ไซต์ DTC กับ marketplace ในยุค agentic commerce
คู่มือปฏิบัติสำหรับใช้ marketplace พร้อมสร้างช่องทาง DTC ที่เก็บข้อมูลสินค้า ความสัมพันธ์ลูกค้า คอนเทนต์ และการวัดผล
อ่านเพิ่มเติม
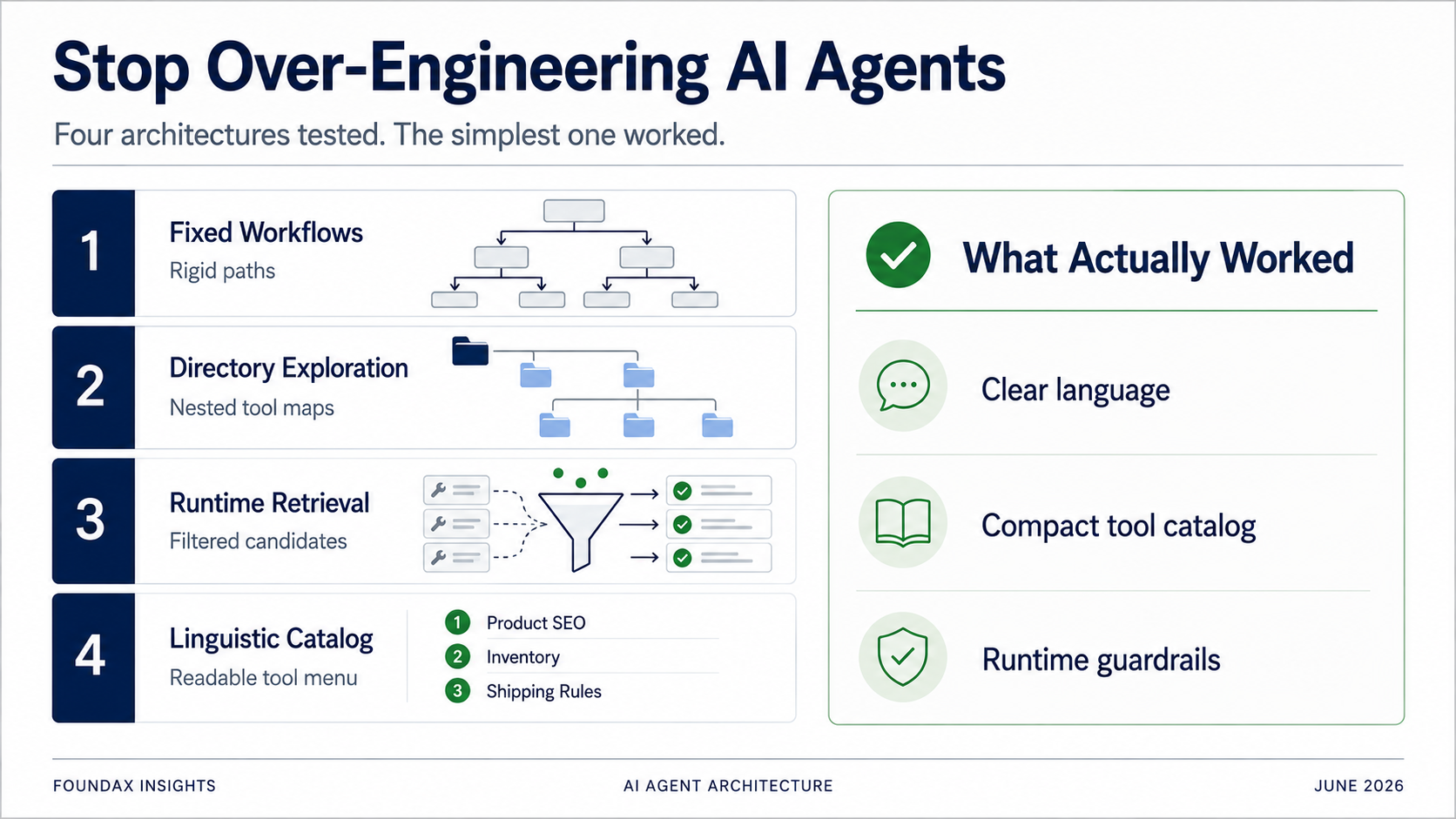
จาก fixed workflows สู่ lightweight linguistic catalog — 4 สถาปัตยกรรม Agent ที่เราลองผิดลองถูก ทุก 'optimization' ที่เราทำ จริงๆ แล้วคือการทำงานแทนโมเดลทั้งนั้น สถาปัตยกรรมที่ชนะคืออันที่หยุดพยายามฉลาด
มีช่วงเวลาหนึ่งตอนทำ Foundax Agent ที่ผมย้อนกลับมาคิดถึงบ่อยมาก
เราลองมาหมดแล้ว. Fixed workflows. Directory-based tool exploration. Skill-based tool recommendation. Runtime retrieval. Regex matching. Structured plans. Multi-round ReAct loops. ถึงขั้นเคยคิดจะใช้ embedding-based retrieval แบบจริงจังเลยด้วยซ้ำ.
แต่ละเวอร์ชันฟังดูดีบนกระดาษ.
เครื่องมือเยอะเกิน ก็ต้อง filter. โมเดลพลาดข้อมูล ก็ต้อง constrain. context ยาวเกิน ก็ต้อง retrieve. การทำงานต้องปลอดภัย ก็ต้อง proceduralize. ธุรกิจต้องการความแม่นยำ เครื่องมือชั้นล่างก็ต้อง atomic.
ถ้ามองแยกทีละข้อ ไม่มีอันไหนผิดเลย.
แต่แล้วเราก็ลองทำการทดสอบที่ง่ายที่สุด — เกือบจะหยาบที่สุดด้วยซ้ำ: บีบอัดเครื่องมือทั้งหมดให้เป็นแคตตาล็อกภาษาแบบเบาๆ โยนเข้าไปให้โมเดล แล้วปล่อยให้มันอ่านและเลือกเอง.
ผลลัพธ์ออกมาดีเกินคาด.
ผมพูดไม่ออกเลยจริงๆ.
เพราะมันหมายความว่างานออกแบบซับซ้อนส่วนใหญ่ที่เราทำมา ไม่ได้ปลดล็อกความสามารถของโมเดลเลย แต่มันคือการสมมติว่าโมเดลจะล้มเหลว แล้วห่อหุ้มมันด้วย architecture เป็นชั้นๆ เพื่อชดเชย.
บทความนี้ไม่ได้จะบอกว่า "เปิดเผยเครื่องมือทั้งหมดคือ best practice."
สิ่งที่ผมอยากจะพูดจริงๆ คือ: อันตรายที่สุดในการสร้าง business Agent ไม่ใช่การที่โมเดลไม่ฉลาดพอ — แต่คือการที่คุณเริ่มออกแบบกรงขังให้มัน ก่อนที่คุณจะทดสอบด้วยซ้ำว่ามันทำอะไรได้บ้างใน domain ของคุณ.
Foundax คือแพลตฟอร์ม ecommerce SaaS.
ดังนั้น Foundax Agent ไม่ได้จัดการกับแชททั่วไปหรือ Q&A ความรู้ทั่วไป มันจัดการกับปัญหาการดำเนินงานจริงที่พ่อค้าแม่ค้าเจอใน backend.
พ่อค้าไม่ได้พูดว่า:
"กรุณาเรียก product variant read API."
พวกเขาพูดว่า:
"ทำไมสินค้าตัวนี้ขายไม่ออก?"
"หน้าภาษาสเปนของร้านผมเรียบร้อยหรือยัง?"
"สินค้าตัวนี้ลง Google Shopping ได้ไหม?"
"ทำไมคนใส่ตะกร้าเยอะแต่ไม่จ่ายเงิน?"
"ช่วยเติม SEO ที่ขาดให้หน่อย."
คำถามเหล่านี้ฟังดูเป็น natural language แต่เบื้องหลังแต่ละคำถามคือระบบธุรกิจทั้งระบบ. สินค้า, SKU, สต็อก, ราคา, SEO, การแปลภาษา, โปรโมชัน, ค่าขนส่ง, การชำระเงิน, checkout, คำสั่งซื้อ, การคืนเงิน, GMC feed, สถานะหน้าร้าน — อะไรก็ตามในนี้ส่งผลต่อผลลัพธ์ได้.
ดังนั้นเป้าหมายของ Foundax Agent ไม่ใช่การ "ตอบเหมือนมนุษย์."
สิ่งที่มันต้องทำจริงๆ คือ: เข้าใจเจตนาที่แท้จริงของพ่อค้า, ค้นหาข้อเท็จจริงในระบบ, เลือกเครื่องมือที่ถูกต้อง, เตรียมการเขียนเมื่อจำเป็น, และดำเนินการภายใต้ข้อจำกัดของ runtime — โดยมีการขอสิทธิ์, การยืนยัน, และ readback.
ข้อมูลจากผู้ใช้คลุมเครือได้. แต่การทำงานของระบบต้องแม่นยำ.
ความตึงเครียดนี้คือจุดเริ่มต้นของทุกปัญหา architecture ที่ตามมา.
ผมเป็นคนที่มีความเป็น perfectionist ด้านวิศวกรรม.
ดังนั้นตอนเริ่มออกแบบ Foundax Agent ผมปฏิเสธเครื่องมือแบบหยาบๆ โดยสัญชาตญาณ.
เครื่องมือที่ชื่อ analyzeProductReadiness ฟังดูสะดวก แต่มันอ่าน field อะไรภายใน? ใช้เกณฑ์อะไรตัดสิน? ขอบเขต permission อยู่ตรงไหน? เขียนแล้ว readback ได้ไหม? ทุกอย่างกลายเป็นความทึบแสง.
Foundax ไม่ใช่ demo. เมื่อพ่อค้าขอให้คุณแก้ SEO คุณจะใช้เครื่องมือ black-box ไปเปลี่ยนอะไรต่ออะไรเงียบๆ ไม่ได้.
ผมจึงยืนกรานให้เครื่องมือชั้นล่างเป็น atomic:
อ่าน field พื้นฐานของสินค้า. อ่าน product variants. อ่านสต็อกและราคา. อ่าน SEO ของสินค้า. อ่านการแปลภาษาของสินค้า. อ่านการตั้งค่าขนส่ง. อ่านการตั้งค่าชำระเงิน. เขียน field ใด field หนึ่ง. เขียนเนื้อหาสำหรับ locale ใด locale หนึ่ง. สร้าง draft การแก้ไข. Readback หลังเขียน.
ทุกเครื่องมือมีหน้าที่เดียว, ชัดเจน, ไม่ทับซ้อนกัน. การทำงานแม่นยำ, permission ชัดเจน, ทดสอบง่าย.
ผมยังคิดว่าการตัดสินใจนี้ถูกต้อง.
ปัญหาจริงคืออีกอย่าง: ยิ่งเครื่องมือชั้นล่าง atomic มากเท่าไหร่ จำนวนเครื่องมือก็ยิ่งมาก. ยิ่งมีเครื่องมือมาก โมเดลก็ยิ่งเข้าใจและเลือกใช้ใน context ได้ยากขึ้น.
นั่นคือ paradox แรก.
ยิ่งเครื่องมือชั้นล่างเหมาะสมกับการทำงานของระบบเท่าไหร่ มันก็ยิ่งไม่เหมาะเป็น cognitive interface ของโมเดลมากขึ้นเท่านั้น.
Atomicity ไม่ใช่ความผิดพลาด. ความผิดพลาดคือการเอาเครื่องมือ atomic จำนวนมากไปกองตรงหน้าโมเดล แล้วคาดหวังให้มันเลือกถูกทุกครั้ง.
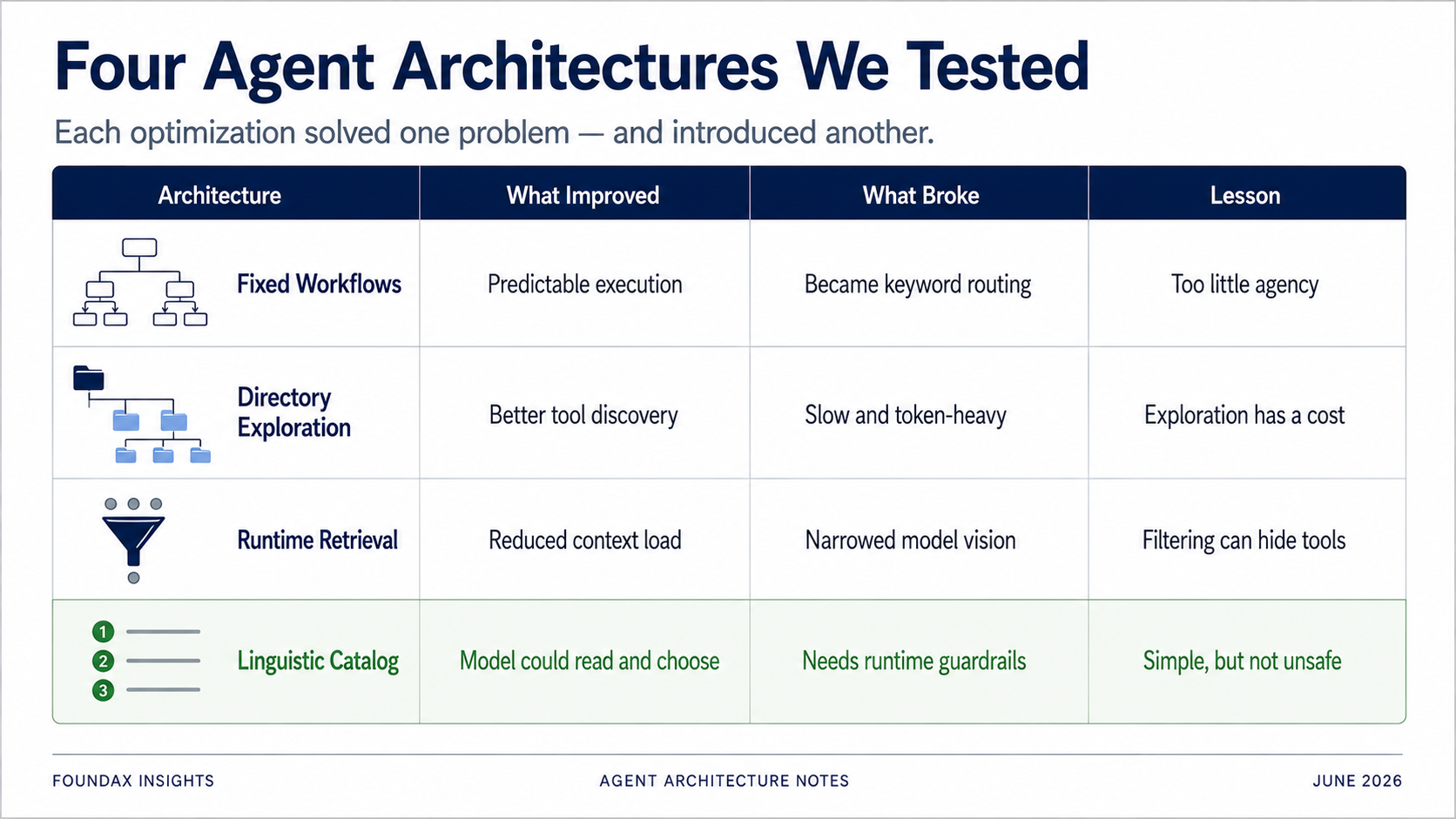
เพื่อแก้ปัญหาการเลือกเครื่องมือ เราลอง fixed workflows ก่อน.
แนวคิดนี้เป็นธรรมชาติ. ถ้างานที่พ่อค้าทำบ่อยๆ มีจำกัด ก็เขียน script ไว้ล่วงหน้าเลย.
ตรวจ SEO สินค้า. ตรวจความครอบคลุมของการแปลภาษา. ตรวจความพร้อมก่อนเปิดตัวสินค้า. วินิจฉัย conversion ต่ำ. ตรวจ GMC preflight.
หน้าที่ของโมเดลคือระบุเจตนาของผู้ใช้, จับคู่กับ workflow, แล้วส่งต่อให้ runtime ทำงานตามที่กำหนด.
วิธีนี้ดูปลอดภัย. ดูเป็น engineering.
แต่พอทดสอบจริง มันเสื่อมลงกลายเป็นระบบ keyword โง่ๆ อย่างรวดเร็ว.
การแสดงออกของผู้ใช้หลากหลายเกินไป. คนหนึ่งพูดว่า "SEO ครบหรือยัง?" อีกคนว่า "Google index หน้านี้ได้ไหม?" อีกคนว่า "ชื่อสินค้าผมผิดหรือเปล่า?" อีกคนว่า "ทำไม feed มัน error ตอนยิงแอด?"
เพื่อให้ทุก variation เข้า task ได้ คุณก็เพิ่ม keywords, aliases, rules ไปเรื่อยๆ. สุดท้ายระบบก็ไม่แม่นยำ และดูแลยากกว่าที่เคย.
ที่สำคัญกว่านั้นคือ โมเดลแทบไม่มีพื้นที่ให้ทำงานเลย. มันเป็นแค่ intent classifier. เส้นทางการวิเคราะห์, การเลือกเครื่องมือ, ลำดับการรวบรวมหลักฐาน — ทั้งหมดถูกกำหนดไว้ล่วงหน้าโดยเรา.
ตอนนั้นเองที่ผมคิดได้ว่า:
ถ้าทุก task ถูก script ไว้ใน workflow สิ่งนั้นไม่ใช่ Agent อีกต่อไป — มันคือ workflow tool ที่ใส่ชุด AI.
Fixed workflows โดยแก่นแท้แล้ว คือการแทนที่ reasoning ของโมเดลด้วย enumeration ทางธุรกิจของมนุษย์. มันทำให้ระบบควบคุมได้มากขึ้น แต่มันก็พราก Agency ออกจาก Agent.
จากนั้นเราเปลี่ยนทิศทาง.
แทนที่จะเทเครื่องมือทั้งหมดทีเดียว เราจัดระเบียบเป็น directory. โมเดลเลือก domain ธุรกิจก่อน, แล้วขยาย subdirectory, แล้วเลือกเครื่องมือเฉพาะ.
สินค้า. คำสั่งซื้อ. การชำระเงิน. ขนส่ง. โปรโมชัน. Analytics. GMC.
ใต้ "สินค้า": ข้อมูลพื้นฐาน, SKU, สต็อก, ราคา, SEO, แปลภาษา.
วิธีนี้แม่นยำกว่า fixed workflows มาก. โมเดลไม่ได้จับคู่ keywords กับเส้นทางที่กำหนดไว้ — มันกำลังสำรวจแผนที่เครื่องมือแบบมีโครงสร้าง. มันหาเครื่องมือที่ถูกต้องได้บ่อยขึ้นจริงๆ.
แต่ปัญหาชัดเจน: ความเร็ว.
ทุก task ต้อง traversal directory. คำถามง่ายๆ ก็ยังต้องผ่าน exploration chain. token consumption สูง. latency สูง.
พ่อค้าถามว่า "SEO สินค้าตัวนี้ครบไหม?" แล้ว Agent ทำตัวเหมือนกำลังเปิดคู่มือ backend เล่มหนา.
Directory exploration ไม่ได้ผิดทิศทาง. ปัญหาคือมันเปลี่ยน "การทำความเข้าใจระบบเครื่องมือ" ให้เป็นต้นทุนต่อ invocation. โมเดลต้องสำรวจระบบใหม่ตั้งแต่ต้นทุกครั้ง ซึ่งยากจะยอมรับในฐานะประสบการณ์ผลิตภัณฑ์.
ต่อไปเราสร้างอะไรที่ซับซ้อนขึ้น.
โมเดลสร้างความเข้าใจเชิงโครงสร้างของ prompt ผู้ใช้ก่อน: intent decomposition, keywords, business domain ที่เกี่ยวข้อง, และว่า task เป็น read, write, mixed, หรือ unknown.
จากนั้นแผนนี้ไปที่ runtime. runtime ใช้ skills, regex matching, และ tool metadata เพื่อเรียก candidate tools. โมเดลเลือกจาก candidates. หลังจากอ่านข้อเท็จจริง, โมเดลตัดสินใจได้ว่าจะสำรวจต่อในรอบอื่นหรือไม่.
เวอร์ชันนี้ดูเหมือน Agent Runtime ที่ mature. และมันก็ให้ความก้าวหน้าจริงๆ.
ตัวอย่างเช่น เราค้นพบว่า structured fields สามารถปรับปรุงพฤติกรรมของโมเดลได้. เพื่อป้องกันไม่ให้โมเดลคว้าเครื่องมือแรกที่ดูเกี่ยวข้องโดยไม่อ่าน candidate list ทั้งหมด เราออกแบบ field hasreadalltools — ให้โมเดลประกาศอย่างชัดเจนว่าอ่าน candidates ครบก่อนเรียก tool. นั่นช่วยได้จริง.
แต่ที่น่าสนใจกว่า: ภายหลังเราพบว่า instruction ภาษาธรรมชาติที่เขียนดีเพียงประโยคเดียว มีประสิทธิภาพกว่า structured field ที่ซับซ้อน.
ก่อนที่โมเดลจะเลือกเครื่องมือ เราเพิ่ม:
"จากเป้าหมายทางธุรกิจของผู้ใช้ ให้เลือกเครื่องมือวิเคราะห์และเขียนที่จำเป็นทั้งหมด อย่าเลือกแค่เครื่องมือแรกที่ดูเกี่ยวข้อง."
ก่อนที่โมเดลจะเตรียมตอบ เราเพิ่ม:
"อย่ารีบตอบ. พิจารณาก่อนว่าข้อเท็จจริงที่จำเป็นครบหรือยัง. ถ้ายัง ให้เลือกเครื่องมือเพิ่ม."
prompt ง่ายๆ เหล่านี้ปรับปรุงความลึกของ reasoning ของโมเดลอย่างมีนัยสำคัญ.
นี่คือการตื่นรู้ครั้งใหญ่:
LLM ไม่ใช่โปรแกรมแบบดั้งเดิม. Structured protocols มีประโยชน์ แต่โมเดลอ่านภาษาและเลียนแบบ reasoning เสมอ. บ่อยครั้ง instruction ภาษาธรรมชาติที่แม่นยำ, ตรงไปตรงมา, คลุมเครือต่ำหนึ่งประโยค ทำงานได้ดีกว่า structured field ที่ซับซ้อน.
แต่ architecture นี้ก็เผยปัญหาที่ลึกกว่า.
Runtime tool retrieval ถูกออกแบบมาเพื่อแก้ context overload และการเลือกเครื่องมือที่ไม่แม่นยำ. แต่ runtime โดยพื้นฐานแล้วคือระบบ rule.
ไม่ว่าจะเป็น regex, skills, keywords, หรือ domain filtering — มันสามารถกรองเครื่องมือที่โมเดลต้องการจริงๆ ออกไปได้ ตั้งแต่รอบแรก.
ลองนึกถึงพ่อค้าที่ถาม: "ทำไมสินค้าตัวนี้ขายไม่ออก?"
คำถามนั้นอาจเกี่ยวข้องกับ analytics. และอาจเกี่ยวข้องกับเนื้อหาสินค้า, ราคา, สต็อก, โปรโมชัน, ขนส่ง, ชำระเงิน, checkout, แหล่งที่มาของ traffic, ภูมิศาสตร์, อุปกรณ์, SEO, ความถูกต้องของ copy หน้าเพจ.
ถ้า runtime รีบจัดกลุ่มคำถามนี้เข้า domain เดียว วิสัยทัศน์ของโมเดลก็จะถูกจำกัด.
นั่นคือ paradox ที่สาม:
Runtime tool retrieval ประหยัด context — แต่มันก็กลายเป็นเพดานของวิสัยทัศน์ของโมเดลได้เช่นกัน.
เราตั้งใจจะลดภาระของโมเดล แต่กลับไปจำกัดการตัดสินใจของโมเดล.
เมื่อจำนวนเครื่องมือเพิ่มขึ้น ผมเคยคิดจะใช้ embedding-based retrieval อย่างจริงจัง.
แนวคิดนี้เป็นธรรมชาติ. user prompt → vector. tool descriptions → vectors. similarity score. Top-k ให้โมเดล.
ฟังดู standard. ฟังดู "AI-native."
แต่ยิ่งคิด ยิ่งรู้สึกว่ามันผิด.
สำหรับ ad retrieval, content recommendation, หรือการค้นหาเอกสารขนาดใหญ่ embeddings สมเหตุสมผล. candidate set มีขนาดมหาศาล และระบบดั้งเดิมไม่เข้าใจภาษาจริงๆ. คุณต้องบีบอัด semantics เป็น vectors เพื่อ approximate matching.
แต่เครื่องมือของ Foundax ไม่ใช่เอกสารที่ไม่รู้จักนับล้านในโลกเปิด. มันคือ business capabilities ที่มีจำนวนจำกัด, นับได้, อธิบายได้, บีบอัดได้ ภายในระบบของเราเอง.
และจุดแข็งที่สุดของ LLM คือการอ่านภาษา, เข้าใจภาษา, เปรียบเทียบ semantics, และตัดสินเจตนา.
แล้วทำไมต้องแปลง tool descriptions เป็น vectors แล้วใช้ similarity score มาตัดสิน — แทนที่โมเดล — ว่ามันควรเห็นอะไร?
มันเหมือนมีหนังสือที่มีสารบัญที่อ่านเข้าใจได้ง่าย. แทนที่จะอ่าน คุณ encode สารบัญเป็นตัวเลข แล้วให้ผู้อ่านตัดสินใจว่าจะอ่านบทไหนจากระยะห่างทางตัวเลข.
นั่นสมเหตุสมผลในระบบค้นหาแบบดั้งเดิม. ใน Agent ที่ native กับ LLM ผมเชื่อมากขึ้นเรื่อยๆ ว่ามันคือทางอ้อม.
สำหรับ business Agent อย่าง Foundax, ลำดับความสำคัญไม่ใช่ vector retrieval. มันคือ language compression — การบีบอัดเครื่องมือ, เอกสาร, ความสามารถ, และขอบเขต ให้เป็น linguistic context ที่ชัดเจน, แม่นยำ, ความหนาแน่นสูง, ที่โมเดลอ่านได้โดยตรง.
เราเจอปัญหาคลาสสิกอีกอย่าง: การเปิดเผยเครื่องมือหนักเกินไป.
ช่วงแรก แต่ละเครื่องมือเปิดเผยข้อมูลที่สมบูรณ์มากให้โมเดล: function name, long description, fact scope, answer boundary, excluded sources, field enums, detail level enums, argument descriptions, observation return format.
ดู rigorous.
แต่สุดท้ายผมก็ตระหนัก: โมเดลไม่จำเป็นต้องรู้ข้อมูลส่วนใหญ่พวกนี้.
ถ้าการ query จริง, field validation, permission checking, owner executor boundaries, confirmation flows, และ readback ทั้งหมดถูกจัดการโดย runtime แล้ว โมเดลไม่ควรต้องอ่าน API schema เต็มๆ ทุกครั้ง.
สิ่งที่โมเดลต้องรู้จริงๆ:
ตัวอย่างเช่น:
แค่นี้ก็พอ.
prefix "Read / Write / Search" ใน candidate list ก็เพียงพอให้โมเดลแยกแยะประเภทการกระทำ. permission จริงสำหรับ read/write, confirmation flows, owner executor boundaries — สิ่งเหล่านี้ต้องอยู่ใน runtime, บังคับใช้ตอน execution. อย่าเผา token ให้โมเดลอ่านมัน. และอย่าพึ่งพาให้โมเดลทำตามกฎด้วยความสมัครใจเด็ดขาด.
ข้อสรุปตรงนี้:
Schema มีไว้สำหรับ runtime ไม่ใช่สำหรับโมเดล. โมเดลควรเห็น linguistic capability catalog ไม่ใช่ API dictionary.
ในที่สุดเราก็ทดสอบสิ่งที่ง่ายที่สุด.
เปิดเผยเครื่องมือทั้งหมดให้โมเดลในรูปแบบคำอธิบายภาษาที่บีบอัดอย่างมาก. ให้โมเดลอ่าน. ให้โมเดลเลือก.
ผลลัพธ์ดีเกินคาด.
จริงๆ แล้ว ผลลัพธ์นี้เหมือนตบหน้าตัวเอง. เพราะทุก complex architecture ที่เราสร้างมาก่อนหน้านี้ยึดอยู่กับสมมติฐานเดียว: โมเดลจัดการกับการเห็นเครื่องมือมากเกินไปไม่ไหว ดังนั้น runtime ต้อง filter ให้.
แต่การทดสอบแสดงว่าสมมติฐานนี้ — อย่างน้อยใน context ปัจจุบันของ Foundax — ไม่ได้เป็นจริงทั้งหมด.
คำถามไม่ใช่ "เปิดเผยเครื่องมือทั้งหมดได้ไหม?" คำถามคือ "คุณกำลังเปิดเผยอะไรให้โมเดลกันแน่?"
ถ้าคุณเปิดเผยกำแพง API schema เต็มรูปแบบ — long descriptions, field enums, parameter specs — คุณจะทำให้โมเดลจมน้ำแน่. แต่ถ้าคุณเปิดเผย lightweight, clear, linguistic capability catalog โมเดลสามารถอ่านและเลือกเองได้ — และอาจทำงานได้ดีกว่า pre-filtering ของ runtime ด้วยซ้ำ.
นี่ไม่ใช่การกลับไปสู่การเปิดเผยแบบหยาบๆ ในตอนเริ่มต้น.
ตอนเริ่มต้นคือ: เท API dictionary ทั้งหมดใส่โมเดล.
ตอนสุดท้ายคือ: ยื่น compressed operations manual ให้โมเดล — lightweight, numbered, linguistic capability menu.
สองสิ่งนี้ต่างกันโดยสิ้นเชิง. อันแรกคือทะเลเครื่องมือ. อันหลังคือแผนที่ที่อ่านได้.
ขอให้เป็นรูปธรรม. ระบบของเรามี เครื่องมืออ่านและคำสั่งเขียนหลายสิบรายการ — รวมแล้วกว่าร้อย canonical tools. แต่ละ task เปิดเผยเครื่องมือให้โมเดลประมาณสิบกว่ารายการ ควบคุมด้วย exposure budget. เฟส toolselection มี context budget หลายหมื่นตัวอักษร. schema description ของแต่ละเครื่องมือประมาณหนึ่งพันกว่าตัวอักษร (ไม่กี่ร้อย tokens). การเปิดเผยเครื่องมือสิบกว่ารายการหมายถึงประมาณหนึ่งหมื่นถึงสองหมื่นตัวอักษร — ประมาณสี่ถึงห้าพัน tokens. จัดการได้สบาย.
แต่ถ้าเราเปิดเผยเครื่องมือทั้งหมดพร้อม full schema? นั่นคือเกือบสองแสนตัวอักษร — ประมาณห้าหมื่น tokens. นั่นไม่ไหวจริงๆ.
key insight: runtime จัดหา compact, numbered tool signatures จาก canonical registry. โมเดลอ่าน index card ไม่ใช่ encyclopedia entry.
มันง่ายที่จะตีความผิด.
"ให้โมเดลอ่านและเลือกเอง" หมายความว่า runtime ไม่สำคัญหรือ?
ตรงกันข้ามอย่างสิ้นเชิง.
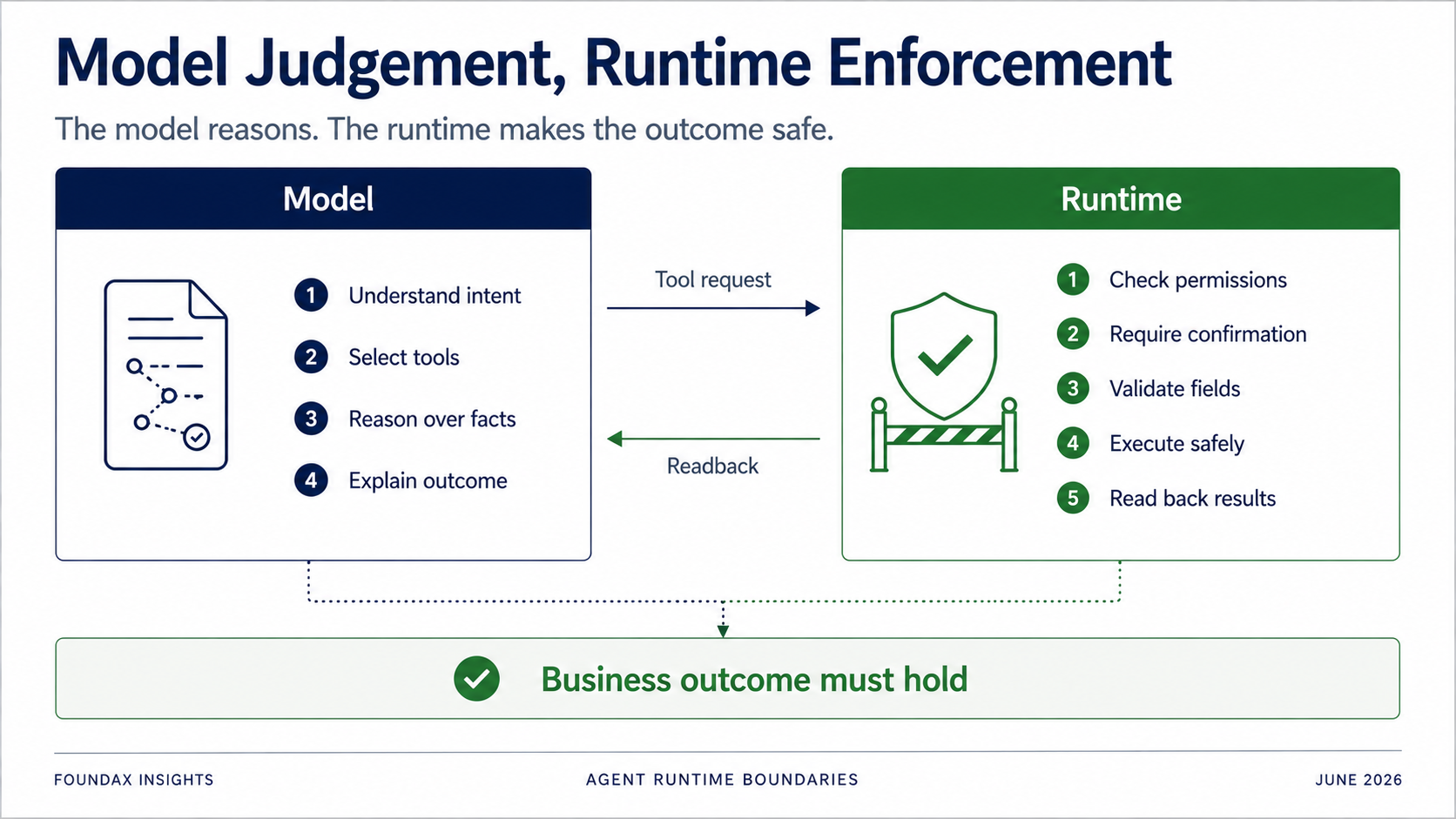
Runtime ยังสำคัญอย่างยิ่ง — มันแค่ไม่ควรพยายามคิดแทนโมเดลก่อนเวลาอันควร.
โมเดลรับผิดชอบ: การเข้าใจ, การตัดสิน, การเลือก, และการอธิบาย.
Runtime รับผิดชอบ: permissions, confirmation, field validation, owner executor boundaries, การทำงานจริง, และ readback.
โดยเฉพาะสำหรับ write operations: คุณห้ามพึ่งพาให้โมเดลทำตามกฎด้วยความสมัครใจเด็ดขาด.
โมเดลพูดได้ว่า "ผมอยากอัปเดต SEO ของสินค้าตัวนี้."
แต่ runtime ต้องตัดสินว่า: ผู้ใช้ปัจจุบันมี permission ไหม? การกระทำนี้ต้องยืนยันไหม? ควรสร้างแค่ draft ก่อนหรือไม่? field อยู่ใน allowlist ไหม? object เป็นของพ่อค้าปัจจุบันหรือไม่? การเขียนสำเร็จจริงไหม? หลังจาก readback, business state ตรงกับเป้าหมายจริงหรือไม่?
เป้าหมายของ Agent ไม่ใช่การพิสูจน์ว่า tool call สำเร็จ. มันคือการพิสูจน์ว่า business outcome เกิดขึ้นจริง.
ขอบเขตนี้สำคัญอย่างยิ่ง. ไม่ใช่ทุกอย่างไปที่โมเดล และไม่ใช่ทุกอย่างไปที่ runtime. คำถามที่แท้จริงคือการแบ่งงาน.
บทเรียนที่ใหญ่ที่สุดจากการเดินทางนี้ไม่ใช่ว่า 4.0 เป็น architecture ที่ดีที่สุด.
แต่มันคือการที่การสร้าง Agent ทำให้คุณถูกพัดพาไปด้วยห่วงโซ่ของความกังวลทางวิศวกรรมที่แท้จริง ได้อย่างอันตราย.
กังวลว่า task ความถี่สูงจะไม่เสถียรเมื่อโมเดล improvise ทุกครั้ง? → สร้าง fixed workflows.
กังวลว่า context ยาวเกินไปและโมเดล suffer attention dilution? → สร้าง directory exploration.
กังวลว่าจำนวนเครื่องมือที่เพิ่มขึ้นทำให้ tokens พุ่ง? → สร้าง runtime retrieval.
กังวลว่า keyword-based retrieval เปราะบางเกินไปสำหรับงานข้ามภาษาและข้าม domain? → คิดถึง embeddings, scoring, reranking.
กังวลว่าโมเดลเลือกเครื่องมือโดยไม่อ่าน list ทั้งหมด หรือตอบก่อนข้อเท็จจริงครบ? → เพิ่ม structured constraint fields.
ความกังวลเหล่านี้ไม่ใช่เรื่องสมมติ. มันสอดคล้องกับปัญหาจริงทั้งหมด.
เราแค่พบ — แบบเจ็บตัว — ว่าหลายโซลูชันแก้ปัญหาหนึ่ง แต่สร้างอีกปัญหาหนึ่ง.
Fixed workflows เพิ่มเสถียรภาพแต่ปิดกั้น reasoning ของโมเดล. Directory exploration แม่นยำแต่ช้าและกิน token. Runtime retrieval ประหยัด context แต่อาจบล็อกเครื่องมือที่โมเดลต้องการ. Embeddings ดูฉลาดแต่สำหรับการเลือกเครื่องมือแบบ LLM-native อาจเป็นทางอ้อม. Structured fields constrain โมเดลได้ แต่บางครั้ง prompt ภาษาธรรมชาติทำงานได้ดีกว่า.
และการตระหนักรู้ที่สำคัญกว่า:
ปัญหาเหล่านี้มีจริง แต่มันไม่จำเป็นต้องรุนแรงเท่ากันในโปรเจกต์ของคุณ.
context ยาวทำให้เกิด attention dilution ใน use case ของคุณจริงหรือ? ทดสอบ. จำนวนเครื่องมือทำให้ต้นทุน token รับไม่ได้จริงหรือ? ทดสอบ. การเปิดเผยเครื่องมือทั้งหมดทำให้โมเดลขี้เกียจ, พึ่งพาเส้นทาง, หรือผิดพลาดจริงหรือ? ทดสอบ. runtime retrieval บล็อกเครื่องมือที่โมเดลต้องการจริงหรือ? ทดสอบด้วย.
ความผิดพลาดที่ง่ายที่สุดใน Agent architecture คือการปฏิบัติกับ "ปัญหาที่มีอยู่จริงในโปรเจกต์ของคนอื่น" ว่าเป็น "ปัญหาที่มีอยู่แน่นอนในโปรเจกต์ของคุณ."
ดังนั้นขั้นตอนแรกของการสร้าง Agent ไม่ใช่การออกแบบ architecture ที่ซับซ้อนเพื่อป้องกันทุกปัญหาที่อาจเกิดขึ้น. แต่มันคือการทดสอบ:
โมเดลเข้าใจอะไรได้จริงใน domain ของคุณ? มันอ่าน tool descriptions ของคุณได้ไหม? มันเลือกเครื่องมือเองได้ไหม? มันพลาดข้อเท็จจริงตรงไหน? การตัดสินใจไหนที่คุณส่งต่อให้มันได้? อะไรที่ runtime ต้องบังคับใช้? การกระทำไหนต้องขอ confirmation จากผู้ใช้? ผลลัพธ์ไหนต้อง readback?
คำตอบของคำถามเหล่านี้ — ไม่ใช่ reference architecture จาก blog post — ควรเป็นตัวกำหนดการออกแบบ Agent ของคุณ.
สำหรับ Foundax ตอนนี้เรามีความชัดเจน: การดำเนินงาน ecommerce เป็น domain ที่โมเดลรู้ดี. conversion funnels, product pages, pricing, shipping, promotions, payment, traffic quality, SEO — กรอบการวิเคราะห์เหล่านี้ปรากฏนับครั้งไม่ถ้วนใน training data. โมเดลไม่ได้ขาดสัญชาตญาณการวิเคราะห์ธุรกิจ. สิ่งที่มันขาดคือความรู้เกี่ยวกับระบบเฉพาะของ Foundax: มันอ่านข้อเท็จจริงอะไรได้บ้าง, มันเตรียมเขียนอะไรได้บ้าง, การกระทำไหนที่ runtime ต้องเป็นเจ้าของ, ผลลัพธ์ไหนต้อง readback.
ดังนั้น Foundax Agent ไม่ใช่การสอนโมเดลให้วิเคราะห์ ecommerce. มันคือการยื่น business capabilities ของ Foundax ให้โมเดลในภาษาที่มันอ่านเข้าใจ.
ขั้นตอนแรกของการสร้าง business Agent ไม่ใช่การออกแบบ architecture ที่สมบูรณ์แบบ. มันคือการทดสอบว่าคุณไว้ใจโมเดลได้มากแค่ไหน.
เราไม่ใช่คนเดียวที่มาถึงข้อสรุปเหล่านี้.
ในเดือนธันวาคม 2024, Anthropic เผยแพร่คู่มือ "Building Effective Agents". ข้อความหลัก: ความเรียบง่ายชนะ. เริ่มจากโซลูชันที่ง่ายที่สุด. augmented LLM ที่เข้าถึงเครื่องมืออาจเป็นทั้งหมดที่คุณต้องการ. ตอนที่อ่านครั้งแรก ผมพยักหน้า. หลังจากผ่านสิ่งที่เล่ามาทั้งหมดข้างต้น ผมเข้าใจมันอย่างลึกซึ้ง.
จากนั้นในเดือนพฤษภาคม 2026, LangChain จัดงาน Interrupt conference พร้อมการเปลี่ยนทิศทางที่สำคัญ: ธีมเปลี่ยนจาก 'agents ขึ้น production ได้ไหม' เป็น 'enterprise scale และ production operations.' คอขวดที่แท้จริง ตามที่เนื้อหาของพวกเขาเน้น ไม่ใช่การเขียน agents — แต่คือการจัดการพวกมันใน production ที่ scale.
งานวิจัยจำนวนมากขึ้นเรื่อยๆ ตอกย้ำทิศทางนี้. งานของ Google DeepMind ปี 2025 เกี่ยวกับข้อจำกัดของ embedding แสดงให้เห็นทางคณิตศาสตร์ว่า fixed-size vector embeddings สูญเสียข้อมูลเชิงโครงสร้างและความสัมพันธ์เมื่อ scale ใหญ่ขึ้น — เกี่ยวข้องโดยตรงกับใครก็ตามที่กำลังพิจารณา embedding-based tool retrieval. แนวคิด "context engineering" ของ Neo4j โต้แย้งว่า AI ที่น่าเชื่อถือมาจาก architecture ไม่ใช่ clever prompt phrasing.
ประสบการณ์ของเราสอดคล้องกับทิศทางที่เราเห็นทั่วอุตสาหกรรม: simple/composable patterns ของ Anthropic, การเน้น production operations มากกว่า framework abstractions ของ LangChain. scaffolding สำเร็จรูปน้อยลง, ความสามารถโดยตรงของโมเดลมากขึ้น — แต่ต้อง validated กับการใช้งานจริงเสมอ ไม่ใช่รับมาเป็น doctrine. pre-filtering น้อยลง, model judgment มากขึ้น. คำถามไม่ใช่ "เราจะสร้าง architecture ที่สมบูรณ์แบบล้อมรอบโมเดลได้อย่างไร?" แต่มันคือ "เราจะให้สิ่งที่โมเดลต้องการจริงๆ แล้วหลีกทางให้มันได้อย่างไร?"
นี่ไม่ได้ทำให้ข้อสรุปของ Foundax เป็น universal. ธุรกิจที่แตกต่าง, โมเดลที่แตกต่าง, tool surfaces ที่แตกต่าง จะได้คำตอบที่แตกต่าง. สิ่งที่เป็น universal คือวิธีการ: ทดสอบก่อน, ออกแบบทีหลัง.
Q: นี่หมายความว่าผมควรเปิดเผยเครื่องมือทั้งหมดให้โมเดลเสมอหรือ?
ไม่. มันขึ้นอยู่กับจำนวนเครื่องมือของคุณ, โมเดลของคุณ, context budget ของคุณ, และ domain ของคุณ. ประเด็นไม่ใช่ "เปิดเผยทุกอย่างเสมอ." ประเด็นคือ: ทดสอบก่อนที่จะ filter. อย่าสมมติว่าโมเดลจัดการไม่ได้ — ตรวจสอบ. ในกรณีของเรา, compressed tool signatures ประมาณสิบกว่ารายการต่อ task จัดการได้และมีประสิทธิภาพ. ตัวเลขของคุณอาจต่างออกไป.
Q: เมื่อไหร่ที่ผมควรใช้ fixed workflows แทน?
เมื่อ task มีความ deterministic อย่างแท้จริง, ความเสี่ยงของความผิดพลาดร้ายแรงมาก, และความรู้พื้นฐานของโมเดลใน domain นั้นอ่อนแอ. Workflows ไม่ได้ผิด — มันผิดเมื่อมันแทนที่ reasoning ที่โมเดลสามารถทำได้. ใช้สำหรับ safety guardrails และ deterministic post-processing ไม่ใช่เป็นสิ่งทดแทน model judgment.
Q: linguistic catalog กับ API schema ต่างกันอย่างไร?
linguistic catalog บอกโมเดลว่าเครื่องมือทำอะไรได้ ในภาษาธรรมชาติที่บีบอัด — เช่น "Read: [12] Product Variants — SKU / ราคา / สต็อก / สถานะความพร้อมจำหน่าย." API schema บอกโมเดลว่าจะเรียกเครื่องมืออย่างไร พร้อม parameter specs, enums, และ constraints เต็มรูปแบบ. โมเดลต้องการ capabilities menu. Runtime ต้องการ technical manual. การผสมสองสิ่งนี้เข้าด้วยกันเป็นหนึ่งในความผิดพลาดที่แพงที่สุดที่คุณทำได้.
Q: คุณตัดสินใจอย่างไรว่าอะไรไปที่โมเดล vs. runtime?
heuristic ที่ดี: โมเดลจัดการ understanding, judgment, selection, และ explanation. Runtime จัดการ permission, execution, confirmation, validation, และ readback. ถ้าคุณกำลังขอให้โมเดล enforce rules คุณอยู่ผิดข้างของเส้นแบ่ง. โมเดลเสนอ; runtime ตัดสินและดำเนินการ.
Q: แล้วเรื่องต้นทุนล่ะ? การเปิดเผยเครื่องมือมากขึ้นไม่เพิ่ม token usage หรือ?
ในกรณีของเรา, compressed linguistic catalog ถูกกว่าจริงๆ เมื่อเทียบกับ multi-round directory exploration หรือ retrieval chains. แต่ละรายการเครื่องมือประมาณหนึ่งพันกว่าตัวอักษร. ด้วยเครื่องมือประมาณสิบกว่ารายการต่อ task, รวมประมาณหนึ่งหมื่นถึงสองหมื่นกว่าตัวอักษร — ประมาณสี่ถึงห้าพัน tokens. เทียบกับหลายรอบของ intent decomposition, retrieval, candidate review, และ re-selection. วิธีการที่ง่ายกว่ามักจะมีประสิทธิภาพด้าน token มากกว่า ไม่ใช่น้อยกว่า.
Q: ข้อมูลเชิงลึกเดียวที่สำคัญที่สุดจากกระบวนการนี้คืออะไร?
คือการที่ "การช่วยโมเดล" กับ "การ constrain โมเดล" มองดูเหมือนกันจากมุมมองของนักออกแบบ แต่มีผลตรงข้ามกับระบบ. ทุก architecture ที่เราสร้างมีเจตนาเพื่อช่วย. ส่วนใหญ่จบลงที่การ constrain. ความแตกต่างชัดเจนผ่านการทดสอบเท่านั้น. ถ้าคุณจะเอาสิ่งเดียวจากบทความนี้ ให้เป็นสิ่งนี้: ทดสอบว่าโมเดลของคุณทำอะไรได้จริง ก่อนที่คุณจะเริ่มออกแบบ architecture เพื่อชดเชยสิ่งที่คุณสมมติว่ามันทำไม่ได้.