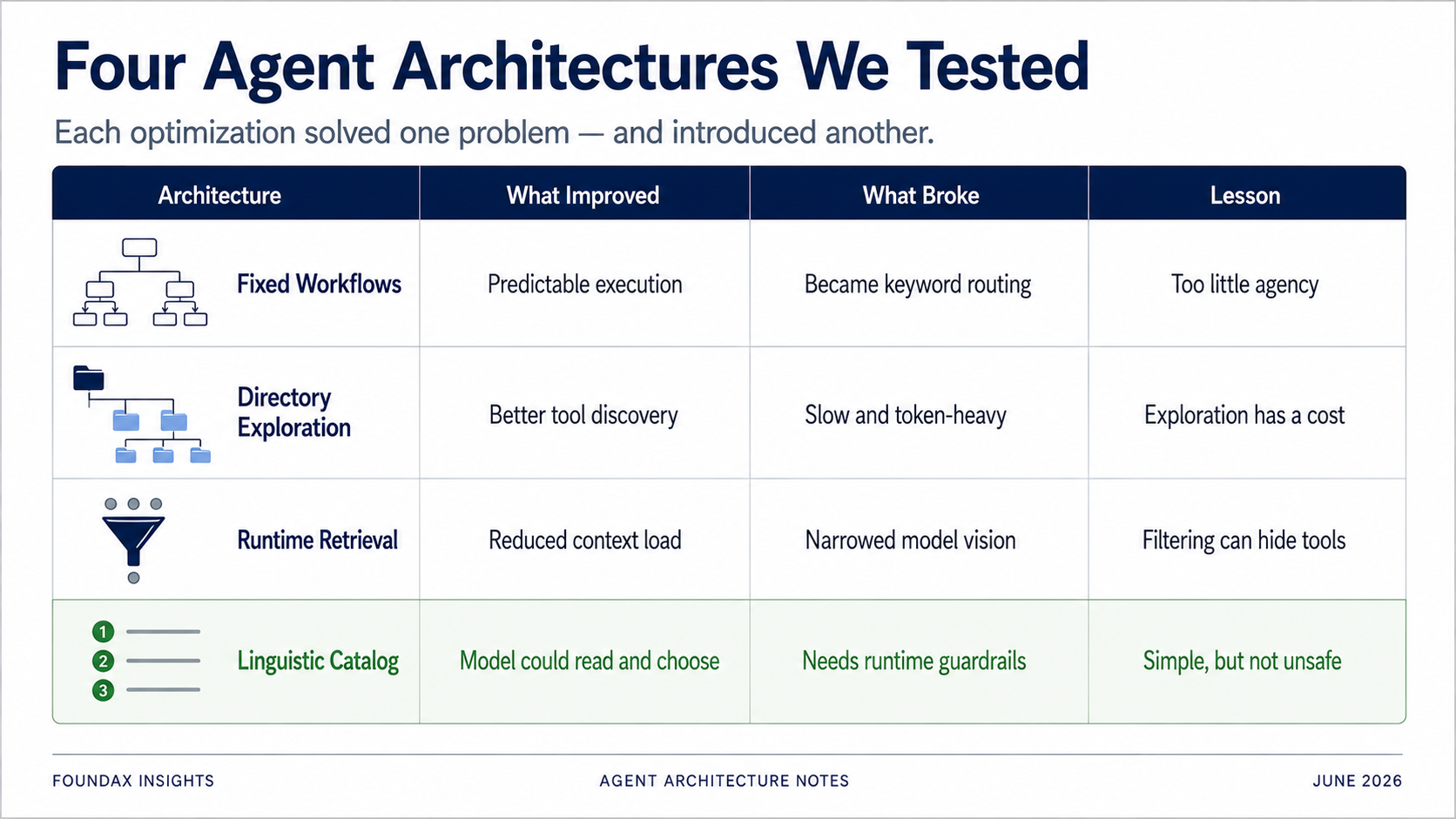
Para resolver el problema de selección de herramientas, nuestro primer intento fueron los workflows fijos.
Un instinto natural. Si las tareas de alta frecuencia de los comerciantes son finitas, pre-programémoslas.
Verificación de SEO de producto. Verificación de cobertura de traducciones. Verificación previa al lanzamiento. Diagnóstico de baja conversión. Verificación de GMC preflight.
El trabajo del modelo: identificar la intención del usuario, mapearla a un workflow, y luego pasar el control al runtime para ejecución fija.
Esto parecía seguro. Parecía bien diseñado.
Pero en pruebas, degeneró rápidamente en un sistema tonto de palabras clave.
La expresión del usuario es demasiado variada. Uno dice «¿está completo mi SEO?» Otro dice «¿Google puede indexar esta página?» Otro dice «¿metí la pata con el título del producto?» Otro dice «¿por qué mi feed no para de dar error cuando pongo anuncios?»
Para que cada variante acierte con una tarea, no paras de añadir palabras clave, alias, reglas. Al final el sistema no es preciso y es más difícil de mantener que nunca.
Y lo más importante: el modelo casi no tenía margen para operar. Era solo un clasificador de intención. La ruta de análisis real, la selección de herramientas, la secuencia de recolección de evidencia — todo predeterminado por nosotros.
Ahí fue cuando me cayó la ficha:
Si cada tarea está pre-programada en un workflow, la cosa ya no es un Agent — es una herramienta de workflow disfrazada de IA.
Los workflows fijos, en el fondo, reemplazan el razonamiento del modelo por enumeración humana de negocio. Hacen el sistema más controlable, pero despojan al Agent de su Agency.
Así que pivotamos.
En lugar de soltar todas las herramientas de golpe, las organizamos en un directorio. El modelo elige primero un dominio de negocio, luego expande subdirectorios, luego selecciona herramientas específicas.
Productos. Pedidos. Pagos. Envíos. Promociones. Analytics. GMC.
Dentro de «Productos»: información base, SKUs, inventario, precios, SEO, traducciones.
Esto era mucho más preciso que los workflows fijos. El modelo no estaba emparejando palabras clave con rutas predefinidas — estaba explorando un mapa estructurado de herramientas. Realmente encontraba las herramientas correctas con más frecuencia.
Pero el problema era obvio: velocidad.
Cada tarea requería recorrer el directorio. Las preguntas simples igual pasaban por toda la cadena de exploración. Consumo de tokens alto. Latencia alta.
Un comerciante pregunta «¿está completo el SEO de este producto?» y el Agent se comporta como si estuviera hojeando un manual técnico de 500 páginas.
La exploración por directorio no iba mal encaminada. El problema era que convertía «entender el sistema de herramientas» en un coste por invocación. El modelo tenía que re-explorar el sistema desde cero cada vez, algo difícil de aceptar como experiencia de producto.
Después construimos algo más sofisticado.
El modelo primero produce una comprensión estructurada del prompt del usuario: descomposición de intención, palabras clave, dominios de negocio involucrados, y si la tarea es read, write, mixed o unknown.
Luego este plan va al runtime. El runtime usa skills, matching por regex y metadatos de herramientas para retrieven herramientas candidatas. El modelo selecciona entre las candidatas. Después de leer los hechos, el modelo puede decidir si sigue explorando en otra ronda.
Esta versión parecía un Agent Runtime maduro. Y sí trajo progresos reales.
Por ejemplo, descubrimos que los campos estructurados pueden mejorar el comportamiento del modelo. Para evitar que el modelo agarrara la primera herramienta que parecía relevante sin leer la lista completa de candidatas, diseñamos un campo como hasreadalltools — pidiéndole al modelo que declarara explícitamente si había terminado de leer todas las candidatas antes de hacer un tool call. Eso realmente ayudó.
Pero lo más interesante fue que después descubrimos que una sola instrucción en lenguaje natural, bien escrita, podía ser más efectiva que un campo estructurado complejo.
Antes de que el modelo seleccionara herramientas, añadimos:
«Basándote en el objetivo de negocio del usuario, selecciona todas las herramientas de análisis y escritura necesarias. No te limites a coger la primera herramienta que parezca relevante.»
Antes de que el modelo se preparara para dar una respuesta, añadimos:
«No te precipites a responder. Primero determina si los hechos necesarios están completos. Si no, sigue seleccionando herramientas.»
Estos prompts tan simples mejoraron significativamente la profundidad de razonamiento del modelo.
Esto fue una llamada de atención importante:
Un LLM no es un programa tradicional. Los protocolos estructurados son útiles, pero el modelo siempre está leyendo lenguaje e imitando razonamiento. La mayoría de las veces, una instrucción en lenguaje natural precisa, directa y de baja ambigüedad funciona mejor que un campo estructurado complejo.
Pero esta arquitectura también expuso un problema más profundo.
El runtime tool retrieval fue diseñado para resolver la sobrecarga de contexto y la selección imprecisa de herramientas. Pero un runtime es, fundamentalmente, un sistema de reglas.
Ya sea regex, skills, palabras clave o filtrado por dominio — puede filtrar herramientas que el modelo realmente necesita, en la primera pasada.
Piensa en un comerciante que pregunta: «¿Por qué no se vende este producto?»
Esa pregunta podría implicar analytics. También podría implicar contenido del producto, precios, inventario, promociones, envío, pago, checkout, fuentes de tráfico, geografía, dispositivo, SEO, autenticidad de la copia de página.
Si el runtime la encasilla demasiado rápido en un solo dominio, el campo de visión del modelo queda restringido.
Esa es la tercera paradoja:
El runtime tool retrieval ahorra contexto — pero también puede convertirse en el techo del campo de visión del modelo.
Queríamos reducir la carga del modelo y terminamos potencialmente restringiendo su criterio.
A medida que crecía el número de herramientas, consideré seriamente el retrieval basado en embeddings.
La idea es natural. Prompt del usuario → vector. Descripciones de herramientas → vectores. Puntuación de similitud. Top-k al modelo.
Suena estándar. Suena «nativo de IA».
Pero cuanto más lo pensaba, más equivocado me parecía.
Para retrieval de anuncios, recomendación de contenido o búsqueda masiva de documentos, los embeddings tienen sentido. El conjunto de candidatos es enorme y los sistemas tradicionales realmente no entienden el lenguaje. Necesitas comprimir semántica en vectores para hacer matching aproximado.
Pero las herramientas de Foundax no son millones de documentos desconocidos en un mundo abierto. Son capacidades de negocio finitas, enumerables, descriptibles y comprimibles dentro de nuestro propio sistema.
Y la mayor fortaleza del LLM es precisamente leer lenguaje, entender lenguaje, comparar semántica y juzgar intención.
Así que, ¿por qué convertir descripciones de herramientas en vectores para luego usar una puntuación de similitud que decida — en nombre del modelo — lo que puede ver?
Es como tener un libro con un índice perfectamente legible. En lugar de leerlo, codificas el índice en números y haces que el lector juzgue qué capítulo leer según la distancia numérica.
Eso tiene sentido en sistemas de búsqueda tradicionales. En un Agent nativo de LLM, creo cada vez más que es un desvío.
Para un Agent de negocio como Foundax, la prioridad no es el retrieval vectorial. Es la compresión lingüística — comprimir herramientas, documentos, capacidades y límites en contexto lingüístico claro, preciso y de alta densidad que el modelo pueda leer directamente.
También nos topamos con otro problema clásico: la exposición de herramientas era demasiado pesada.
Al principio, cada herramienta exponía información muy completa al modelo: nombre de función, descripción larga, alcance de hechos, límite de respuesta, fuentes excluidas, enumeraciones de campos, enumeraciones de nivel de detalle, descripciones de argumentos, formato de retorno de observación.
Parece riguroso.
Pero finalmente me di cuenta: el modelo no necesita saber la mayor parte de esto.
Si la ejecución real de la consulta, la validación de campos, la verificación de permisos, los límites owner-executor, los flujos de confirmación y el readback son todos manejados por el runtime, entonces el modelo no tiene por qué leer el esquema API completo cada vez.
Lo que el modelo realmente necesita saber:
Por ejemplo:
Con eso basta.
Los prefijos «Read / Write / Search» en la lista de candidatas ya son suficientes para que el modelo distinga tipos de acción. Los verdaderos permisos de lectura/escritura, flujos de confirmación, límites owner-executor — esos deben quedarse dentro del runtime, aplicados en la ejecución. No gastes tokens haciendo que el modelo los lea. Y desde luego, no confíes en que el modelo los cumpla voluntariamente.
La conclusión aquí:
El esquema es para el runtime, no para el modelo. El modelo debe ver un catálogo de capacidades lingüísticas, no un diccionario de API.
Por fin hicimos la prueba más simple.
Exponer todas las herramientas al modelo como descripciones lingüísticas extremadamente comprimidas. Dejar que el modelo lea. Dejar que el modelo elija.
El resultado fue sorprendentemente bueno.
La verdad, este resultado fue un pequeño bofetón. Porque cada arquitectura compleja que habíamos construido antes estaba anclada en una suposición: el modelo no puede manejar ver demasiadas herramientas, así que el runtime debe filtrar por él.
Pero la prueba demostró que esta suposición — al menos en el contexto actual de Foundax — no se sostiene del todo.
La pregunta no es «¿se pueden exponer todas las herramientas?». La pregunta es «¿qué es exactamente lo que estás exponiendo al modelo?».
Si expones una muralla de esquemas API completos — descripciones largas, enumeraciones de campos, especificaciones de parámetros — vas a ahogar al modelo seguro. Pero si expones un catálogo de capacidades lingüísticas ligero y claro, el modelo puede leer y elegir por sí mismo — y puede que lo haga mejor que el pre-filtrado del runtime.
Esto no es volver a la exposición bruta del principio.
El principio fue: soltar el diccionario API completo sobre el modelo.
El final fue: darle al modelo un manual de operaciones comprimido — un menú de capacidades lingüísticas ligero, numerado.
Son cosas completamente distintas. Lo primero es un océano de herramientas. Lo segundo es un mapa legible.
Seamos concretos. Nuestro sistema tiene docenas de herramientas de lectura y comandos de escritura — más de cien herramientas canónicas en total. Cada tarea expone como mucho una docena de herramientas al modelo, controlado por un presupuesto de exposición. La fase de toolselection tiene un presupuesto de contexto de decenas de miles de caracteres. La descripción del esquema de cada herramienta ocupa alrededor de mil caracteres (unos pocos cientos de tokens). Exponer una docena de herramientas significa aproximadamente de diez a veinte mil caracteres — alrededor de cuatro a cinco mil tokens. Muy manejable.
¿Pero si expusiéramos todas las herramientas con sus esquemas completos? Eso serían casi doscientos mil caracteres — unos cincuenta mil tokens. Eso de verdad no cabría.
La idea clave: el runtime proporciona firmas de herramientas compactas y numeradas del registro canónico. El modelo lee una ficha, no una entrada de enciclopedia.
Sería fácil malinterpretar esto.
¿«Dejar que el modelo lea y elija» significa que el runtime no es importante?
Todo lo contrario.
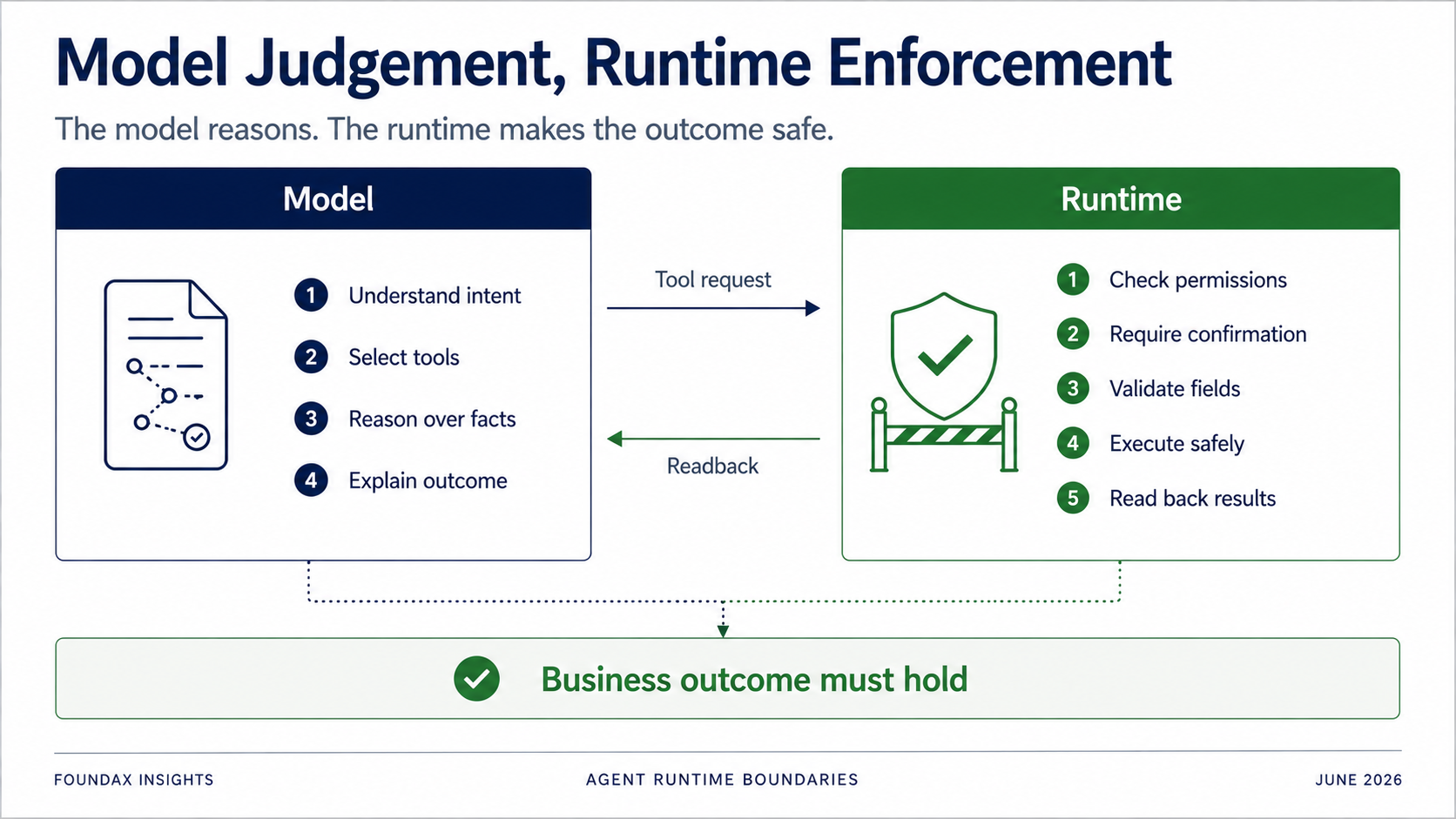
El runtime sigue siendo crítico — solo que no debe intentar pensar por el modelo prematuramente.
El modelo es responsable de entender, juzgar, seleccionar y explicar.
El runtime es responsable de permisos, confirmación, validación de campos, límites owner-executor, ejecución real y readback.
Especialmente para operaciones de escritura: no puedes absolutamente confiar en que el modelo siga las reglas voluntariamente.
El modelo puede decir «quiero actualizar el SEO de este producto».
Pero el runtime debe determinar: ¿tiene permiso el usuario actual? ¿Requiere esta acción confirmación? ¿Debería primero generar solo un borrador? ¿Está el campo en la lista blanca? ¿Pertenece el objeto al comerciante actual? ¿Tuvo éxito real la escritura? Después del readback, ¿coincide realmente el estado de negocio con el objetivo?
El objetivo del Agent no es demostrar que un tool call tuvo éxito. Es demostrar que el resultado de negocio se mantiene.
Esta frontera es esencial. No todo va al modelo, y no todo va al runtime. La verdadera cuestión es la división del trabajo.
La principal enseñanza de este viaje no es que la versión 4.0 sea definitivamente la mejor arquitectura.
Es que construir un Agent hace peligrosamente fácil dejarse llevar por una cadena de preocupaciones de ingeniería reales.
¿Preocupado porque las tareas de alta frecuencia no sean estables cuando el modelo improvisa cada vez? → Construye workflows fijos.
¿Preocupado porque el contexto sea demasiado largo y el modelo sufra dilución de atención? → Construye exploración por directorio.
¿Preocupado porque el crecimiento del número de herramientas haga explotar los tokens? → Construye runtime retrieval.
¿Preocupado porque el retrieval por palabras clave sea demasiado frágil para tareas multilingües y entre dominios? → Considera embeddings, scoring, reranking.
¿Preocupado porque el modelo elija herramientas sin leer la lista completa o dé respuestas antes de tener todos los hechos? → Añade campos estructurados de restricción.
Ninguna de estas preocupaciones es imaginaria. Todas corresponden a problemas reales.
Simplemente comprobamos — por las malas — que muchas soluciones resolvían un problema mientras introducían otro.
Los workflows fijos añadían estabilidad pero limitaban el razonamiento del modelo. La exploración por directorio era precisa pero lenta y costosa en tokens. El runtime retrieval ahorraba contexto pero podía bloquear herramientas que el modelo necesitaba. Los embeddings parecían inteligentes pero, para selección de herramientas nativa de LLM, probablemente eran un desvío. Los campos estructurados podían restringir al modelo, pero a veces un simple prompt en lenguaje natural funcionaba mejor.
Y la constatación más crítica:
Estos problemas son reales, pero no son necesariamente igual de graves en tu proyecto.
¿El contexto largo causa realmente dilución de atención en tu caso de uso? Pruébalo. ¿Tu número de herramientas hace realmente que los costes de tokens sean inaceptables? Pruébalo. ¿La exposición completa de herramientas hace realmente que tu modelo sea perezoso, dependiente del camino o propenso a errores? Pruébalo. ¿El runtime retrieval bloquea realmente herramientas que tu modelo necesita? Pruébalo también.
El error más fácil en arquitectura de Agent es tratar «problemas que realmente existen en el proyecto de otro» como «problemas que definitivamente existen en el tuyo».
Así que el primer paso para construir un Agent no es diseñar una arquitectura compleja para prevenir cada posible problema. El primer paso es probar:
¿Qué puede entender realmente el modelo en tu dominio? ¿Puede leer las descripciones de tus herramientas? ¿Puede seleccionar herramientas por sí mismo? ¿Dónde se salta hechos? ¿Qué decisiones puedes delegarle? ¿Cuáles debe imponer el runtime? ¿Qué acciones requieren confirmación del usuario? ¿Qué resultados deben verificarse con readback?
Las respuestas a estas preguntas — no una arquitectura de referencia de un post de blog — deben determinar el diseño de tu Agent.
Para Foundax, ahora tenemos claridad: las operaciones de ecommerce son un dominio que el modelo conoce bien. Embudos de conversión, páginas de producto, precios, envíos, promociones, pagos, calidad del tráfico, SEO — estos marcos analíticos aparecen incontables veces en los datos de entrenamiento. Al modelo no le falta instinto de análisis de negocio. Lo que le falta es conocimiento del sistema específico de Foundax: qué hechos puede leer, qué escrituras puede preparar, qué acciones debe poseer el runtime, qué resultados deben verificarse con readback.
Así que el Foundax Agent no consiste en enseñarle al modelo cómo hacer análisis de ecommerce. Consiste en entregarle al modelo las capacidades de negocio de Foundax en un lenguaje que pueda leer.
El primer paso para construir un Agent de negocio no es diseñar una arquitectura perfecta. Es probar hasta dónde puedes confiar realmente en el modelo.
No somos los únicos que están llegando a estas conclusiones.
En diciembre de 2024, Anthropic publicó su guía "Building Effective Agents". Su mensaje central: la simplicidad gana. Empieza con la solución más simple posible. Un LLM aumentado con acceso a herramientas puede ser todo lo que necesitas. Cuando lo leí en su momento, asentí. Después de vivir lo que he descrito arriba, lo entiendo visceralmente.
Luego, en mayo de 2026, LangChain celebró su conferencia Interrupt con un giro notable: el tema pasó de «¿pueden los agentes llegar a producción?» a «escalado empresarial y operaciones de producción». El verdadero cuello de botella, como enfatizaron sus materiales, no es escribir agentes — es gestionarlos en producción a escala.
Un creciente cuerpo de investigación refuerza esta dirección. El trabajo de Google DeepMind de 2025 sobre las limitaciones de los embeddings demostró matemáticamente que los embeddings vectoriales de tamaño fijo pierden información estructural y relacional a escala — directamente relevante para cualquiera que esté considerando retrieval de herramientas basado en embeddings. El concepto de Neo4j de "context engineering" sostiene que la IA fiable viene de la arquitectura, no de frases ingeniosas en los prompts.
Nuestra experiencia se alinea con una dirección que vemos en toda la industria: los patrones simples/componibles de Anthropic, el énfasis de LangChain en operaciones de producción sobre abstracciones de frameworks. Menos andamiaje prefabricado, más capacidad directa del modelo — pero siempre validado contra uso real, no adoptado como doctrina. Menos pre-filtrado, más criterio del modelo. La pregunta no es «¿cómo construimos una arquitectura perfecta alrededor del modelo?». Es «¿cómo le damos al modelo lo que realmente necesita y nos quitamos de en medio?».
Esto no convierte las conclusiones de Foundax en universales. Negocios diferentes, modelos diferentes, superficies de herramientas diferentes llegarán a respuestas diferentes. Lo que es universal es el método: probar primero, diseñar después.
P: ¿Significa esto que siempre debería exponer todas las herramientas al modelo?
No. Depende de tu número de herramientas, tu modelo, tu presupuesto de contexto y tu dominio. La cuestión no es «exponer siempre todo». La cuestión es: prueba antes de filtrar. No asumas que el modelo no puede manejarlo — verifícalo. En nuestro caso, alrededor de una docena de firmas de herramientas comprimidas por tarea era manejable y efectivo. Tus números pueden ser distintos.
P: ¿Cuándo debería usar workflows fijos en su lugar?
Cuando la tarea es genuinamente determinista, el riesgo de error es catastrófico y el conocimiento previo del modelo en ese dominio es débil. Los workflows no son malos — son malos cuando reemplazan razonamiento que el modelo podría haber hecho. Úsalos para barreras de seguridad y post-procesamiento determinista, no como sustituto del criterio del modelo.
P: ¿Cuál es la diferencia entre un catálogo lingüístico y un esquema API?
Un catálogo lingüístico le dice al modelo lo que una herramienta puede hacer, en lenguaje natural comprimido — por ejemplo, «Read: [12] Product Variants — SKU / precio / inventario / estado de disponibilidad». Un esquema API le dice al modelo cómo llamar a la herramienta, con especificaciones completas de parámetros, enumeraciones y restricciones. El modelo necesita el menú de capacidades. El runtime necesita el manual técnico. Mezclar estas dos cosas es uno de los errores más caros que puedes cometer.
P: ¿Cómo decido qué va al modelo y qué al runtime?
Una buena heurística: el modelo maneja comprensión, juicio, selección y explicación. El runtime maneja permisos, ejecución, confirmación, validación y readback. Si le estás pidiendo al modelo que imponga reglas, estás en el lado equivocado de la línea. El modelo sugiere; el runtime decide y ejecuta.
P: ¿Y el coste? ¿Exponer más herramientas no aumenta el consumo de tokens?
En nuestro caso, un catálogo lingüístico comprimido fue de hecho más barato que la exploración por directorio multi-ronda o las cadenas de retrieval. Cada entrada de herramienta ocupa alrededor de mil caracteres. Con una docena de herramientas expuestas por tarea, el total es de aproximadamente diez a veinte mil caracteres — alrededor de cuatro a cinco mil tokens. Compáralo con múltiples rondas de descomposición de intención, retrieval, revisión de candidatos y re-selección. El enfoque más simple fue a menudo más eficiente en tokens, no menos.
P: ¿Cuál fue la idea más importante de todo este proceso?
Que «ayudar al modelo» y «restringir al modelo» pueden parecer idénticos desde la perspectiva del diseñador, pero tienen efectos opuestos en el sistema. Cada arquitectura que construimos pretendía ayudar. La mayoría terminaron restringiendo. La diferencia solo se hizo visible mediante pruebas. Si te llevas una sola cosa de este artículo, que sea esto: prueba lo que tu modelo puede hacer realmente antes de ponerte a diseñar arquitectura para compensar lo que asumes que no puede.