エージェント型コマースにおけるDTCサイトとマーケットプレイス
マーケットプレイスを使いながら、商品データ、顧客接点、コンテンツ、測定をDTCサイトにも蓄積するための実務ガイドです。
続きを読む
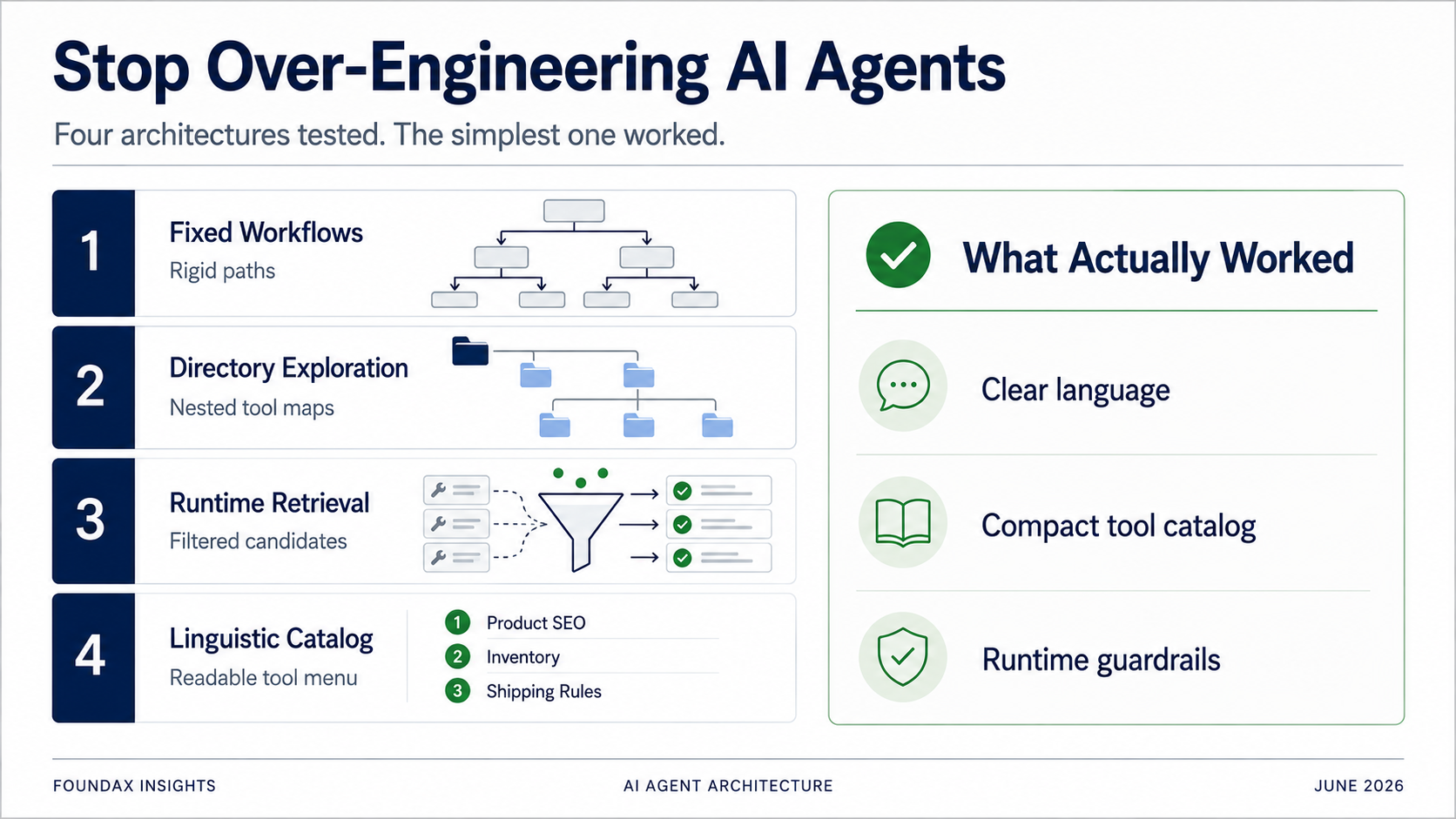
FoundaxのAI Agentは4世代のアーキテクチャを経た——固定workflowからディレクトリ探索、runtime検索を経て、最終的に軽量な言語化能力カタログへと回帰した。あらゆる「最適化」は、実のところモデルが本来できる判断を我々が代行していたにすぎない。これが我々の支払った学費のすべてである。
Foundax Agentを開発している過程で、いまだに思い返すたびに苦笑いしてしまう瞬間がある。
我々は実にさまざまなアーキテクチャを試した。固定workflow。ディレクトリ型ツール探索。スキルベースのツール推薦。runtimeによる検索取得。正規表現マッチング。構造化プラン。複数ラウンドのReActループ。一時期は、embeddingベースのツール検索を真剣に検討したことさえある。
どのバージョンも、理屈の上では筋が通っていた。
ツールが多すぎるからフィルタリングが必要だ。モデルが見落とすから制約をかけなければ。コンテキストが長すぎるから検索で絞り込もう。実行は安全でなければならないから手順化しよう。ビジネスの正確性を担保するには、ボトム層のツールをアトミックにしなければ。
個別に見れば、これらの判断のどれも間違ってはいなかった。
だが最終的に、我々は最もシンプルで——ほとんど乱暴とも言える——テストを実行した。すべてのツールを軽量な「言語化カタログ」に圧縮し、そのままモデルに渡して、自分で読んで自分で選ばせたのだ。
結果は驚くほど良かった。
正直、言葉を失った。
なぜなら、それまでの複雑な設計のほとんどは、モデルの能力を解放するものではなく、「モデルはどうせ失敗する」と先回りして仮定し、アーキテクチャの層で何重にも包み込んでいたにすぎなかったからだ。
この記事は「全ツールを露出するのがベストプラクティスだ」と言いたいわけではない。
本当に言いたいのはこういうことだ:ビジネスAgentを構築するときに最も危険なのは、モデルが十分に賢くないことではない。自分のドメインでモデルが実際にどこまでできるのかをテストする前に、モデルのために檻を設計し始めてしまうことだ。
FoundaxはEコマースSaaSプラットフォームである。
したがって、Foundax Agentが扱うのは雑談でも一般的な知識Q&Aでもない。マーチャントが管理画面で実際に直面する、リアルな運営上の問題だ。
マーチャントはこうは言わない:
「商品バリアント読み取りAPIを呼び出してください。」
彼らが言うのはこうだ:
「なぜこの商品は売れていないのか?」
「スペイン語のページはもう設定できている?」
「この商品はGoogle Shoppingに出せる?」
「カートに入れる人は多いのに、なぜ支払いまで進まないのか?」
「足りていないSEOを埋めてくれ。」
これらの質問は自然言語のように聞こえるが、その背後には一整套のビジネスシステムが存在する。商品、SKU、在庫、価格、SEO、翻訳、プロモーション、配送、決済、チェックアウト、注文、返金、GMCフィード、ストアフロントの表示状態——これらのどれか一つが結果に影響しうる。
だからFoundax Agentの目標は「人間らしく応答すること」ではない。
それが実際にやるべきことは:マーチャントの真の意図を理解し、システム内の対応する事実を見つけ、適切なツールを選び、必要に応じて書き込みを準備し、runtimeの制約の下で権限・確認・readbackの規律に従って実行すること。
ユーザーの入力は曖昧でよい。しかしシステムの実行は正確でなければならない。
この緊張関係こそが、以降のすべてのアーキテクチャ上の葛藤の出発点である。
自分にはエンジニアリングの完璧主義的な性分がある。
だからFoundax Agentを設計し始めたとき、大雑把なツールは本能的に受け入れられなかった。
たとえば analyzeProductReadiness というツールがあるとしよう。一見便利に思える。だが、内部でどのフィールドを読んでいるのか?どんな判断基準を使っているのか?権限の境界はどこにあるのか?書き込み後にreadbackできるのか?——これらがすべて不透明になる。
Foundaxはデモではない。マーチャントに「SEOを修正してほしい」と言われて、ブラックボックスのツールが裏で勝手に変更を加えるようなことは許されない。
だから私はボトム層のツールをアトミックにすることを固持した:
商品の基本フィールドを読む。商品バリアントを読む。在庫と価格を読む。商品SEOを読む。商品翻訳を読む。配送設定を読む。決済設定を読む。特定のフィールドを書く。特定のロケールのコンテンツを書く。修正ドラフトを生成する。書き込み後にreadbackする。
すべてのツールは単一目的で、クリーンで、重複しない。正確な実行、明確な権限、テストの容易さ。
この判断は今でも正しかったと思っている。
本当の問題は別のところにあった:ボトム層のツールをアトミックにすればするほど、ツールの数は増える。ツールの数が増えれば増えるほど、モデルがコンテキストの中でそれらを理解し選択することが難しくなる。
これが私が遭遇した最初のパラドックスだ。
ボトム層のツールがシステム実行に適せば適すほど、モデルの認知的インターフェースとしては不適切になっていく。
アトミック化が間違いだったわけではない。間違いは、アトミックなツールの山をそのままモデルの前に放り出して、毎回安定して正しく選んでくれると期待したことだ。
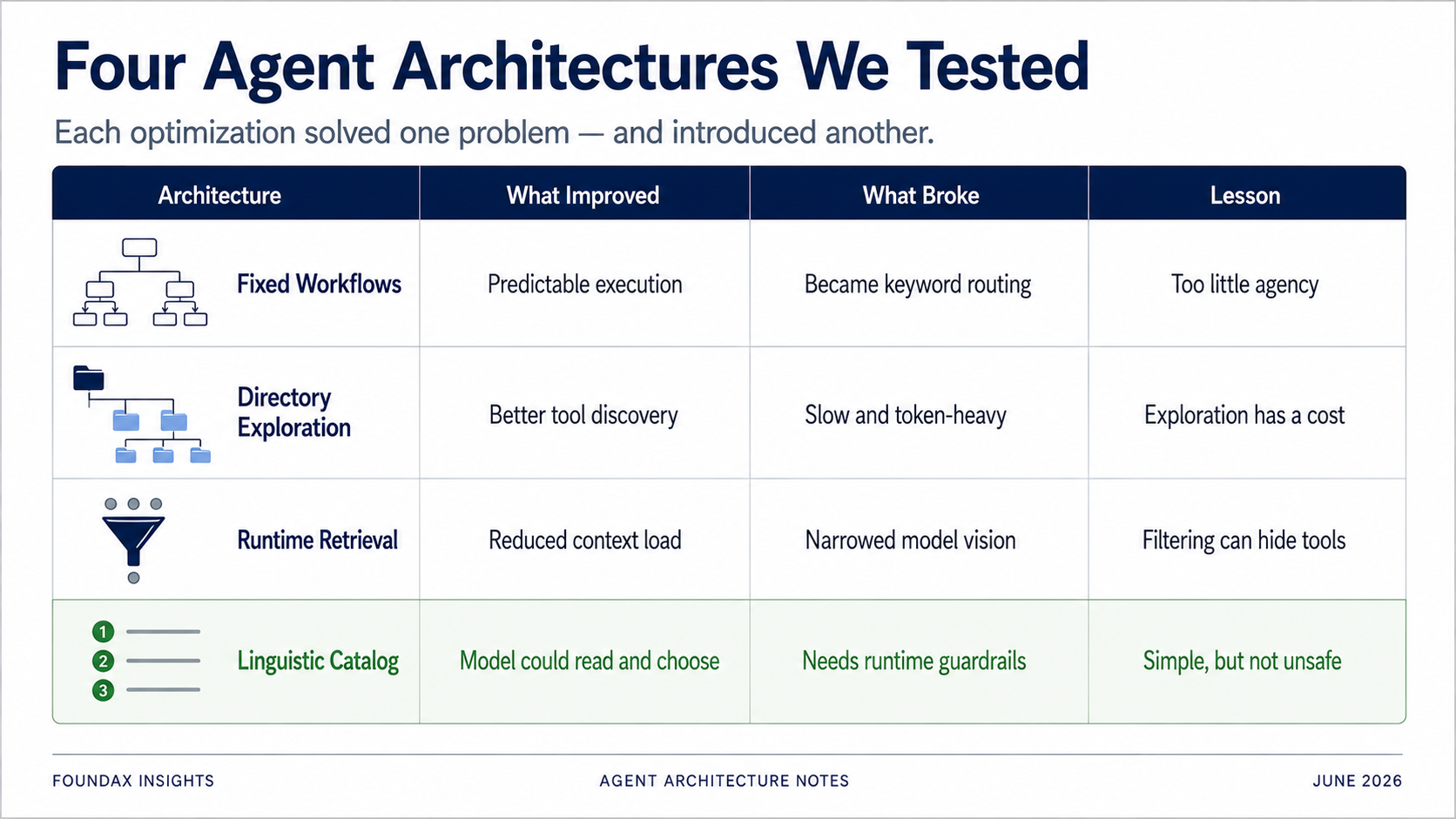
ツール選択の問題を解決するために、我々が最初に試したのは固定workflowだった。
これはごく自然な発想だ。マーチャントの高頻度タスクは有限なのだから、よくあるタスクを事前にスクリプト化しておけばいい。
たとえば:商品SEOチェック。翻訳カバレッジチェック。商品ローンチレディネスチェック。低コンバージョン診断。GMCレディネスチェック。
モデルの役割はユーザーの意図を識別し、該当するworkflowに紐付け、その後はruntimeが固定的に実行する。
この方式は安全に見えた。エンジニアリング的にも筋が通っているように見えた。
しかしテストを重ねるうちに、これがすぐに間抜けなキーワードシステムへと退化することが明らかになった。
ユーザーの表現はあまりに多様だからだ。同じ「商品SEOをチェックしたい」という意図でも、「SEOは全部揃ってる?」と言う人もいれば、「このページはGoogleにインデックスされる?」と言う人もいれば、「商品タイトルをミスったかも」と言う人もいれば、「広告を出すたびにフィードがエラーになるのはなぜ?」と言う人もいる。
すべてのバリエーションをタスクにヒットさせるために、キーワード、エイリアス、ルールを追加し続けることになる。最終的に、システムは精度を失い、保守はかつてないほど困難になる。
もっと重要なのは、モデルにほとんど裁量の余地がなかったことだ。モデルは単なる意図分類器にすぎなかった。実際の分析パス、ツール選択、証拠収集の順序——すべて我々があらかじめ決めていた。
そのとき、はたと気づいた:
すべてのタスクが事前にworkflow化されているなら、それはもはやAgentではない——AIの衣を着たworkflowツールだ。
固定workflowの本質は、モデルの推論を人間のビジネス列挙で置き換えることだ。システムはより制御しやすくなるが、AgentからはAgencyが剥奪される。
次に方向転換した。
すべてのツールを一度に渡すのではなく、ディレクトリに整理する。モデルはまずビジネスドメインを選び、次にサブディレクトリを展開し、その後に特定のツールを選択する。
商品。注文。決済。配送。プロモーション。分析。GMC。
「商品」の下には:基本情報、SKU、在庫、価格、SEO、翻訳。
これは固定workflowよりはるかに正確だった。モデルはキーワードを事前定義されたパスにマッチングしているのではなく、構造化されたツールマップを探索していた。実際に、正しいツールを見つける頻度は明らかに向上した。
しかし問題は明白だった:速度だ。
すべてのタスクがディレクトリの走査を必要とした。単純な質問でさえ、探索チェインを経由しなければならない。トークン消費は多く、レイテンシは高かった。
マーチャントが「この商品のSEOは揃ってますか?」と尋ねると、Agentは分厚い管理マニュアルを一枚一枚めくっているかのように振る舞う。
ディレクトリ探索は方向性として間違ってはいなかった。問題は、それが「ツール体系の理解」を呼び出しごとのコストに変えてしまったことだ。モデルは毎回ゼロからシステムを再探索しなければならず、これはプロダクト体験として受け入れがたい。
次に、より洗練されたものを構築した。
モデルはまず、ユーザープロンプトの構造化された理解を生成する:意図の分解、キーワード、関連するビジネスドメイン、タスクが読み取り・書き込み・混合・不明のいずれであるか。
次にこのプランがruntimeに渡される。runtimeはスキル、正規表現マッチング、ツールメタデータを使って候補ツールを検索する。モデルは候補の中から選択する。事実を読み取った後、モデルは別のラウンドで探索を続けるかどうかを判断できる。
このバージョンは成熟したAgent Runtimeのように見えた。そして実際にいくつかの本物の進歩をもたらした。
たとえば、構造化フィールドがモデルの振る舞いを改善できることを発見した。モデルが候補リストを全部読まずに最初の「それっぽい」ツールに飛びつくのを防ぐため、hasreadalltools のようなフィールドを設計し——ツール呼び出しの前にすべての候補を読み終えたかどうかを明示的に宣言するようモデルに求めた。これは確かに効果があった。
しかしもっと興味深かったのは、後に我々が発見したことだ:単一の、よく書かれた自然言語の指示が、複雑な構造化フィールドよりも効果的な場合がある。
モデルがツールを選択する前に、こう追加した:
「ユーザーのビジネス目標に基づき、必要な分析ツールと書き込みツールをすべて選択すること。最初にそれっぽく見えるツールだけを選んではいけない。」
モデルが回答を出力する準備をする前に、こう追加した:
「急いで答えを出すな。まず必要な事実が揃っているか判断せよ。揃っていなければ、ツールの選択を続けよ。」
これらのシンプルなプロンプトが、モデルの推論の深さを大幅に改善した。
これは大きな警鐘だった:
LLMは従来のプログラムではない。構造化プロトコルは有用だが、モデルは常に言語を読み、推論を模倣している。往々にして、一つのはっきりとした、直接的で、曖昧さの少ない自然言語の指示が、複雑な構造化フィールドよりも効果的に機能する。
しかしこのアーキテクチャは、より深い問題も露わにした。
runtimeによるツール検索は、コンテキストの過負荷と不正確なツール選択を解決するために設計された。しかしruntimeとは、本質的にはルールシステムである。
正規表現であれ、スキルであれ、キーワードであれ、ドメインフィルタリングであれ——最初のパスで、モデルが本当に必要とするツールを除外してしまう可能性がある。
マーチャントが「なぜこの商品は売れないのか?」と尋ねる場合を考えてみよう。
この質問は分析に関わるかもしれない。同時に、商品コンテンツ、価格、在庫、プロモーション、配送、決済、チェックアウト、トラフィックソース、地域、デバイス、SEO、ページコピーの真正性にも関わるかもしれない。
runtimeがあまりに性急に単一ドメインに振り分けてしまうと、モデルの視野は制限される。
これが第三のパラドックスだ:
runtimeによるツール検索はコンテキストを節約する——しかし、それは同時にモデルの視野の天井にもなりうる。
我々はモデルの負担を軽減しようとして、結果的にモデルの判断を制限しかねない状況に至った。
ツール数が増えるにつれて、私はembeddingベースの検索を真剣に検討した。
発想は自然だ。ユーザープロンプト → ベクトル。ツール説明 → ベクトル。類似度スコア。Top-kをモデルに渡す。
標準的に聞こえる。「AIネイティブ」に聞こえる。
しかし考えれば考えるほど、これは間違っているように感じられた。
広告検索、コンテンツ推薦、大規模文書検索であれば、embeddingは理にかなっている。候補セットは膨大で、従来のシステムは本当の意味で言語を理解できない。意味をベクトルに圧縮して近似マッチングする必要がある。
しかしFoundaxのツールは、オープンワールドの何百万もの未知の文書ではない。それらは有限で、列挙可能で、記述可能で、圧縮可能な、我々自身のシステム内のビジネスケイパビリティだ。
そしてLLMの最大の強みは、まさに言語を読み、言語を理解し、意味を比較し、意図を判断することにある。
ならばなぜ、ツール説明をベクトルに変換し、類似度スコアを使って——モデルに代わって——モデルが何を見るべきかを決めるのか?
それは、完璧に読める目次がある本を前にして、目次を数字にエンコードし、読者に数値的距離でどの章を読むべきか判断させるようなものだ。
従来の検索システムではそれは理にかなっている。LLMネイティブのAgentにおいては、私はそれが回り道だとますます確信している。
FoundaxのようなビジネスAgentにとって、優先順位はベクトル検索ではない。それは言語圧縮だ——ツール、文書、ケイパビリティ、境界を、モデルが直接読める、明確で正確で高密度な言語的コンテキストに圧縮すること。
我々は別の古典的な問題にも直面した:ツールの露出が重すぎるのだ。
初期には、各ツールが極めて完全な情報をモデルに露出していた:関数名、長い説明、ファクトスコープ、回答境界、除外ソース、フィールド列挙、詳細度列挙、引数説明、オブザベーションの戻り値形式。
厳密に見える。
しかし私は最終的に気づいた:モデルはこれらのほとんどを知る必要がない。
実際のクエリ実行、フィールド検証、権限チェック、オーナーエグゼキューター境界、確認フロー、readbackがすべてruntimeによって処理されるのであれば、モデルが毎回APIの完全なスキーマを読むビジネス上の理由はない。
モデルが実際に知る必要があるのは:
たとえば:
これで十分だ。
候補リストにおける「Read / Write / Search」の接頭辞だけで、モデルがアクションタイプを区別するにはすでに十分である。実際の読み書き権限、確認フロー、オーナーエグゼキューター境界——これらはruntimeの内部にとどめ、実行時に強制されなければならない。モデルに読ませるためにトークンを消費するな。そして絶対に、モデルが自主的に従うことに依存するな。
ここでの結論:
スキーマはruntimeのためのものであり、モデルのためのものではない。モデルが見るべきは言語化されたケイパビリティカタログであり、API辞書ではない。
ついに、最もシンプルなテストを実行した。
すべてのツールを極限まで圧縮した言語的記述としてモデルに露出する。モデルに読ませる。モデルに選ばせる。
結果は驚くほど良かった。
正直に言って、この結果は顔を張られたような気分だった。なぜなら、それまでに構築したすべての複雑なアーキテクチャは、一つの前提に固定されていたからだ:モデルはあまりに多くのツールを見せられると処理できない、だからruntimeがフィルタリングしなければならない。
しかしテストが示したのは、この前提が——少なくともFoundaxの現在のコンテキストにおいては——完全には成り立たないということだ。
問題は「すべてのツールを露出できるか」ではない。問題は「モデルにいったい何を露出しているのか」だ。
もし完全なAPIスキーマの壁——長い説明、フィールド列挙、パラメータ仕様——を露出しているなら、確実にモデルを溺れさせるだろう。しかし、軽量で明確な言語化ケイパビリティカタログを露出しているなら、モデルは自分で読んで自分で選択できる——そしてruntimeの事前フィルタリングよりも良い仕事をする可能性がある。
これは初期の粗野な全露出への回帰ではない。
初期のものは:完全なAPI辞書をモデルに投げつけることだった。
最終形は:圧縮された操作マニュアルをモデルに手渡すことだ——軽量で、番号付きの、言語化されたケイパビリティメニュー。
これらはまったく異なるものだ。前者はツールの海。後者は読める地図。
具体的に言おう。我々のシステムには数十の読み取りツールと書き込みコマンド——合計で百を超える正規ツールが存在する。各タスクで露出されるツールは多くても十数個で、露出予算によって制御されている。toolselectionフェーズのコンテキストバジェットは数万字程度。各ツールのスキーマ記述は千数百文字(数百トークン)程度。十数個のツールを露出すると、おおよそ一万〜二万字——約四千〜五千トークン。十分に管理可能だ。
しかし、すべてのツールをフルスキーマで露出したら?それは二十万字近く——約五万トークン。それは本当に収まらない。
重要な洞察:runtimeは正規レジストリからコンパクトで番号付きのツールシグネチャを提供する。モデルが読むのは百科事典の項目ではなく、インデックスカードだ。
これは誤解されやすい。
「モデルに読ませて選ばせる」ということは、runtimeが重要ではないということか?
まったく逆だ。
runtimeは依然として決定的に重要だ——ただ、時期尚早にモデルの代わりに考えようとすべきではないというだけだ。
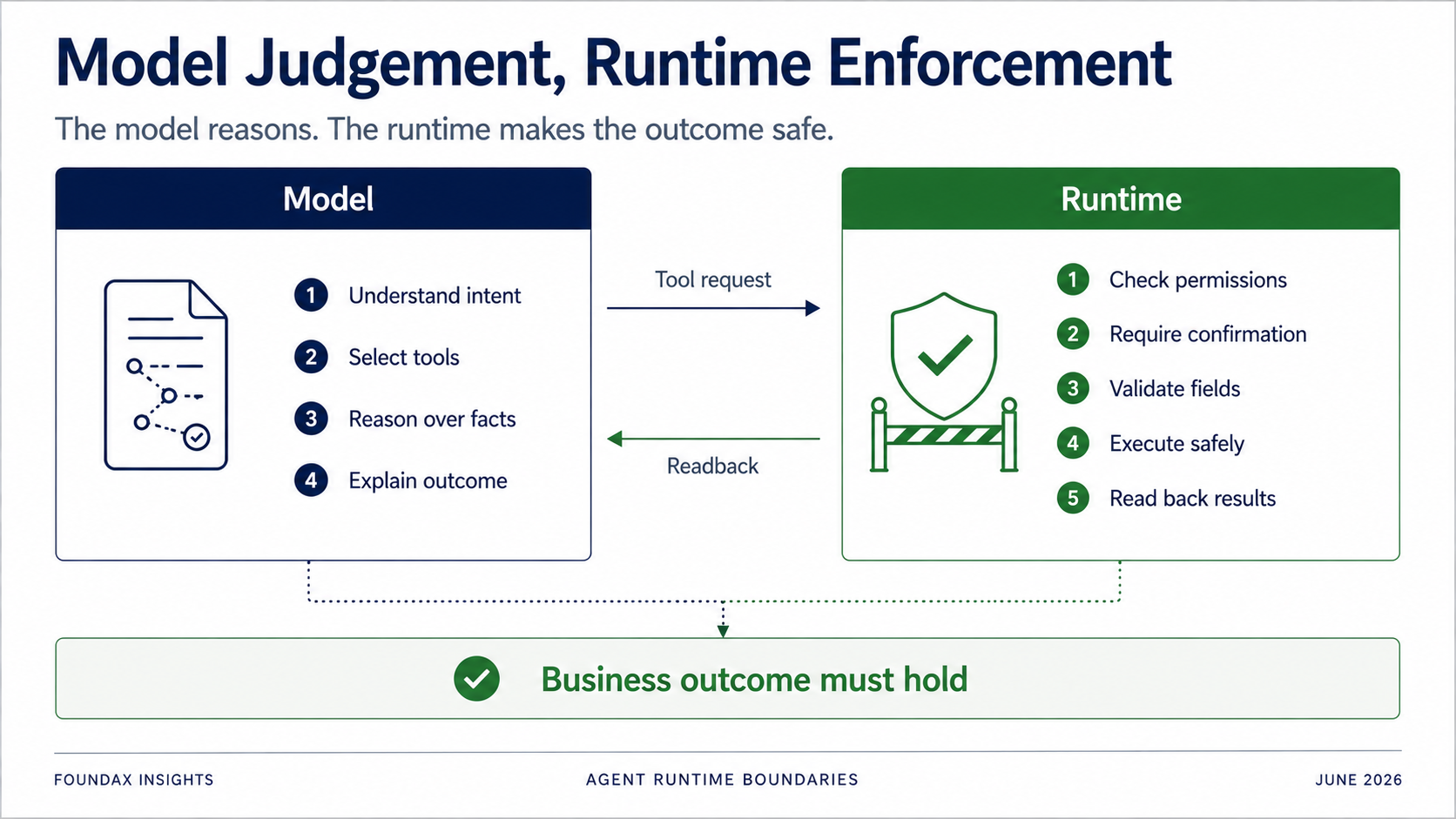
モデルの責任は:理解し、判断し、選択し、説明すること。
runtimeの責任は:権限、確認、フィールド検証、オーナーエグゼキューター境界、実際の実行、readback。
特に書き込み操作について:モデルが自主的にルールに従うことに絶対に依存してはならない。
モデルは「この商品のSEOを更新したい」と言える。
しかしruntimeが判断しなければならない:現在のユーザーに権限はあるか?このアクションは確認を必要とするか?最初にドラフトだけを生成すべきか?フィールドは許可リストにあるか?オブジェクトは現在のマーチャントに属しているか?書き込みは実際に成功したか?readback後、ビジネス状態は本当に目標と一致しているか?
Agentの目標は、ツール呼び出しが成功したことを証明することではない。ビジネス成果が成立していることを証明することだ。
この境界は本質的だ。すべてがモデルに行くわけではなく、すべてがruntimeに行くわけでもない。本当の問題は分業である。
この旅から得た最大の学びは、4.0が決定的に最良のアーキテクチャだということではない。
それは、Agentを構築する際には、現実のエンジニアリング上の懸念の連鎖に流されることが驚くほど容易だということだ。
高頻度タスクがモデルの即興に任せると安定しないのでは?→ 固定workflowを構築しよう。
コンテキストが長すぎてモデルの注意が拡散するのでは?→ ディレクトリ探索を構築しよう。
ツール数の増加でトークンが爆発するのでは?→ runtime検索を構築しよう。
キーワードベースの検索は多言語・クロスドメインタスクに対して脆すぎるのでは?→ embedding、スコアリング、リランキングを検討しよう。
モデルがリストを全部読まずにツールを選んだり、事実が揃う前に回答を出したりするのでは?→ 構造化制約フィールドを追加しよう。
これらの懸念のどれも、想像上のものではない。すべて実際の問題に対応している。
我々はただ——痛い目を見て——多くの解決策が一つの問題を解決する一方で別の問題を持ち込むことを学んだのだ。
固定workflowは安定性を追加したが、モデルの推論に上限をかけた。ディレクトリ探索は正確だが遅く、トークン消費が多かった。runtime検索はコンテキストを節約したが、モデルが必要とするツールをブロックする可能性があった。embeddingは賢く見えたが、LLMネイティブのツール選択においてはおそらく回り道だった。構造化フィールドはモデルを制約できたが、時には自然言語プロンプトの方がうまく機能した。
そしてより決定的な気づき:
これらの問題は実在するが、あなたのプロジェクトにおいて同じ深刻度で現れるとは限らない。
長いコンテキストは実際にあなたのユースケースで注意の拡散を引き起こすか?テストせよ。ツール数は実際にトークンコストを受容不可能にするか?テストせよ。全ツール露出は実際にモデルを怠惰に、パス依存に、エラー傾向にするか?テストせよ。runtime検索は実際にモデルが必要とするツールをブロックするか?それもテストせよ。
Agentアーキテクチャにおける最も犯しやすい誤りは、「誰か他のプロジェクトで実際に存在する問題」を「自分のプロジェクトでも確実に存在する問題」として扱うことだ。
だからAgent構築の第一歩は、起こりうるすべての問題を先回りして防ぐ複雑なアーキテクチャを設計することではない。テストすることだ:
モデルはあなたのドメインで実際に何を理解できるか?ツール説明を読めるか?自力でツールを選択できるか?どこで事実を見落とすか?どの判断をモデルに委ねられるか?どれをruntimeが強制しなければならないか?どのアクションにユーザー確認が必要か?どの結果をreadbackしなければならないか?
これらの問いへの答えが——ブログ記事のリファレンスアーキテクチャではなく——あなたのAgentの設計を決定すべきだ。
Foundaxについては、今では明確だ:Eコマースオペレーションはモデルがよく知っているドメインである。コンバージョンファネル、商品ページ、価格、配送、プロモーション、決済、トラフィック品質、SEO——これらの分析フレームワークは訓練データに無数に現れている。モデルにビジネス分析の本能が欠けているわけではない。欠けているのはFoundaxの特定のシステムの知識だ:どの事実を読めるか、どの書き込みを準備できるか、どのアクションをruntimeが所有しなければならないか、どの結果をreadbackしなければならないか。
だからFoundax Agentの本質は、モデルにEコマース分析の方法を教えることではない。モデルにFoundaxのビジネスケイパビリティを、それが読める言語で手渡すことだ。
ビジネスAgent構築の第一歩は、完璧なアーキテクチャを設計することではない。モデルを実際にどこまで信頼できるのかをテストすることだ。
これらの結論に至ったのは我々だけではない。
2024年12月、Anthropicはガイド「Building Effective Agents」を公開した。その核心メッセージ:シンプルさが勝つ。可能な限り最もシンプルな解決策から始めよ。ツールアクセスを持つ拡張LLMで十分な場合がある。当時読んだときはうなずいただけだった。上記のような経験を経た今、その意味を骨の髄まで理解している。
2026年5月、LangChainはInterruptカンファレンスで注目すべき方向転換を見せた:テーマは「エージェントはプロダクションに行けるか」から「エンタープライズスケールとプロダクションオペレーション」へとシフトした。彼らの資料が強調する本当のボトルネックは、エージェントを書くことではない——スケールでプロダクション管理することだ。
増え続ける研究がこの方向性を補強している。Google DeepMindの2025年のembeddingの限界に関する研究は、固定サイズのベクトル埋め込みがスケールにおいて構造的・関係的情報を失うことを数学的に示した——embeddingベースのツール検索を検討している者にとっては直接的に関連する内容だ。Neo4jの「コンテキストエンジニアリング」という概念は、信頼できるAIは巧妙なプロンプトの言い回しではなく、アーキテクチャから生まれると論じている。
我々の経験は、業界全体で見られる方向性と一致している:Anthropicのシンプル/コンポーザブルパターン、LangChainのフレームワーク抽象化よりもプロダクションオペレーションを重視する姿勢。既製のスキャフォールディングを減らし、モデルの直接的な能力を増やす——ただし常に実際の使用で検証し、教義として採用しない。事前フィルタリングを減らし、モデルの判断を増やす。問うべきは「モデルの周りに完璧なアーキテクチャをどう構築するか」ではない。「モデルが実際に必要とするものをどう与え、その道をどう妨げないか」だ。
これはFoundaxの結論を普遍的たらしめるものではない。異なるビジネス、異なるモデル、異なるツールサーフェスは異なる答えに至るだろう。普遍的なのは方法論だ:最初にテストし、その後に設計せよ。
Q: これはすべてのツールを常にモデルに露出すべきという意味ですか?
いいえ。ツール数、モデル、コンテキストバジェット、ドメインによって異なります。ポイントは「常にすべてを露出せよ」ではありません。ポイントは:フィルタリングする前にテストせよ、です。モデルが処理できないと仮定するのではなく——検証せよ。我々のケースでは、タスクあたり十数個の圧縮されたツールシグネチャが管理可能で効果的でした。あなたの数字は異なるかもしれません。
Q: どのような場合に固定workflowを使うべきですか?
タスクが本当に決定的で、エラーのリスクが壊滅的で、そのドメインにおけるモデルの背景知識が弱い場合です。workflowが間違っているわけではありません——モデルができたはずの推論を置き換えるときに間違っているのです。安全ガードレールや決定的なポストプロセッシングに使用し、モデルの判断の代用品として使わないでください。
Q: 言語化カタログとAPIスキーマの違いは何ですか?
言語化カタログは、ツールが何をできるかを圧縮された自然言語でモデルに伝えます——例:「Read: [12] 商品バリアント — SKU / 価格 / 在庫 / 販売可否ステータス」。APIスキーマは、ツールの呼び出し方法を完全なパラメータ仕様、列挙、制約とともにモデルに伝えます。モデルに必要なのはケイパビリティメニューです。runtimeに必要なのは技術マニュアルです。この二つを混ぜることは、最もコストのかかるミスの一つです。
Q: モデルとruntimeのどちらに何を任せるか、どう判断しますか?
良いヒューリスティック:モデルは理解、判断、選択、説明を担当する。runtimeは権限、実行、確認、検証、readbackを担当する。モデルにルールの強制を求めているなら、線の間違った側にいます。モデルは提案し、runtimeが決定し実行する。
Q: コストはどうですか?より多くのツールを露出するとトークン使用量は増えませんか?
我々のケースでは、圧縮された言語化カタログは実際には複数ラウンドのディレクトリ探索や検索チェインよりも安価でした。各ツールエントリは千数百文字程度です。タスクあたり十数個のツールを露出すると、合計で約一万〜二万字——約四千〜五千トークンです。これを複数ラウンドの意図分解、検索、候補レビュー、再選択と比較してみてください。シンプルなアプローチの方が、トークン効率が良い場合が多かったのです。
Q: このプロセスから得た最も重要な単一の洞察は何ですか?
「モデルを助けること」と「モデルを制約すること」は、設計者の視点からは同一に見えるが、システムに対しては正反対の効果を持つということです。我々が構築したすべてのアーキテクチャは、助けることを意図していた。そのほとんどが、結果的に制約することになった。その違いはテストを通じてのみ明らかになった。この記事から一つだけ持ち帰るとすれば、これにしてください:モデルが実際に何をできるかをテストしてから、できないと仮定したことを補償するアーキテクチャを設計し始めよ。