Agentic commerce çağında DTC site ve pazaryeri
Pazaryerlerini kullanırken ürün verisi, müşteri ilişkisi, içerik ve ölçümü DTC kanalında da biriktirmek için pratik rehber.
Devamını oku
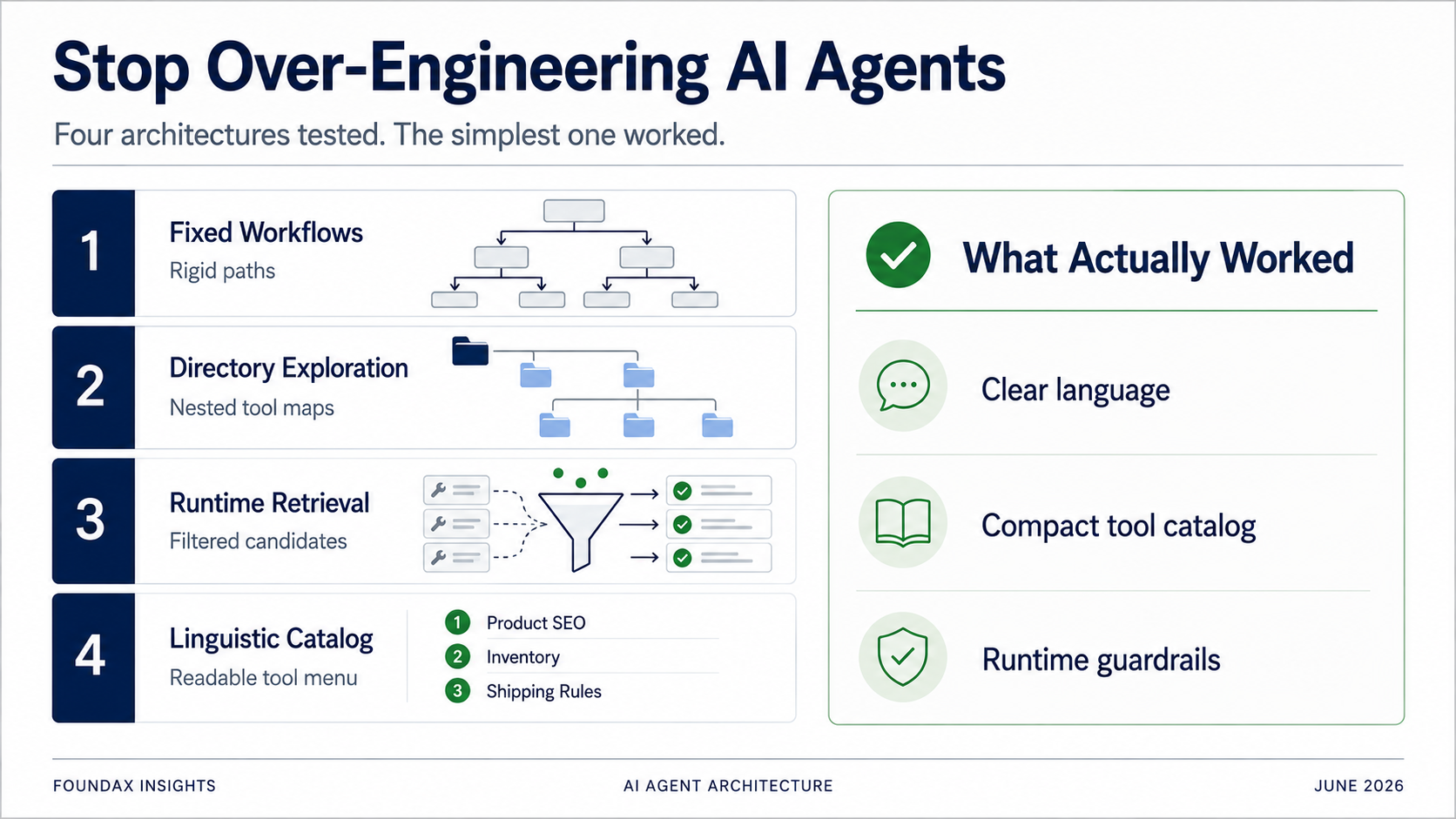
Sabit workflow'lardan hafif bir dilsel kataloğa kadar dört Agent mimarisi. Her 'optimizasyon' aslında modelin işini bizim yapmamızdı. Kazanan mimari, akıllı olmaya çalışmayı bırakandı.
Foundax Agent'i geliştirirken sürekli döndüğüm absürt bir an var.
Bir sürü mimari denedik. Sabit workflow'lar. Dizin tabanlı araç keşfi. Skill tabanlı araç önerisi. Runtime retrieval. Regex eşleştirme. Yapılandırılmış planlar. Çok turlu ReAct döngüleri. Hatta bir ara ciddi ciddi embedding tabanlı retrieval'i düşündük.
Her versiyon kağıt üzerinde mantıklıydı.
Çok fazla araç var, o zaman filtrelemeliyiz. Model bazı şeyleri kaçırıyor, o zaman kısıtlamalıyız. Context çok uzun, o zaman retrieval yapmalıyız. Yürütme güvenli olmalı, o zaman prosedürel hale getirmeliyiz. İş hassasiyeti atomik alt katman araçları gerektirir.
Tek tek ele alındığında, bu yargıların hiçbiri yanlış değildi.
Ama sonra en basit — hatta neredeyse kaba — testi yaptık: tüm araçları hafif bir dilsel kataloğa sıkıştır, modele ver, bırak kendi okusun ve seçsin.
Sonuç şaşırtıcı derecede iyiydi.
Gerçekten nutkum tutuldu.
Çünkü bu, karmaşık tasarımlarımızın çoğunun modelin yeteneklerini açığa çıkarmak değil, modelin başarısız olacağını varsayıp onu mimari katmanlarla sarmak olduğu anlamına geliyordu.
Bu makale "tüm araçları göstermek en iyi pratiktir" demiyor.
Asıl söylemek istediğim şu: bir iş Agent'i inşa etmenin en büyük tehlikesi, modelin yeterince akıllı olmaması değil — modelin senin alanında neler yapabileceğini test etmeden onun için bir kafes tasarlamaya başlamandır.
Foundax bir e-ticaret SaaS platformu.
Bu yüzden Foundax Agent sıradan sohbetle ya da genel bilgi soru-cevapla uğraşmıyor. Satıcıların arka panelde karşılaştığı gerçek operasyonel sorunlarla uğraşıyor.
Satıcılar şöyle demez:
"Lütfen product variant okuma API'sini çağır."
Şöyle derler:
"Bu ürün neden satmıyor?"
"İspanyolca sayfam hazır mı?"
"Bu ürün Google Shopping'de çalışır mı?"
"İnsanlar neden sepete atıp ödemiyor?"
"Eksik SEO'larımı tamamla."
Bu sorular doğal dil gibi duyuluyor, ama her birinin arkasında koca bir iş sistemi var. Ürünler, SKU'lar, envanter, fiyatlandırma, SEO, çeviriler, promosyonlar, kargo, ödeme, checkout, siparişler, iadeler, GMC feed'leri, mağaza önyüz görünüm durumu — bunlardan herhangi biri sonucu etkileyebilir.
Bu yüzden Foundax Agent'in hedefi "insan gibi konuşmak" değil.
Gerçekten yapması gereken şey: satıcının gerçek niyetini anlamak, sistemdeki karşılık gelen gerçekleri bulmak, doğru araçları seçmek, gerektiğinde yazma işlemlerini hazırlamak ve runtime kısıtları altında — izinler, onay ve readback ile — yürütmek.
Kullanıcı girdisi bulanık olabilir. Sistem yürütmesi kesin olmalıdır.
Bu gerilim, bundan sonraki tüm mimari ikilemlerin başlangıç noktasıdır.
Bende mühendislik mükemmeliyetçiliği var.
Bu yüzden Foundax Agent'i tasarlamaya başladığımda, kaba araçları içgüdüsel olarak reddettim.
analyzeProductReadiness adında bir araç kulağa kullanışlı geliyor. Ama içeride hangi alanları okuyor? Hangi kriterleri uyguluyor? İzin sınırları nerede? Yazma sonrası readback yapabiliyor musun? Hepsi opaklaşıyor.
Foundax bir demo değil. Bir satıcı SEO'sunu düzeltmeni istediğinde, arka planda sessizce değişiklik yapan bir kara kutu aracı kullanamazsın.
Bu yüzden atomik alt katman araçlarında ısrar ettim:
Ürün temel alanlarını oku. Ürün variant'larını oku. Envanter ve fiyatlandırmayı oku. Ürün SEO'sunu oku. Ürün çevirilerini oku. Kargo yapılandırmasını oku. Ödeme yapılandırmasını oku. Belirli bir alanı yaz. Belirli bir locale için içerik yaz. Değişiklik taslağı oluştur. Yazma sonrası readback yap.
Her araç tek amaçlı, temiz, örtüşmeyen. Kesin yürütme, net izinler, test etmesi kolay.
Bu yargının hâlâ doğru olduğunu düşünüyorum.
Asıl sorun başka bir şeydi: alt katman araçların ne kadar atomikse, o kadar çok aracın olur. Ne kadar çok aracın varsa, modelin onları context içinde anlayıp seçmesi o kadar zorlaşır.
Bu ilk paradigmaydı.
Bir alt katman aracı sistem yürütmesine ne kadar uygunsa, modelin bilişsel arayüzüne o kadar az uygundur.
Atomiklik hata değildi. Hata, bir yığın atomik aracı doğrudan modelin önüne döküp her seferinde doğru olanları tutarlı şekilde seçmesini beklemekti.
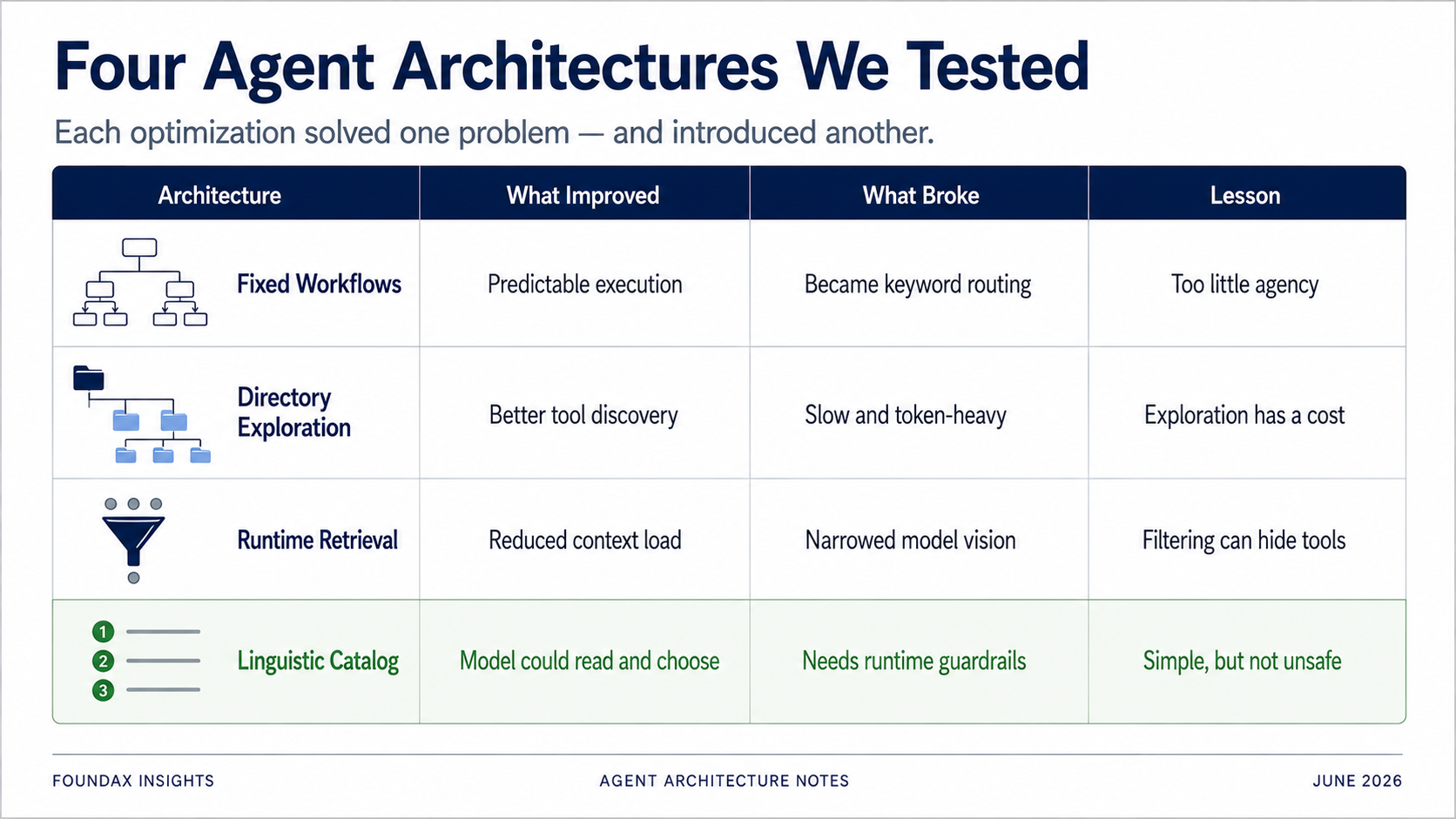
Araç seçimi sorununu çözmek için ilk denememiz sabit workflow'lardı.
Bu doğal bir içgüdüydü. Satıcıların yüksek frekanslı görevleri sınırlıysa, önceden betikle.
Ürün SEO kontrolü. Çeviri kapsamı kontrolü. Ürün lansman hazırlık kontrolü. Düşük dönüşüm teşhisi. GMC hazırlık kontrolü.
Modelin işi, kullanıcı niyetini tanımlamak, bir workflow'a eşlemek ve sonra sabit yürütme için runtime'a devretmekti.
Bu güvenli görünüyordu. Mühendislik kokuyordu.
Ama testte, hızla aptal bir anahtar kelime sistemine dönüştü.
Kullanıcı ifadesi çok çeşitli. Biri "SEO'm tamam mı?" der. Başkası "Google bu sayfayı indeksleyebilir mi?" der. Bir diğeri "ürün başlığını mı batırdım?" der. Başka biri "reklamları çalıştırdığımda feed neden sürekli hata veriyor?" der.
Her varyasyonu bir göreve isabet ettirmek için sürekli anahtar kelime, takma ad, kural eklersin. Sonunda sistem ne isabetli, ne de bakımı mümkün.
Daha da önemlisi, modelin neredeyse hiç hareket alanı yoktu. Sadece bir niyet sınıflandırıcıydı. Asıl analiz yolu, araç seçimi, kanıt toplama sıralaması — hepsi bizim tarafımızdan önceden belirlenmişti.
İşte o an dank etti:
Her görev bir workflow'a önceden betiklenmişse, o şey artık bir Agent değildir — AI kostümü giymiş bir workflow aracıdır.
Sabit workflow'lar, özünde, model akıl yürütmesini insan iş sıralamasıyla değiştirir. Sistemi daha kontrol edilebilir yaparlar, ama Agent'i Agency'sinden arındırırlar.
Sonra yön değiştirdik.
Tüm araçları bir kerede dökmek yerine, bir dizin halinde düzenle. Model önce bir iş alanı seçsin, sonra alt dizinleri genişletsin, sonra belirli araçları seçsin.
Ürünler. Siparişler. Ödemeler. Kargo. Promosyonlar. Analitik. GMC.
"Ürünler" altında: temel bilgiler, SKU'lar, envanter, fiyatlandırma, SEO, çeviriler.
Bu, sabit workflow'lardan çok daha isabetliydi. Model anahtar kelimeleri önceden tanımlanmış bir yola eşlemiyordu — yapılandırılmış bir araç haritasını keşfediyordu. Gerçekten daha sık doğru araçları buldu.
Ama sorun açıktı: hız.
Her görev dizin geçişi gerektiriyordu. Basit sorular bile keşif zincirinden geçiyordu. Token tüketimi yüksekti. Gecikme yüksekti.
Bir satıcı "bu ürünün SEO'su tamam mı?" diye soruyor ve Agent kalın bir arka panel kılavuzunu karıştırıyormuş gibi davranıyor.
Dizin keşfi yön olarak yanlış değildi. Sorun, "araç sistemini anlamayı" çağrı başına bir maliyete dönüştürmesiydi. Model her seferinde sistemi sıfırdan yeniden keşfetmek zorundaydı ki bu, ürün deneyimi olarak kabul edilebilir değil.
Sonra daha sofistike bir şey inşa ettik.
Model önce kullanıcı prompt'unun yapılandırılmış bir anlayışını üretir: niyet ayrıştırması, anahtar kelimeler, ilgili iş alanları ve görevin okuma, yazma, karma veya bilinmeyen olup olmadığı.
Sonra bu plan runtime'a gider. Runtime; skills, regex eşleştirme ve araç metadata'sını kullanarak aday araçları getirir. Model adaylar arasından seçer. Gerçekleri okuduktan sonra, model başka bir turda keşfe devam edip etmemeye karar verebilir.
Bu versiyon olgun bir Agent Runtime gibi görünüyordu. Ve gerçekten bazı ilerlemeler sağladı.
Örneğin, yapılandırılmış alanların model davranışını iyileştirebileceğini keşfettik. Modelin, tam aday listesini okumadan ilgili görünen ilk aracı kapmasını önlemek için hasreadalltools gibi bir alan tasarladık — modelden, bir araç çağrısı yapmadan önce tüm adayları okumayı bitirip bitirmediğini açıkça beyan etmesini istedik. Bu gerçekten yardımcı oldu.
Ama daha ilginç olanı: sonradan, iyi yazılmış tek bir doğal dil talimatının karmaşık bir yapılandırılmış alandan daha etkili olabileceğini bulduk.
Model araçları seçmeden önce şunu ekledik:
"Kullanıcının iş hedefine dayanarak, gerekli tüm analiz ve yazma araçlarını seç. Sadece ilgili görünen ilk aracı seçme."
Model bir cevap çıktısı vermeye hazırlanmadan önce şunu ekledik:
"Cevaplamak için acele etme. Önce gerekli gerçeklerin tamam olup olmadığını belirle. Değilse, araç seçmeye devam et."
Bu basit prompt'lar modelin akıl yürütme derinliğini önemli ölçüde iyileştirdi.
Bu büyük bir uyanıştı:
LLM geleneksel bir program değildir. Yapılandırılmış protokoller faydalıdır, ama model her zaman dili okur ve akıl yürütmeyi taklit eder. Çoğu zaman, tek bir hassas, doğrudan, düşük belirsizlikli doğal dil talimatı, karmaşık bir yapılandırılmış alandan daha iyi çalışır.
Ancak bu mimari daha derin bir sorunu da açığa çıkardı.
Runtime araç retrieval'i, context aşırı yükü ve hatalı araç seçimi sorunlarını çözmek için tasarlanmıştı. Ama bir runtime, özünde, bir kurallar sistemidir.
İster regex, skills, anahtar kelimeler veya alan filtreleme olsun — modelin gerçekten ihtiyaç duyduğu araçları daha ilk geçişte filtreleyebilir.
Şu satıcıyı düşün: "Bu ürün neden satmıyor?"
Bu soru analitiği içerebilir. Ayrıca ürün içeriğini, fiyatlandırmayı, envanteri, promosyonları, kargoyu, ödemeyi, checkout'u, trafik kaynaklarını, coğrafyayı, cihazı, SEO'yu, sayfa kopya özgünlüğünü de içerebilir.
Runtime hevesle tek bir alana sınıflandırırsa, modelin görüş alanı kısıtlanır.
Bu üçüncü paradoks:
Runtime araç retrieval'i context tasarrufu sağlar — ama aynı zamanda modelin görüş alanının tavanı haline de gelebilir.
Modelin yükünü azaltmak için yola çıktık, modelin muhakemesini kısıtlama ihtimaliyle sonuçlandık.
Araç sayısı arttıkça, embedding tabanlı retrieval'i ciddi ciddi düşündüm.
Fikir doğal. Kullanıcı prompt'u → vektör. Araç açıklamaları → vektörler. Benzerlik skoru. Top-k modele.
Standart geliyor. "AI-native" geliyor.
Ama üzerinde düşündükçe daha yanlış hissettirdi.
Reklam retrieval'i, içerik önerisi veya devasa doküman araması için embedding'ler mantıklı. Aday kümesi muazzam ve geleneksel sistemler gerçekten dili anlayamıyor. Yaklaşık eşleştirme için anlamı vektörlere sıkıştırman gerek.
Ama Foundax'in araçları açık bir dünyadaki milyonlarca bilinmeyen doküman değil. Kendi sistemimiz içindeki sonlu, sayılabilir, tanımlanabilir, sıkıştırılabilir iş yetenekleri.
Ve LLM'in en büyük gücü tam olarak dil okumak, dili anlamak, anlamları karşılaştırmak ve niyeti yargılamak.
O zaman neden araç açıklamalarını vektörlere dönüştürüp, sonra bir benzerlik skoru kullanarak — model adına — neyi göreceğine karar veresin?
Mükemmel okunabilir bir içindekiler tablosu olan bir kitaba sahip olmak gibi. Okumak yerine, içindekiler tablosunu sayılara kodluyor ve okuyucunun sayısal mesafeye dayanarak hangi bölümü okuyacağına karar vermesini sağlıyorsun.
Bu geleneksel arama sistemlerinde mantıklı. LLM-native bir Agent'te, bunun giderek bir sapma olduğuna inanıyorum.
Foundax gibi bir iş Agent'i için öncelik vektör retrieval değil. Öncelik dilsel sıkıştırma — araçları, dokümanları, yetenekleri ve sınırları, modelin doğrudan okuyabileceği açık, doğru, yüksek yoğunluklu dilsel context'e sıkıştırmak.
Bir başka klasik sorunla da karşılaştık: araç gösterimi çok ağırdı.
Başlangıçta, her araç modele çok eksiksiz bilgi gösteriyordu: fonksiyon adı, uzun açıklama, gerçek kapsamı, cevap sınırı, hariç tutulan kaynaklar, alan enum'ları, detay seviyesi enum'ları, argüman açıklamaları, gözlem dönüş formatı.
Titiz görünüyor.
Ama sonunda fark ettim: modelin bunların çoğunu bilmesine gerek yok.
Gerçek sorgu yürütme, alan doğrulama, izin kontrolü, sahip yürütücü sınırları, onay akışları ve readback'in hepsi runtime tarafından ele alınıyorsa, modelin her seferinde tam API şemasını okumasının anlamı yok.
Modelin gerçekten bilmesi gereken:
Örneğin:
Bu yeterli.
Aday listesindeki "Oku / Yaz / Ara" önekleri, modelin eylem türlerini ayırt etmesi için zaten yeterli. Gerçek okuma/yazma izinleri, onay akışları, sahip yürütücü sınırları — bunlar runtime içinde kalmalı, yürütme anında uygulanmalı. Modelin onları okuması için token yakma. Ve kesinlikle modelin gönüllü olarak uymasına güvenme.
Buradaki sonuç:
Şema runtime içindir, model için değil. Model dilsel bir yetenek kataloğu görmeli, bir API sözlüğü değil.
Sonunda, en basit testi yaptık.
Tüm araçları son derece sıkıştırılmış dilsel açıklamalar olarak modele göster. Bırak model okusun. Bırak model seçsin.
Sonuç şaşırtıcı derecede iyiydi.
Dürüst olmak gerekirse, bu sonuç biraz tokat gibiydi. Çünkü daha önce inşa ettiğimiz her karmaşık mimari tek bir varsayıma dayanıyordu: model çok fazla araç görmeyi kaldıramaz, o yüzden runtime onun için filtrelemeli.
Ama test gösterdi ki bu varsayım — en azından Foundax'in mevcut context'inde — tam olarak geçerli değil.
Soru "tüm araçlar gösterilebilir mi?" değil. Soru "modele tam olarak ne gösteriyorsun?"
Eğer tam API şemalarından oluşan bir duvar gösteriyorsan — uzun açıklamalar, alan enum'ları, parametre spesifikasyonları — modeli kesinlikle boğarsın. Ama hafif, açık, dilsel bir yetenek kataloğu gösteriyorsan, model kendi başına okuyup seçebilir — ve runtime'ın ön filtrelemesinden daha iyi bir iş çıkarabilir.
Bu, başlangıçtaki kaba tam gösterime dönüş değil.
Başlangıç şuydu: tam API sözlüğünü modelin önüne dökmek.
Son şuydu: modele sıkıştırılmış bir operasyon kılavuzu vermek — hafif, numaralandırılmış, dilsel bir yetenek menüsü.
Bunlar tamamen farklı şeyler. İlki bir araç okyanusu. İkincisi okunabilir bir harita.
Somut olayım. Sistemimizde düzinelerce okuma aracı ve yazma komutu var — toplamda yüzden fazla kanonik araç. Her görev, bir gösterim bütçesiyle kontrol edilerek modele en fazla bir düzine kadar araç gösterir. toolselection aşamasının on binlerce karakterlik bir context budget'i var. Her aracın şema açıklaması yaklaşık bin küsür karakter (birkaç yüz token). Bir düzine araç göstermek yaklaşık on ila yirmi bin karakter — yaklaşık dört ila beş bin token demek. Gayet yönetilebilir.
Ama tüm araçları tam şemalarıyla gösterseydik? Bu yaklaşık iki yüz bin karakter — yaklaşık elli bin token. Bu gerçekten sığmazdı.
Kilit içgörü: runtime, kanonik kayıttan sıkıştırılmış, numaralandırılmış araç imzaları sağlar. Model bir indeks kartı okur, ansiklopedi maddesi değil.
Bunu yanlış yorumlamak kolay olurdu.
"Bırak model okusun ve seçsin" runtime'ın önemsiz olduğu anlamına mı geliyor?
Tam tersi.
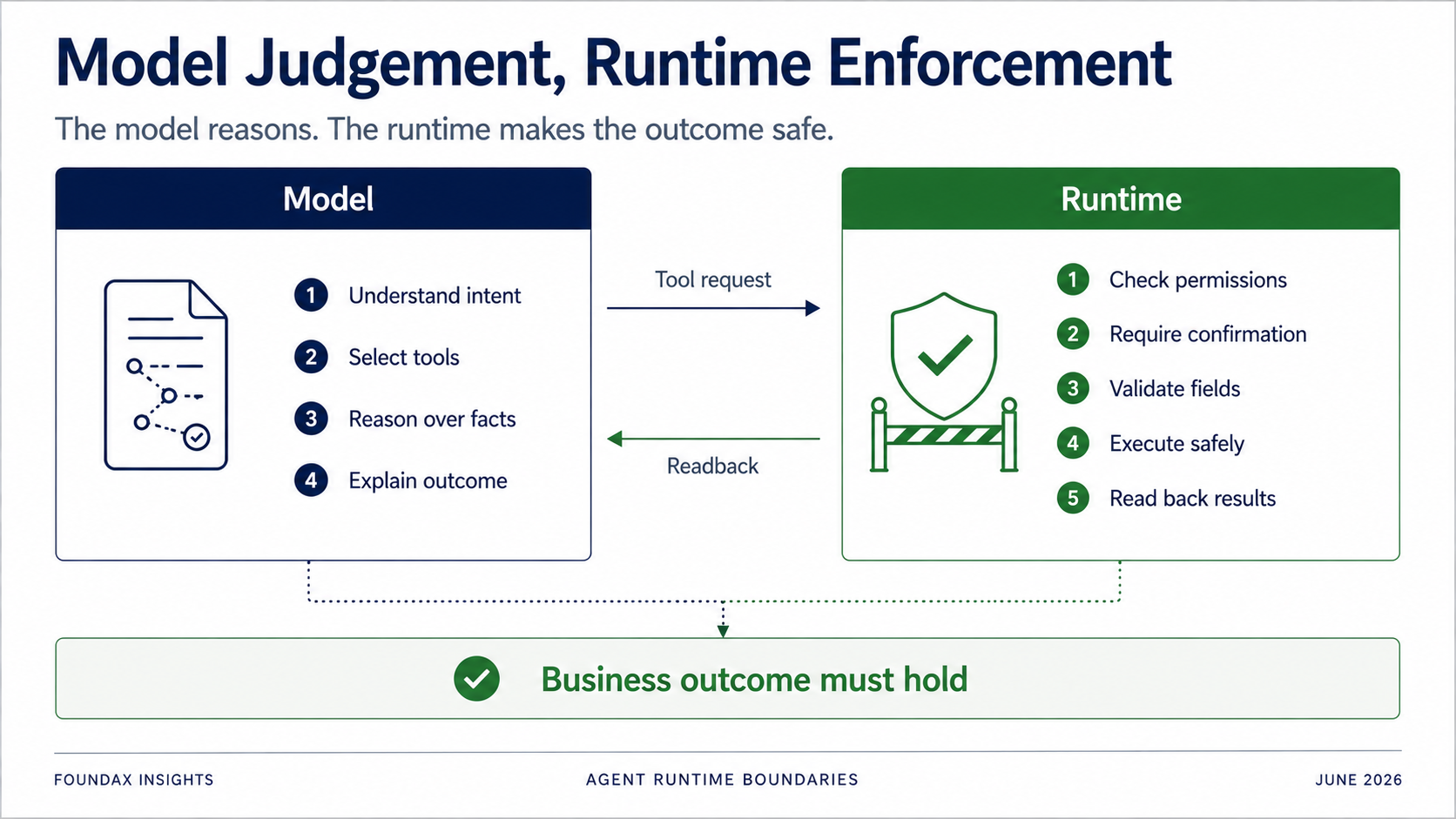
Runtime hâlâ kritik — sadece model için erkenden düşünmeye çalışmamalı.
Model anlamaktan, yargılamaktan, seçmekten ve açıklamaktan sorumludur.
Runtime izinlerden, onaydan, alan doğrulamadan, sahip yürütücü sınırlarından, gerçek yürütmeden ve readback'ten sorumludur.
Özellikle yazma işlemleri için: modelin gönüllü olarak kurallara uymasına kesinlikle güvenemezsin.
Model "Bu ürünün SEO'sunu güncellemek istiyorum" diyebilir.
Ama runtime belirlemelidir: Mevcut kullanıcının izni var mı? Bu eylem onay gerektiriyor mu? Önce sadece bir taslak mı oluşturmalı? Alan allowlist'te mi? Nesne mevcut satıcıya mı ait? Yazma gerçekten başarılı oldu mu? Readback'ten sonra, iş durumu gerçekten hedefle eşleşiyor mu?
Agent'in hedefi bir tool call'un başarılı olduğunu kanıtlamak değildir. İş sonucunun geçerli olduğunu kanıtlamaktır.
Bu sınır hayatidir. Her şey modele gitmez, her şey runtime'a gitmez. Asıl soru iş bölümüdür.
Bu yolculuğun en büyük çıkarımı 4.0'ın kesin olarak en iyi mimari olduğu değil.
Bir Agent inşa etmenin, seni gerçek mühendislik endişelerinden oluşan bir zincirle sürüklenmeye tehlikeli derecede açık hale getirmesi.
Yüksek frekanslı görevlerin model her seferinde doğaçlama yaptığında kararlı olmamasından mı endişeleniyorsun? → Sabit workflow'lar inşa et.
Context'in çok uzun olmasından ve modelin dikkat dağılmasından mı endişeleniyorsun? → Dizin keşfi inşa et.
Araç sayısındaki artışın token'ları patlatmasından mı endişeleniyorsun? → Runtime retrieval inşa et.
Anahtar kelime tabanlı retrieval'in çok dilli ve alanlar arası görevler için çok kırılgan olmasından mı endişeleniyorsun? → Embedding'leri, skorlamayı, yeniden sıralamayı düşün.
Modelin tam listeyi okumadan araç seçmesinden veya gerçekler tamamlanmadan cevap vermesinden mi endişeleniyorsun? → Yapılandırılmış kısıt alanları ekle.
Bu endişelerin hiçbiri hayali değil. Hepsi gerçek sorunlara karşılık geliyor.
Sadece — zor yoldan — bulduk ki birçok çözüm bir sorunu çözerken başka bir sorunu getirdi.
Sabit workflow'lar kararlılık ekledi ama model akıl yürütmesini sınırladı. Dizin keşfi isabetliydi ama yavaş ve token ağırdı. Runtime retrieval context tasarrufu sağladı ama modelin ihtiyaç duyduğu araçları engelleyebildi. Embedding'ler akıllı göründü ama LLM-native araç seçimi için muhtemelen bir sapmaydı. Yapılandırılmış alanlar modeli kısıtlayabildi, ama bazen doğal dil prompt'u daha iyi çalıştı.
Ve daha kritik farkındalık:
Bu sorunlar gerçek, ama senin projende aynı derecede şiddetli olmayabilirler.
Uzun context senin kullanım durumunda gerçekten dikkat dağılmasına neden oluyor mu? Test et. Araç sayın token maliyetlerini gerçekten kabul edilemez yapıyor mu? Test et. Tam araç gösterimi modelini gerçekten tembel, yol-bağımlı veya hata eğilimli yapıyor mu? Test et. Runtime retrieval modelinin ihtiyaç duyduğu araçları gerçekten engelliyor mu? Onu da test et.
Agent mimarisindeki en kolay hata, "başkasının projesinde gerçekten var olan sorunları", "senin projende kesinlikle var olan sorunlar" olarak ele almaktır.
Bu yüzden bir Agent inşa etmenin ilk adımı, olası her sorunu önceden önlemek için karmaşık bir mimari tasarlamak değil. Test etmektir:
Model senin alanında gerçekten neyi anlayabiliyor? Araç açıklamalarını okuyabiliyor mu? Kendi başına araç seçebiliyor mu? Nerede gerçekleri kaçırıyor? Hangi kararları ona devredebilirsin? Hangilerini runtime zorunlu kılmalı? Hangi eylemler kullanıcı onayı gerektirir? Hangi sonuçlar readback edilmeli?
Bu soruların cevapları — bir blog yazısındaki referans mimari değil — Agent'inin tasarımını belirlemelidir.
Foundax için artık netliğe sahibiz: e-ticaret operasyonları modelin iyi bildiği bir alan. Dönüşüm hunileri, ürün sayfaları, fiyatlandırma, kargo, promosyonlar, ödeme, trafik kalitesi, SEO — bu analitik çerçeveler eğitim verilerinde sayısız kez görünür. Model iş analizi içgüdülerinden yoksun değil. Yoksun olduğu şey Foundax'in spesifik sisteminin bilgisi: hangi gerçekleri okuyabilir, hangi yazmaları hazırlayabilir, hangi eylemleri runtime sahiplenmeli, hangi sonuçlar readback edilmeli.
Bu yüzden Foundax Agent modele e-ticaret analizini öğretmekle ilgili değil. Foundax'in iş yeteneklerini, okuyabileceği bir dilde modele vermekle ilgili.
Bir iş Agent'i inşa etmenin ilk adımı mükemmel bir mimari tasarlamak değildir. Modele gerçekten ne kadar güvenebileceğini test etmektir.
Bu sonuçlara varan tek biz değiliz.
Aralık 2024'te Anthropic "Building Effective Agents" rehberini yayınladı. Temel mesajı: basitlik kazanır. Mümkün olan en basit çözümle başla. Araç erişimli güçlendirilmiş bir LLM, ihtiyacın olan tek şey olabilir. O zaman okuduğumda başımı salladım. Yukarıda anlattıklarımı yaşadıktan sonra, içgüdüsel olarak anlıyorum.
Ardından Mayıs 2026'da LangChain, Interrupt konferansını kayda değer bir pivotla düzenledi: tema 'agent'ler production'a gidebilir mi'den 'kurumsal ölçek ve production operasyonları'na kaydı. Gerçek darboğaz, materyallerinde vurgulandığı gibi, agent yazmak değil — onları ölçekli olarak production'da yönetmek.
Büyüyen bir araştırma gövdesi bu yönü güçlendiriyor. Google DeepMind'ın 2025'teki embedding sınırlamaları çalışması, sabit boyutlu vektör embedding'lerinin ölçekte yapısal ve ilişkisel bilgi kaybettiğini matematiksel olarak gösterdi — embedding tabanlı araç retrieval'i düşünen herkes için doğrudan ilgili. Neo4j'ün "context engineering" kavramı, güvenilir AI'ın akıllı prompt ifadesinden değil, mimariden geldiğini savunuyor.
Deneyimimiz, endüstride gördüğümüz bir yönle örtüşüyor: Anthropic'in basit/birleştirilebilir pattern'leri, LangChain'in framework soyutlamaları yerine production operasyonlarına vurgusu. Daha az önceden inşa edilmiş iskele, daha fazla doğrudan model yeteneği — ama her zaman gerçek kullanıma karşı doğrulanmış, doktrin olarak benimsenmemiş. Daha az ön filtreleme, daha fazla model muhakemesi. Soru "modelin etrafında nasıl mükemmel bir mimari inşa ederiz?" değil. Soru "modele gerçekten ihtiyacı olanı nasıl verir ve yolundan çekiliriz?"
Bu, Foundax'in sonuçlarını evrensel yapmaz. Farklı işletmeler, farklı modeller, farklı araç yüzeyleri farklı cevaplara varacaktır. Evrensel olan yöntemdir: önce test et, sonra tasarla.
S: Bu, tüm araçları her zaman modele göstermem gerektiği anlamına mı geliyor?
Hayır. Araç sayına, modeline, context budget'ine ve alanına bağlı. Mesele "her zaman her şeyi göster" değil. Mesele: filtrelemeden önce test et. Modelin kaldıramayacağını varsayma — doğrula. Bizim durumumuzda, görev başına bir düzine kadar sıkıştırılmış araç imzası yönetilebilir ve etkiliydi. Senin rakamların farklı olabilir.
S: Ne zaman sabit workflow'lar kullanmalıyım?
Görev gerçekten deterministik olduğunda, hata riski felaket boyutunda olduğunda ve modelin o alandaki arka plan bilgisi zayıf olduğunda. Workflow'lar yanlış değil — modelin yapabileceği akıl yürütmeyi değiştirdiklerinde yanlıştırlar. Onları güvenlik korkulukları ve deterministik post-processing için kullan, model muhakemesinin yerine geçecek şekilde değil.
S: Dilsel katalog ile API şeması arasındaki fark nedir?
Dilsel katalog, modele bir aracın ne yapabileceğini sıkıştırılmış doğal dilde söyler — örn. "Oku: [12] Product Variants — SKU / fiyat / envanter / kullanılabilirlik durumu." API şeması modele aracı nasıl çağıracağını, tam parametre spesifikasyonları, enum'lar ve kısıtlarla söyler. Modelin yetenek menüsüne ihtiyacı var. Runtime'ın teknik kılavuza ihtiyacı var. Bu ikisini karıştırmak yapabileceğin en pahalı hatalardan biridir.
S: Modele vs. runtime'a neyin gideceğine nasıl karar veriyorsun?
İyi bir sezgisel: model anlama, yargılama, seçme ve açıklamayı yönetir. Runtime izin, yürütme, onay, doğrulama ve readback'i yönetir. Modelden kuralları uygulamasını istiyorsan, çizginin yanlış tarafındasın. Model önerir; runtime karar verir ve yürütür.
S: Maliyet ne olacak? Daha fazla araç göstermek token kullanımını artırmaz mı?
Bizim durumumuzda, sıkıştırılmış dilsel katalog aslında çok turlu dizin keşfinden veya retrieval zincirlerinden daha ucuzdu. Her araç girdisi yaklaşık bin küsür karakter. Görev başına bir düzine kadar araçla, toplam yaklaşık on ila yirmi bin küsür karakter — yaklaşık dört ila beş bin token. Bunu çoklu niyet ayrıştırma, retrieval, aday inceleme ve yeniden seçim turlarıyla karşılaştır. Daha basit yaklaşım genellikle token açısından daha verimliydi, daha az değil.
S: Bu sürecin en önemli tek içgörüsü neydi?
"Modele yardım etmek" ve "modeli kısıtlamak" tasarımcının bakış açısından aynı görünebilir, ama sistem üzerinde zıt etkileri vardır. İnşa ettiğimiz her mimari yardım etmeyi amaçlıyordu. Çoğu kısıtlamayla sonuçlandı. Fark sadece testle netleşti. Bu makaleden tek bir şey alacaksan, şu olsun: modelinin yapamayacağını varsaydığın şeyleri telafi etmek için mimari tasarlamaya başlamadan önce, modelinin gerçekten ne yapabildiğini test et.