DTC 站点 vs 电商平台:agentic commerce 时代怎么分工
agentic commerce 会增强平台分发能力,但 DTC 站点仍然是品牌掌控商品事实、信任、客户数据和测量的核心位置。
阅读全文
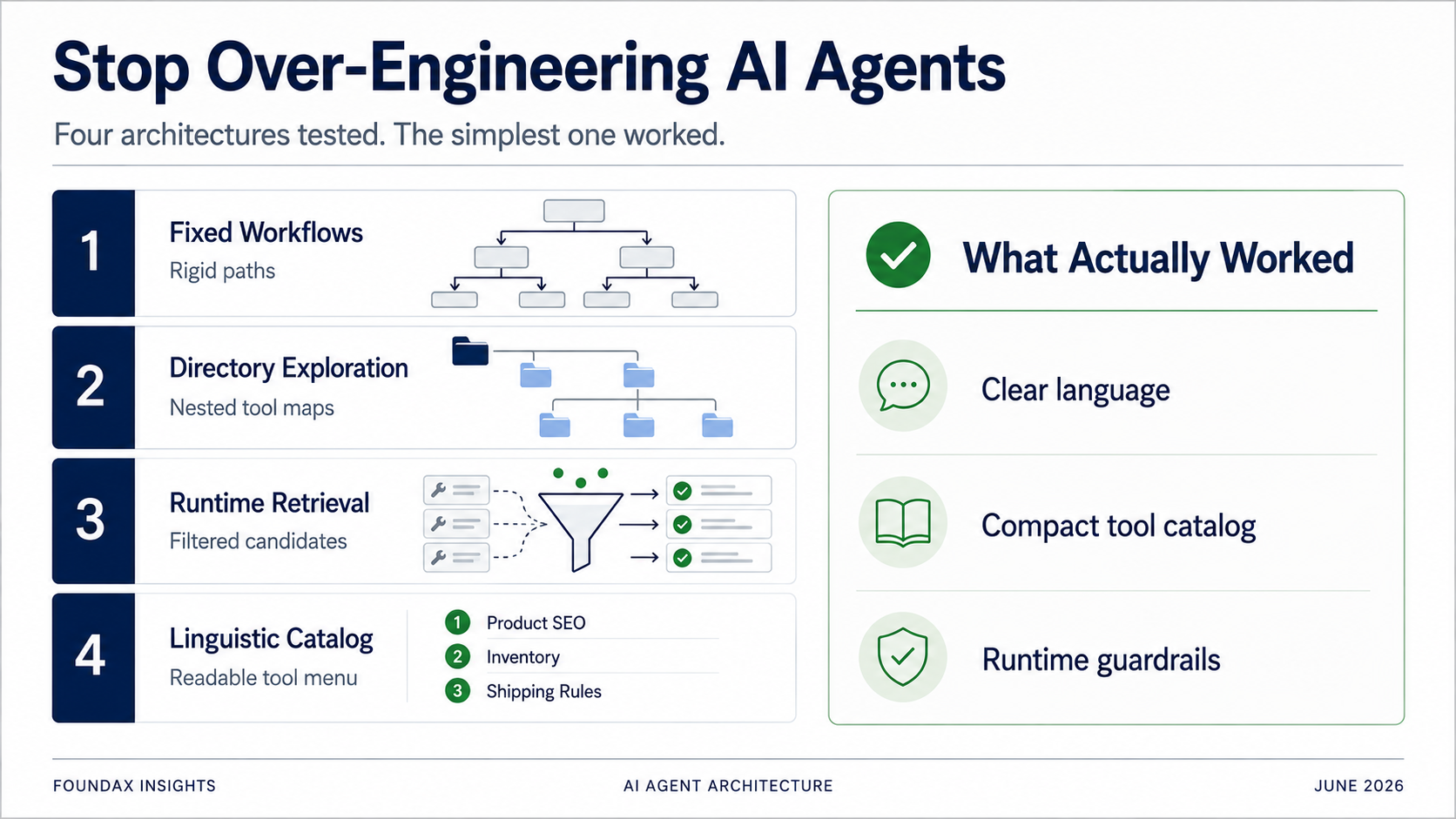
Foundax 的 AI Agent 经历了四代架构迭代——从固定工作流到目录式探索,再到运行时检索,最后回归到一个轻量的语言化能力目录。每一次「优化」,本质上都是在替模型做模型本可以自己做的决定。这是我们交过的所有学费。
我做 Foundax Agent 的过程中,有一个很荒谬的时刻。
我们前前后后试了很多架构:固定 workflow、目录式工具探索、skills 推荐工具组合、runtime 召回、rg 匹配、结构化 plan、多轮 ReAct,甚至中间一度认真考虑过 embedding。
每一版看起来都有道理。
工具太多,所以要筛选。模型容易漏看,所以要约束。上下文太长,所以要召回。执行要安全,所以要流程化。业务要精准,所以底层工具必须原子化。
这些判断单独看都没错。
但最后我们做了一个最简单、甚至有点粗暴的测试:把所有工具压缩成一份轻量的语言化目录,直接丢给模型,让它自己读、自己选。
结果效果出奇地好。
那一刻我真的有点无语。
因为这意味着,前面很多复杂设计,并不是在释放模型能力,而是在提前假设模型不行,然后用架构把它层层包起来。
重点不在于证明「全量暴露工具就是最佳实践」。
更重要的是:做业务型 Agent,最危险的不是模型不够聪明,而是你还没测试模型在你这个业务里的能力边界,就已经开始替它设计笼子。
Foundax 是一个电商 SaaS 平台。
所以 Foundax Agent 面对的,不是普通聊天,也不是单纯的知识问答,而是商家在后台里真实会遇到的经营问题。
商家不会说:
「请调用某个接口读取 product variant 字段。」
他们只会说:
「为什么这个商品卖不动?」
「我的西语页面是不是还没弄好?」
「这个商品能不能投 Google Shopping?」
「为什么很多人加购了,但是没有付款?」
「帮我把缺失的 SEO 补上。」
这些问题听起来都是自然语言,但背后牵涉的不是一句自然语言回答,而是一整套业务系统。
商品、SKU、库存、价格、SEO、翻译、促销、运费、支付、checkout、订单、退款、GMC feed、前台展示状态——任何一个地方都可能影响最终结果。
所以 Foundax Agent 的目标不是「回答得像人」。
它真正要做的是:理解商家的真实意图,找到系统里对应的事实,选择正确工具,必要时准备写入,并且在 runtime 的约束下按权限、确认、readback 的规范执行。
用户输入可以是模糊的。但系统执行必须是精准的。
这就是后面所有架构纠结的起点。
我是一个有工程洁癖的人。
所以一开始设计 Foundax Agent 的时候,我天然不接受那种很粗的工具。
比如一个工具叫 analyzeProductReadiness,听起来很方便,但它内部到底读了什么字段、用了什么判断标准、有没有权限边界、写入后能不能 readback,其实都会变得很模糊。
Foundax 不是一个 demo。商家让你改 SEO,你不能拿一个黑盒工具在里面乱改一通。
所以我一开始坚持底层工具原子化:
读商品基础字段。读商品 variants。读库存和价格。读商品 SEO。读商品翻译。读物流配置。读支付配置。写某个字段。写某个 locale 的内容。生成修改草稿。写入后 readback。
每个工具尽量单一、清楚、互相不重叠。这样执行精准,权限清晰,测试也容易。
这个判断到现在我仍然觉得是对的。
真正的问题是另一个:底层工具越原子化,工具数量就越多;工具数量越多,模型就越难在上下文里理解和选择。
这是我遇到的第一个悖论。
底层工具越适合系统执行,就越不适合作为模型的认知界面。
原子化不是错。错的是把一堆原子工具直接丢给模型,然后期待模型每次都能稳定选对。
为了解决工具选择问题,我们最早尝试的是固定 workflow。
这个思路很自然。既然商家高频任务有限,那就把常见任务提前编排好。
比如:商品 SEO 检查。翻译覆盖检查。商品上线预检 检查。转化率低诊断。GMC 预检 检查。
模型只负责识别用户意图,然后命中某个 workflow,后面交给 runtime 固定执行。
这个方案看起来很安全,也很工程化。
但测试下来,很快发现它会退化成一个很蠢的 keyword 系统。
因为用户表达太多样了。同样是想检查商品 SEO,有人会说「SEO 全了吗」,有人会说「这个页面能不能被 Google 收录」,有人会说「商品标题是不是没写好」,有人会说「为什么投广告的时候 feed 一直报错」。
为了让各种说法都能命中任务,只能不断堆关键词、堆 alias、堆规则。最后系统不但不准,还越来越难维护。
更重要的是,模型在这个架构里几乎没有发挥空间。它只是一个意图分类器。真正的分析路径、工具选择、取证顺序,全都由我们提前写死。
这时我开始意识到一个问题:
如果所有任务都被提前编排成 workflow,那这个东西本质上就不是 Agent,而是一个披着 AI 外衣的流程工具。
固定 workflow 的本质,是用人的业务枚举替代模型推理。它能让系统更可控,但也会让 Agent 失去 Agent 性。
后来我们换了一个方向。
既然全量工具太多,那就做成目录。模型先选择业务域,再展开子目录,再选择具体工具。
比如:商品。订单。支付。物流。促销。数据分析。GMC。
商品下面再有商品基础信息、SKU、库存、价格、SEO、翻译等工具。
这个方案比固定 workflow 准很多。因为模型不是靠关键词命中某个流程,而是在一个结构化的工具地图里探索。它确实更容易找到正确工具。
但问题也很明显:慢。
每次任务都要展开目录。简单问题也要走探索链路。token 消耗很大,延迟也高。
用户只是问一句「这个商品 SEO 全了吗」,Agent 却像在翻一本很厚的后台说明书。
目录式探索的问题不是方向错,而是它把「理解工具系统」变成了每次运行时的成本。模型每次都要重新探索一遍系统,这在产品体验上很难接受。
再后来,我们做了一个更复杂的方案。
模型先对用户 prompt 做结构化理解:intent decomposition、关键词、涉及的业务 domain、任务是 read、write、mix 还是 unknown。
然后把这个 plan 交给 runtime。runtime 根据 skills、rg、tool meta 去召回候选工具,再让模型从候选工具里选择。模型读完 facts 后,可以继续决定要不要进入下一轮探索。
这一版看起来已经很像一个成熟的 Agent Runtime。它也确实带来了一些阶段性成果。
比如,我们发现结构化字段可以改善模型行为。为了防止模型没看全工具就直接选第一个看起来相关的工具,我们设计过类似 hasreadalltools 的字段,让模型在 tool call 时显式声明自己是否已经读完候选工具。这个确实有帮助。
但更有意思的是,后来我们发现,一句简单的自然语言提示,有时候比复杂结构化字段更有效。
比如在模型选工具前,加一句:
「请结合用户的业务目标,选择所有必要的分析和写入工具,不要只选择第一个看起来相关的工具。」
在模型准备输出答案前,再加一句:
「不要急着回答,先判断需要的事实是否已经完整;如果不完整,可以继续选择工具。」
这样反而明显提升了模型的深度思考能力。
这件事给了我一个很大的提醒:
LLM 不是传统程序。结构化协议有用,但模型始终是在读语言、模仿推理。很多时候,一句准确、直接、低歧义的自然语言提示,比一个复杂字段更有效。
但这一版架构也暴露了更深的问题。
runtime 召回工具,本来是为了解决上下文太长、模型选工具不准的问题。但 runtime 本质上还是规则系统。无论是 rg、skills、关键词还是 domain 过滤,它都有可能在第一步就筛掉模型真正需要的工具。
比如用户问:「为什么这个商品卖不动?」
这个问题可能涉及 analytics,也可能涉及商品内容、价格、库存、促销、运费、支付、checkout、流量来源、地域、设备、SEO、页面文案真实性。
如果 runtime 太早把它归到某个 domain,模型的视野就被限制了。
这就是第三个悖论:
runtime 召回工具可以节省上下文,但也可能成为模型视野的天花板。
我们本来是想帮模型减少负担,结果可能反过来限制了模型的判断。
在工具越来越多之后,我中间一度真的认真考虑过 embedding。
这个想法很自然。用户 prompt 转成向量。tool description 转成向量。算相似度。top-k 交给模型。
听起来很标准,也很「AI」。
但我越想越觉得不对。
如果是广告召回、内容推荐、海量文档检索,embedding 很合理,因为候选集巨大,传统系统确实不理解语言,需要把语义压成向量,再做近似匹配。
但 Foundax 的工具不是开放世界里的几百万个未知文档。它们是我们自己系统里有限、可枚举、可描述、可压缩的业务能力。
而 LLM 本来最擅长的事情就是读语言、理解语言、比较语义、判断意图。
那为什么还要先把工具说明转成向量,再用一个相似度分数替 LLM 决定它能看到什么?
这就像一本书本来有目录。目录应该直接写清楚每一章大概讲什么。结果你把目录变成一串数字编码,再让读者通过数字距离判断自己该读哪一章。
这件事在传统搜索系统里可以理解。但在 LLM-native 的 Agent 里,我越来越觉得它是绕路。
对 Foundax 这种业务型 Agent 来说,优先级不是 vector retrieval,而是 language compression。也就是,把工具、文档、能力、边界,压缩成清楚、准确、高密度的语言上下文,让模型直接读。
我们还遇到过另一个典型问题:tool exposure 太重。
早期每个 tool 暴露给模型的信息非常完整:function name、长 description、fact scope、answer boundary、excluded sources、fields enum、detailLevel enum、args 描述、observation 返回说明。
看起来很严谨。
但后来我发现,这里面很多东西模型根本没必要知道。
如果真正的查询、写入、字段校验、权限校验、owner executor、confirmation、readback 都由 runtime 执行,那模型每次没有必要读完整 API schema。
模型真正需要知道的是:这个工具大概能查什么、对应哪个业务事实、什么时候可能相关、选择它应该用哪个 id。
比如:
这就够了。
甚至 can read / can write 也不需要每个工具重复暴露。候选短语里的前缀「读 / 写 / 搜」已经足够让模型区分动作类型。真正的 read/write 权限、confirmation、owner executor 边界,必须留在 runtime 内部强制校验。不能浪费 token 让模型读,更不能依赖模型自觉遵守。
这里我们得到的结论是:
schema 是给 runtime 的,不是给模型的。模型应该看到语言化能力目录,而不是 API 字典。
最后,我们做了一个最朴素的测试。
把所有 tools 以极简语言化描述暴露给模型,让模型自己看,自己选。
结果出奇地好。
说实话,这个结果有点打脸。因为我们之前所有复杂架构,几乎都是围绕一个假设:模型看不了太多工具,所以 runtime 必须帮它筛选。
但测试结果说明,这个假设至少在 Foundax 当前的场景里,并不完全成立。
问题不是「工具能不能全部暴露」。问题是「你暴露给模型的到底是什么」。
如果暴露的是一堆完整 API schema、长 description、字段 enum、参数说明,那确实会把模型淹没。但如果暴露的是一份轻量、清楚、语言化的能力目录,模型其实可以自己读、自己选,而且效果可能比 runtime 先筛一轮更好。
这不是回到最开始的粗暴全量暴露。
最开始是:全量 API 字典丢给模型。
最后是:全量轻量能力菜单交给模型。
这两件事完全不同。前者是工具海。后者是给模型一本压缩过的操作手册。
拿具体数字来说:我们的系统有 数十个读工具和写命令——共一百多个 canonical tools。每次任务暴露给模型的工具数受 exposure budget 控制,最多十几个。toolselection 阶段的上下文预算为 几万字符。每个工具的 schema 描述估约 一千多字符(约几百 tokens)。十几个工具暴露给模型的 schema 总量约 一两万字符 ≈ 四五千 tokens——完全在可控范围内。
但如果全量暴露 所有工具的完整 schema?约 近二十万字符 ≈ 约五万 tokens——确实放不下。
关键就在于:runtime 以极简语言化描述暴露 compact numbered tool signatures,模型读到的是一张索引卡,而不是百科全书的条目。
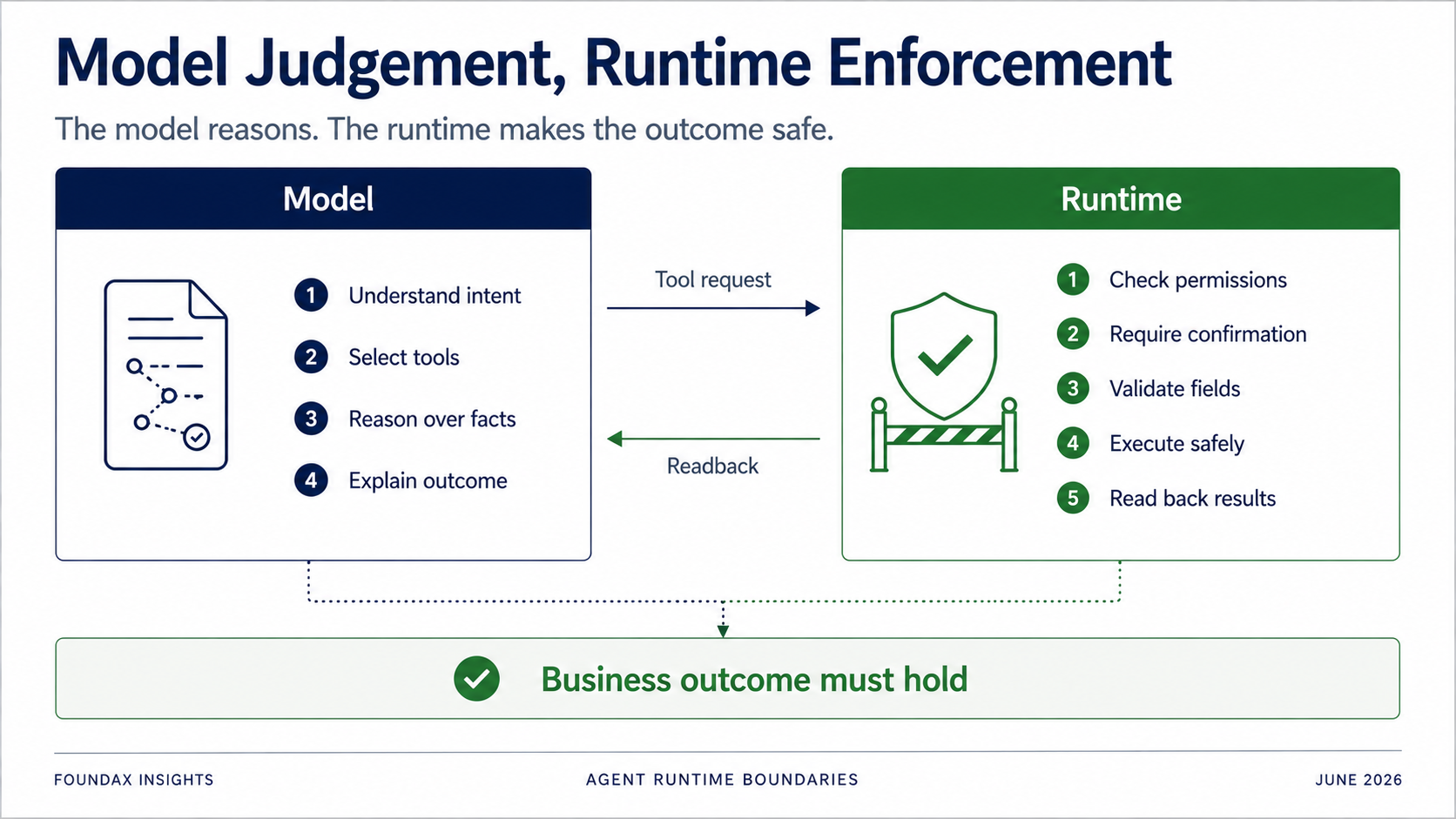
这里很容易产生一个误解:既然我们最后选择让模型自己看工具、自己选工具,是不是 runtime 就不重要了?
恰恰相反。
runtime 仍然非常重要,只是它不应该过早替模型思考。
模型可以负责理解、判断、选择、解释。但 runtime 必须负责权限、确认、字段校验、owner executor 边界、实际执行和 readback。
尤其是写入场景,绝对不能依赖模型自觉遵守规则。
模型可以说「我想更新这个商品的 SEO」。但 runtime 必须判断:当前用户有没有权限、这个动作是否需要确认、它是不是只能先生成草稿、字段是否在白名单里、对象是否属于当前 merchant、写入后是否成功、readback 后业务状态是否真的符合目标。
Agent 的目标不是证明 tool call 成功。而是证明业务结果成立。
这个边界非常重要。不是所有东西都交给模型,也不是所有东西都交给 runtime。真正的问题是分工。
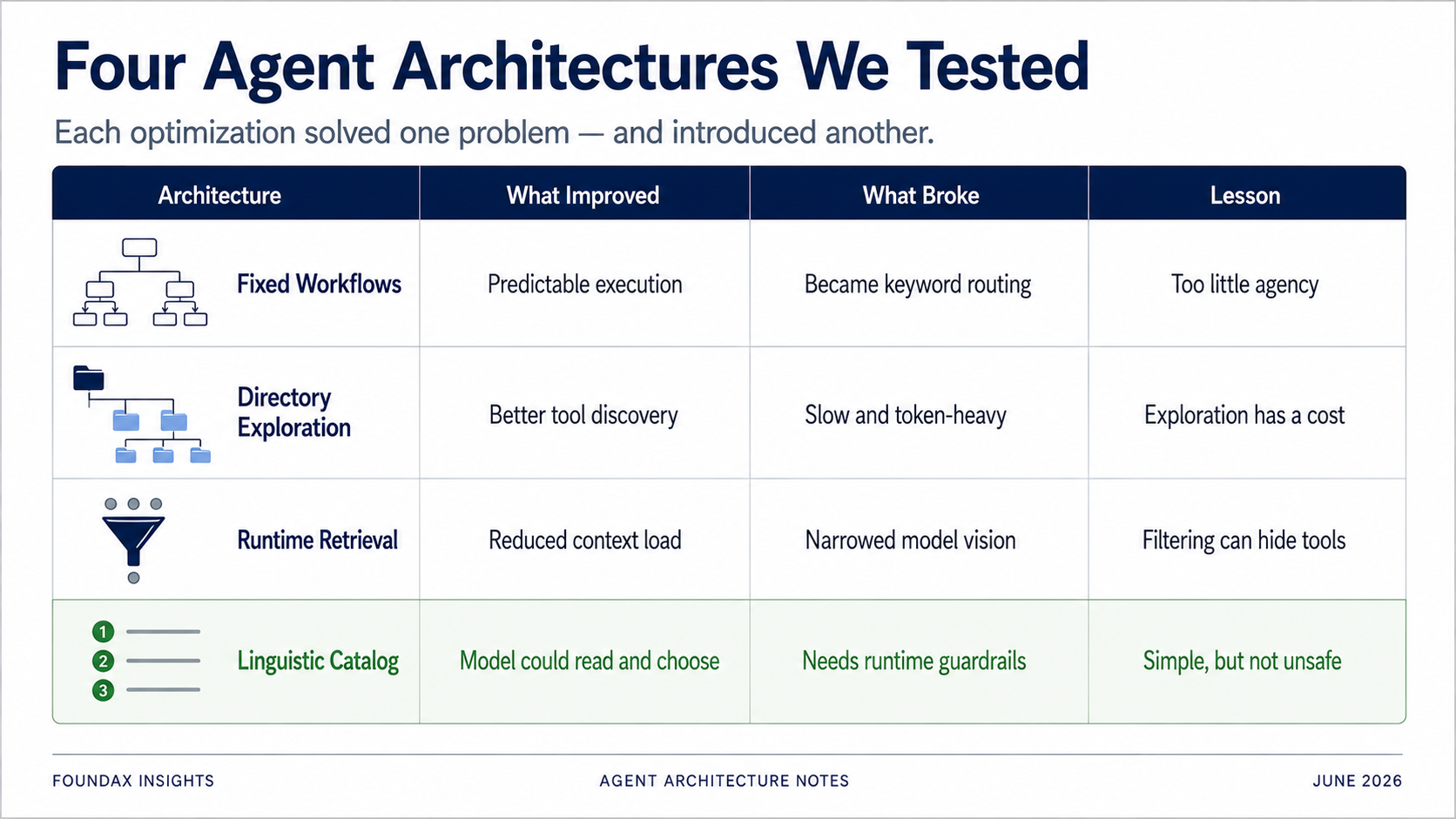
这轮探索最大的收获,不是 4.0 一定最好。
而是我意识到,做 Agent 很容易被一连串真实工程问题推着走。
因为担心高频任务每次都靠模型临场推理不够稳定,所以想把部分业务场景做成固定 workflow。因为担心上下文太长,模型出现 attention dilution,看不全工具说明,所以想做目录式展开。因为担心工具数量膨胀导致 token 爆炸,推高调用成本和响应延迟,所以想让 runtime 先召回候选工具。因为担心 runtime 靠关键词召回太脆弱,遇到多语言、模糊表达、跨 domain 任务时匹配不准,所以一度想研究 embedding。因为担心模型没读完工具就选择,或者 facts 不完整就急着输出答案,所以想加结构化字段约束它。
这些担心都不是空穴来风。它们都对应着真实问题。
只是后来我们发现,很多方案虽然解决了一个问题,却又引入了另一个问题。
固定 workflow 稳定,但限制了模型推理。目录式探索准确,但速度慢、token 浪费。runtime 召回省 context,但可能挡住模型真正需要的工具。embedding 看起来智能,但对 LLM-native 的工具选择来说,可能是绕路。结构化字段能约束模型,但有时一句自然语言提示效果更好。
更关键的是:
这些问题真实存在,但不一定在你的项目里同样严重。
上下文太长会不会导致 attention dilution?要测。工具数量多会不会导致 token 成本不可接受?要测。全量工具暴露会不会让模型偷懒、路径依赖、选错工具?要测。runtime 召回会不会反而挡住模型需要的工具?也要测。
Agent 架构最容易犯的错,就是把「别人项目里真实存在的问题」,提前当成「自己项目里一定存在的问题」。
所以做 Agent 的第一步,不是先设计一套复杂架构去预防所有可能的问题,而是先测试:
模型在你的业务里到底能理解到什么程度?它能不能读你的工具说明?它能不能自己选工具?它会在哪些场景漏事实?哪些环节可以交给它判断?哪些环节必须由 runtime 强制兜底?哪些动作必须用户确认?哪些结果必须 readback?
这些问题的答案,才应该决定你的 Agent 架构。
对 Foundax 来说,我们现在更清楚了:电商经营是模型非常熟悉的领域。转化率、funnel、商品页、价格、运费、促销、支付、流量质量、SEO——这些分析框架在训练语料里出现过无数次。模型并不缺这类商业分析思路。它真正缺的是:在 Foundax 这个系统里,它可以读取哪些事实,可以准备哪些写入,哪些动作必须由 runtime 接管,哪些结果必须 readback。
所以 Foundax Agent 不是要教模型怎么做电商分析。而是要把 Foundax 的业务能力,用模型能读懂的方式交给它。
做业务型 Agent,第一步不是设计完美架构,而是测试你到底能多大程度相信模型。
我们并不是唯一得出这些结论的人。
2024 年 12 月,Anthropic 发表了那篇后来被反复引用的 《Building Effective Agents》。核心观点:简单就是好。从最简单的方案开始。一个带工具调用的增强型 LLM 可能就是你需要的全部。我当时读到的时候点了点头。等到亲身经历了上面这一切之后,我才真正从骨子里理解了这句话。
然后,紧接着,2026 年 5 月,LangChain 在 Interrupt 大会上发布了一个值得关注的转向:大会主题从「Agent 能不能进生产环境」变成了「企业级规模与生产化运营」。他们强调的真正瓶颈不是写 Agent,而是在规模化的生产环境中运营 Agent。
越来越多的研究也在佐证这个方向。Google DeepMind 2025 年关于 embedding 局限性的工作,从数学上证明了固定维度向量嵌入在大规模场景下会丢失结构性和关系性信息——这对任何考虑用 embedding 做工具检索的人来说,都是直接相关的警示。Neo4j 提出的「上下文工程」概念则强调:可靠的 AI 来自架构设计,而非聪明的话术。
我们的经验与行业中正在浮现的方向一致:Anthropic 的 simple/composable 模式、LangChain 从框架抽象转向生产运营的强调。更少的预制脚手架,更直接的模型能力——但始终要经过实际场景验证,而不是当成教条照搬。少预筛选,多让模型判断。真正的问题不是「如何围绕模型设计一套完美架构」,而是「如何把模型真正需要的东西用它能读懂的方式交给它,然后让开」。
这不意味着 Foundax 的结论放之四海皆准。不同的业务、不同的模型、不同的工具面,会有不同的答案。放之四海皆准的是方法:先测试,再设计。
Q:这意味着我应该始终把所有工具暴露给模型吗?
不是。这取决于你的工具数量、使用的模型、上下文预算和业务领域。关键不是「始终暴露一切」,而是「先测试,再筛选」。不要假设模型处理不了——去验证。在我们的场景中,每次任务暴露 十几个压缩后的工具签名是可控且有效的。你的数字可能不同。
Q:什么时候应该用固定 workflow?
当任务确实具有高度确定性、错误代价极高、且模型在该领域的背景知识薄弱时。workflow 本身没有错——错的是用它来替代模型本可以完成的推理。把它用在安全兜底和确定性后处理上,不要用它替代模型判断。
Q:语言化目录和 API schema 的区别到底是什么?
语言化目录告诉模型一个工具「能做什么」,用压缩的自然语言——比如「读:[12] 商品变体 — SKU / 价格 / 库存 / 可售状态」。API schema 告诉模型「怎么调用」,包含完整参数规格、枚举值、约束条件。模型需要的是能力菜单。runtime 需要的是技术手册。把这两者混淆,是你能犯的最昂贵的错误之一。
Q:如何判断什么交给模型、什么交给 runtime?
一个实用的启发式:模型负责理解、判断、选择、解释。runtime 负责权限、执行、确认、校验、readback。如果你让模型去执行规则,你就站错了边。模型建议,runtime 决策并执行。
Q:成本呢?暴露更多工具不会增加 token 消耗吗?
在我们的实际对比中,压缩后的语言化目录反而比多轮目录探索或检索链路更省钱。每个工具条目约一千多字符,每次暴露十几个工具,总计约一两万字符——约四五千 tokens。相比之下,多轮 intent decomposition、检索、候选审查、再选择,往往消耗更多。简单方案在 token 效率上经常胜出。
Q:整个过程中最重要的一个洞察是什么?
「帮助模型」和「限制模型」在设计师眼中可能看起来一模一样,但对系统的影响截然相反。我们设计的每一层架构,初衷都是帮助模型。但大多数最终都在限制它。这个区别只有通过测试才能看清。如果你只能从这篇文章带走一句话,那就是:在开始设计架构来弥补你假设模型做不到的事情之前,先测它到底能不能做到。